") NVIDIA Spectrum X如何推動(dòng)英偉達(dá)網(wǎng)絡(luò)業(yè)務(wù)實(shí)現(xiàn)31億美元收入
NVIDIA Spectrum X如何推動(dòng)英偉達(dá)網(wǎng)絡(luò)業(yè)務(wù)實(shí)現(xiàn)31億美元收入

英偉達(dá)數(shù)據(jù)中心收入繼續(xù)擴(kuò)大
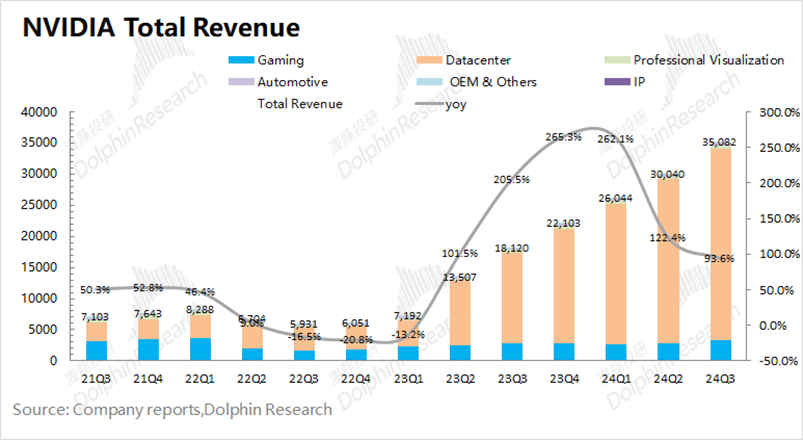
北京時(shí)間11月21日凌晨,英偉達(dá)發(fā)布本季度財(cái)報(bào),公司實(shí)現(xiàn)營收350.8億美元,同比增長93.6%,好于彭博一致預(yù)期(332億美元)。公司收入增長,主要受數(shù)據(jù)中心業(yè)務(wù)需求增長的帶動(dòng)。在AI等需求的帶動(dòng)下,2025財(cái)年第三季度英偉達(dá)的數(shù)據(jù)中心業(yè)務(wù)在公司收入中的份額繼續(xù)擴(kuò)大,本季度達(dá)到了87.7%。
(Source:海豚投研)
細(xì)分來看,數(shù)據(jù)中心業(yè)務(wù)中計(jì)算收入為276億美元,同比增長132%;網(wǎng)絡(luò)收入為31億美元,同比增長20%,這得益于益于Ethernet for AI,其中包括Spectrum X端到端以太網(wǎng)平臺(tái)。據(jù)統(tǒng)計(jì),AI網(wǎng)絡(luò)NVIDIA Spectrum-X以太網(wǎng)AI收入同比增長超過3倍。
就在不久前,AI網(wǎng)絡(luò)產(chǎn)業(yè)剛爆出了一項(xiàng)大新聞。馬斯克僅用了122天就塑造了xAI 位于田納西州孟菲斯市的 Colossus 超級(jí)計(jì)算機(jī)集群,該集群使用10萬張NVIDIA Hopper GPU加速卡,超過1500個(gè)GPU機(jī)架,堪稱全球最大AI超級(jí)計(jì)算機(jī)集群。
實(shí)際上,該集群使用了 NVIDIA Spectrum-X 以太網(wǎng)網(wǎng)絡(luò)平臺(tái),該平臺(tái)是專為多租戶、超大規(guī)模的 AI 工廠提供卓越性能而設(shè)計(jì)的 RDMA網(wǎng)絡(luò)而并不是InfiniBand網(wǎng)絡(luò)。
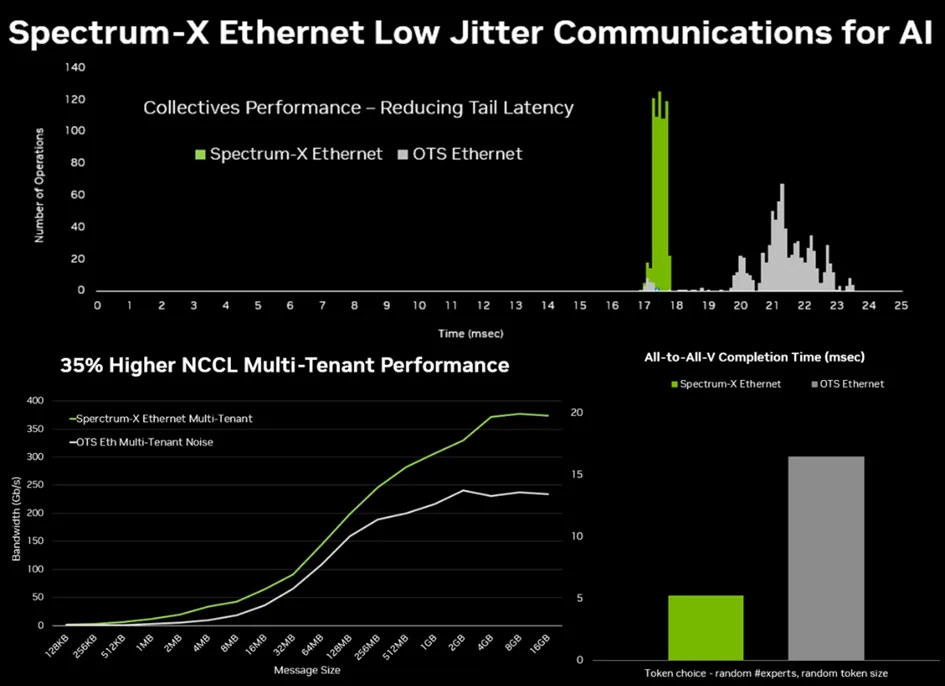
NVIDIA聲稱專門面向 AI 的 Spectrum-X 以太網(wǎng)網(wǎng)絡(luò)具有先進(jìn)的功能,可在提供高效、可擴(kuò)展的帶寬的同時(shí),實(shí)現(xiàn)低延遲和短尾延遲,而這些功能之前是 InfiniBand 網(wǎng)絡(luò)所獨(dú)有的。
NVIDIA基于 AI 的 Spectrum-X 以太網(wǎng)系統(tǒng)是一整套AI Networking的全家桶組合包括需要購買Spectrum-X交換機(jī)、Bluefield SuperNIC以及相關(guān)光模塊及線纜組件。
基于以太網(wǎng)的Spectrum-X特性
我們根據(jù)超大以太網(wǎng)集群所面臨的通信挑戰(zhàn)來了解下基于以太網(wǎng)的Spectrum-X方案如何優(yōu)化基于以太網(wǎng)的RDMA功能。
部分內(nèi)容結(jié)合Nvidia AI Networking Whitepaper 編譯
基于以太網(wǎng)的NVIDIA Spectrum-X:專為生成式AI時(shí)代設(shè)計(jì)
AI云作為支持生成式AI工作負(fù)載的新型數(shù)據(jù)中心類別,正日益受到業(yè)界的關(guān)注。這類數(shù)據(jù)中心不僅繼承了傳統(tǒng)云的核心功能,如多租戶支持、安全性保障和多樣化的工作負(fù)載支撐,更在支持更大規(guī)模的生成式AI應(yīng)用方面展現(xiàn)出卓越能力。生成式AI是一類基于訓(xùn)練數(shù)據(jù)生成新輸出的人工智能算法,其以圖像、文本、音頻等多種形式創(chuàng)造全新內(nèi)容,與旨在識(shí)別模式和進(jìn)行預(yù)測的傳統(tǒng)人工智能系統(tǒng)形成鮮明對(duì)比。 NVIDIA Spectrum-X構(gòu)建了以太網(wǎng)多租戶、超大規(guī)模AI云而精心設(shè)計(jì)的革命性解決方案,它完美契合了生成式AI時(shí)代的發(fā)展需求。
無損網(wǎng)絡(luò)與RDMA
在有損網(wǎng)絡(luò)環(huán)境中,數(shù)據(jù)傳輸過程中面臨著丟失或質(zhì)量下降的風(fēng)險(xiǎn)。這種網(wǎng)絡(luò)傾向于優(yōu)先考慮數(shù)據(jù)傳輸?shù)乃俣榷菧?zhǔn)確性。然而,對(duì)于AI應(yīng)用而言,丟包導(dǎo)致的后果可能是災(zāi)難性的,包括性能下降、GPU資源的空閑浪費(fèi)以及功耗的額外開銷。
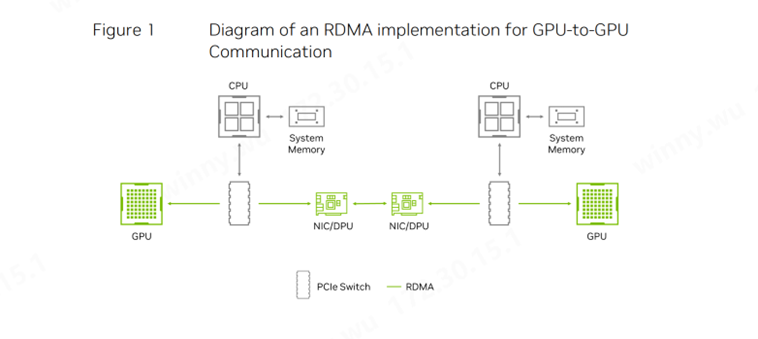
圖1:GPU-GPU的RDMA通信實(shí)現(xiàn)示意圖
無損網(wǎng)絡(luò)則完全改變了這一局面。在這種網(wǎng)絡(luò)中,數(shù)據(jù)傳輸?shù)耐暾缘玫絿?yán)格保障,所有數(shù)據(jù)包都能夠準(zhǔn)確無誤地到達(dá)目的地。盡管以太網(wǎng)最初的設(shè)計(jì)確實(shí)允許一定的丟包率,但在InfiniBand網(wǎng)絡(luò)中,無損是基本要求。
隨著GPU計(jì)算和大規(guī)模AI應(yīng)用場景在云環(huán)境中的廣泛應(yīng)用,以太網(wǎng)也通過采用RoCE(RDMA over Converged Ethernet)和基于優(yōu)先級(jí)的流量控制(PFC,Priority Flow Control)等技術(shù),結(jié)合無損網(wǎng)絡(luò)的實(shí)現(xiàn),使用NVIDIA Spectrum-X,為AI應(yīng)用提供了更加可靠和高效的解決方案。 遠(yuǎn)程直接內(nèi)存訪問(RDMA,Remote Direct Memory Access)技術(shù)的出現(xiàn),進(jìn)一步提升了網(wǎng)絡(luò)傳輸?shù)男省K试S數(shù)據(jù)在遠(yuǎn)程系統(tǒng)、GPU和存儲(chǔ)器之間直接傳輸,無需經(jīng)過CPU的干預(yù)。傳統(tǒng)的網(wǎng)絡(luò)傳輸方式涉及多個(gè)復(fù)雜的步驟,包括數(shù)據(jù)的復(fù)制、網(wǎng)絡(luò)發(fā)送以及接收方的多步驟處理。而RDMA則直接跨越了這些繁瑣的中間環(huán)節(jié),實(shí)現(xiàn)了數(shù)據(jù)的高效傳輸。我們?cè)谥暗腒iwi Talks有敘述過目前RDMA面對(duì)大規(guī)模集群存在的問題及建議。
挑戰(zhàn)與方案1:自適應(yīng)路由、多路徑與數(shù)據(jù)包噴灑
傳統(tǒng)數(shù)據(jù)中心的應(yīng)用程序通常會(huì)產(chǎn)生大量的小數(shù)據(jù)流,這使得網(wǎng)絡(luò)流量的統(tǒng)計(jì)平均值能夠反映整體情況。在這種背景下,基于簡單靜態(tài)哈希的路由算法,如等價(jià)多路徑(ECMP,Equal Cost Multi-Path),足以應(yīng)對(duì)常見的網(wǎng)絡(luò)流量問題。
然而,人工智能工作負(fù)載的特性卻截然不同。它們通常會(huì)產(chǎn)生少量的大數(shù)據(jù)流,被稱為“大象流”(elephant flows)。這些大象流會(huì)占用大量的鏈路帶寬,如果多個(gè)大象流被路由到同一鏈路,就會(huì)導(dǎo)致嚴(yán)重的擁塞和高延遲。在人工智能應(yīng)用中,即使是在非阻塞拓?fù)渲惺褂肊CMP,大象流之間的碰撞幾率也非常高。由于AI作業(yè)的性能高度依賴于最壞情況下的表現(xiàn),這些碰撞會(huì)導(dǎo)致模型訓(xùn)練時(shí)間既超出預(yù)期又變得極為不穩(wěn)定。
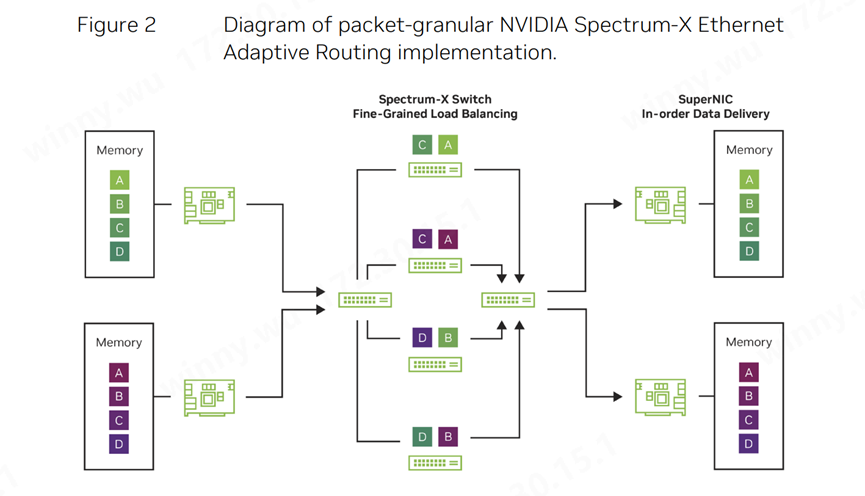
圖2:NVIDIA:Spectrum-X以太網(wǎng)自適應(yīng)路由的細(xì)粒度數(shù)據(jù)包示意圖
因此,NVIDIA引入自適應(yīng)路由算法來動(dòng)態(tài)平衡網(wǎng)絡(luò)中的數(shù)據(jù)傳輸。此外,路由的精細(xì)度也至關(guān)重要,以避免大象流之間的碰撞。即使按流量進(jìn)行路由,仍然存在擁塞的可能性。然而,當(dāng)采用數(shù)據(jù)包噴灑(Packet Spraying)技術(shù),即按每個(gè)數(shù)據(jù)包進(jìn)行路由時(shí),數(shù)據(jù)包可能會(huì)以無序的方式到達(dá)目的地。為了實(shí)現(xiàn)數(shù)據(jù)包粒度的自適應(yīng)路由,我們需要建立靈活的重新排序機(jī)制,確保自適應(yīng)路由對(duì)應(yīng)用程序來說是透明的。
挑戰(zhàn)與方案2:擁塞控制
在繁忙的多租戶AI云環(huán)境中,不同AI作業(yè)并行運(yùn)行時(shí),網(wǎng)絡(luò)擁塞問題往往難以避免。尤其是當(dāng)大量發(fā)送方試圖向單一目的地或不同目的地(這些目的地可能已受到其它應(yīng)用背景流量的影響)傳輸數(shù)據(jù)時(shí),網(wǎng)絡(luò)擁塞現(xiàn)象尤為顯著。這種擁塞不僅會(huì)導(dǎo)致延遲飆升和有效帶寬急劇縮減,還可能引發(fā)網(wǎng)絡(luò)“熱點(diǎn)”的擴(kuò)散,造成相鄰租戶的相互干擾,即受害者效應(yīng)。
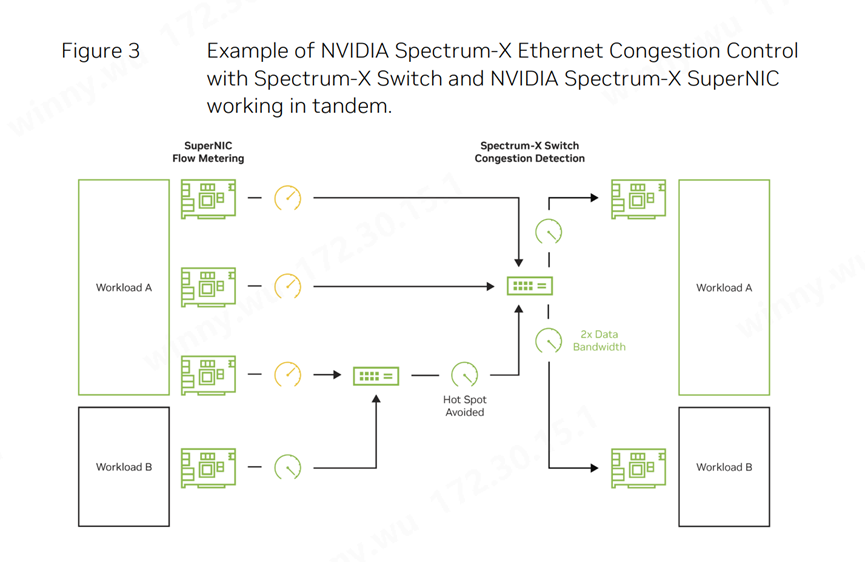
圖3:NVIDIA:Spectrum-X以太網(wǎng)擁塞控制與交換機(jī)和NVIDIA BlueField SuperNIC協(xié)同工作
傳統(tǒng)的擁塞控制方法,如顯式擁塞通知(ECN,Explicit Congestion Notification),在支持生成式AI的以太網(wǎng)環(huán)境中顯得捉襟見肘。為了有效緩解擁塞,負(fù)責(zé)數(shù)據(jù)傳輸?shù)木W(wǎng)絡(luò)設(shè)備(如NIC或DPU)必須進(jìn)行精確的流量控制。然而,ECN機(jī)制在交換機(jī)緩沖區(qū)接近滿載時(shí)才開始發(fā)揮作用,此時(shí)接收方會(huì)通知發(fā)送方限制其發(fā)送速率。但在大規(guī)模AI模型常見的突發(fā)流量場景下,這種延遲的擁塞反饋可能導(dǎo)致緩沖區(qū)迅速填滿,進(jìn)而引發(fā)丟包問題。盡管深度緩沖交換機(jī)能夠降低緩沖區(qū)溢出的風(fēng)險(xiǎn),但它們引入的額外延遲卻削弱了擁塞控制的初衷。
實(shí)現(xiàn)高效的擁塞控制需要交換機(jī)與網(wǎng)卡NIC之間的緊密協(xié)作。NVIDIA Spectrum-X通過利用Spectrum-4交換機(jī)的帶內(nèi)、硬件加速的遙測數(shù)據(jù),為BlueField-3 SuperNIC提供實(shí)時(shí)的流量計(jì)量信息。
挑戰(zhàn)與方案3:性能隔離與安全性多租戶環(huán)境如AI云,必須確保各個(gè)作業(yè)之間的性能隔離,以免受到其它作業(yè)的網(wǎng)絡(luò)流量干擾。遺憾的是,許多以太網(wǎng)ASIC設(shè)計(jì)在性能隔離方面考慮不足。這導(dǎo)致某些作業(yè)在面臨“近鄰干擾”(noisy neighbor)(即向同一端口發(fā)送流量的相鄰作業(yè))時(shí),其有效帶寬可能會(huì)急劇下降。 以太網(wǎng)網(wǎng)絡(luò)在設(shè)計(jì)時(shí)還需考慮網(wǎng)絡(luò)公平性。AI云應(yīng)支持多種異構(gòu)應(yīng)用程序的混合運(yùn)行。由于不同應(yīng)用程序可能使用不同大小的數(shù)據(jù)幀,如果沒有適當(dāng)?shù)母綦x優(yōu)化措施,大數(shù)據(jù)幀可能會(huì)占用過多的帶寬資源,導(dǎo)致小數(shù)據(jù)幀傳輸受阻。
實(shí)現(xiàn)性能隔離和防止“近鄰干擾”的關(guān)鍵在于采用共享數(shù)據(jù)包緩沖區(qū)。通過為所有作業(yè)提供平等的緩存訪問權(quán)限,共享緩沖區(qū)能夠確保混合AI云工作負(fù)載的穩(wěn)定性和低延遲。
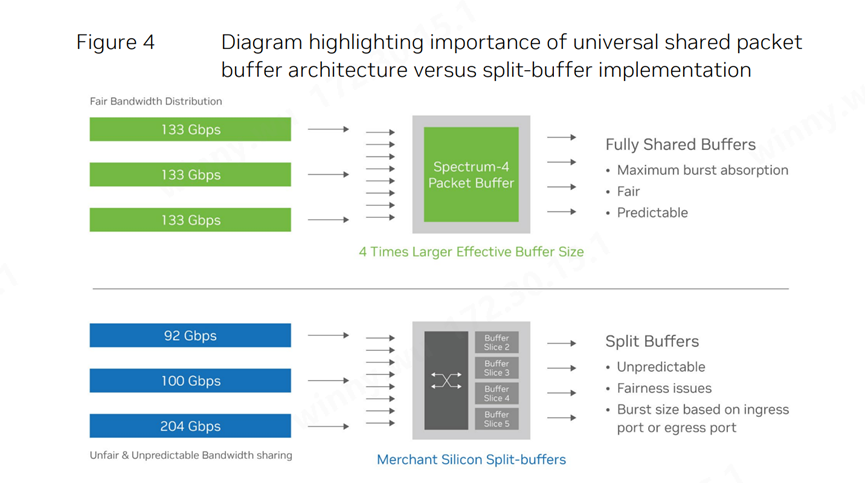
圖4:強(qiáng)調(diào)通用共享數(shù)據(jù)包緩沖區(qū)架構(gòu)與分割緩沖區(qū)實(shí)現(xiàn)之間重要性
除了從帶寬角度考慮性能隔離外,我們還應(yīng)認(rèn)識(shí)到性能隔離與零信任架構(gòu)對(duì)于多租戶環(huán)境網(wǎng)絡(luò)安全的重要性。數(shù)據(jù)無論是在靜止?fàn)顟B(tài)還是傳輸過程中,都需要得到嚴(yán)格的保護(hù)。高效的加密和認(rèn)證工具能夠在不犧牲性能的前提下提供強(qiáng)大的安全保障。BlueField-3 DPU集成了安全引導(dǎo)功能,為基于硬件的信任根提供了堅(jiān)實(shí)基礎(chǔ),并支持MACsec和IPsec等協(xié)議用于數(shù)據(jù)加密,以及AES-XTS 256/512等加密算法用于靜態(tài)數(shù)據(jù)的保護(hù)。
以上是英偉達(dá)對(duì)基于以太網(wǎng)Spectrum-X解決方案的部分優(yōu)勢特性總結(jié);
UEC 超以太聯(lián)盟對(duì)標(biāo) NVIDIA Spectrum
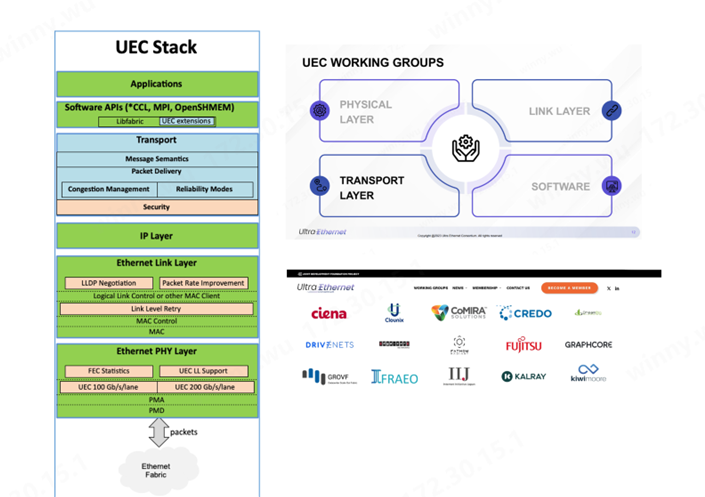
我們已經(jīng)了解UEC是專門為AI網(wǎng)絡(luò)Scale -out互聯(lián)成立的國際聯(lián)盟,目的是全面優(yōu)化RDMA的功能,從而實(shí)現(xiàn)更大規(guī)模的AI網(wǎng)絡(luò)集群的高效運(yùn)作。
UEC 主要在Transport Layer傳輸層做了全面的優(yōu)化,不限于消息語義優(yōu)化、數(shù)據(jù)包傳輸、擁塞控制及可靠性安全性等目前大規(guī)模集群擴(kuò)展需要優(yōu)化的功能。
UEC支持自適應(yīng)路由及數(shù)據(jù)包噴灑
超以太聯(lián)盟下一代的Modernized RDMA將支持多路徑傳輸?shù)臄?shù)據(jù)包噴灑技術(shù),從而優(yōu)化自適應(yīng)路由。UEC支持了RUD,UET就可以將同一個(gè)流的不同包分散到多個(gè)路徑上同時(shí)傳輸,實(shí)現(xiàn)包噴灑功能。這讓交換機(jī)可以充分發(fā)揮ECMP甚至WCMP(Weighted Cost Multi- Pathing)路由能力,將去往同一目的地的數(shù)據(jù)包通過多條路徑發(fā)送,大幅度提高網(wǎng)絡(luò)利用率。
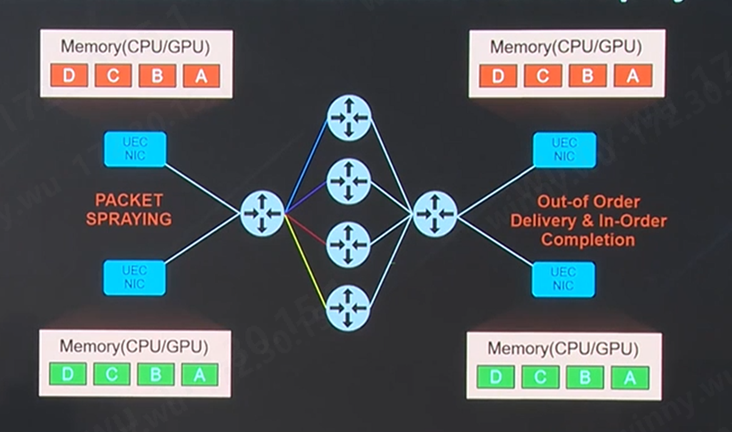
(來源:AMD)
UEC將支持端到端遙測Telemetry
新的UEC對(duì)于擁塞做出了優(yōu)化機(jī)制:來自網(wǎng)絡(luò)的擁塞信息可以向參與者提供擁塞的位置和原因。縮短擁塞信號(hào)路徑并向端點(diǎn)提供更多信息,能夠?qū)崿F(xiàn)更快速的擁塞控制。無論是發(fā)送方還是接收方安排傳輸,現(xiàn)代交換機(jī)都可以通過快速傳遞準(zhǔn)確的擁塞信息給調(diào)度器或起搏器pacer,促進(jìn)響應(yīng)式的擁塞控制,從而提高擁塞控制算法的響應(yīng)速度和準(zhǔn)確性。結(jié)果是減少了擁塞、降低了丟包率和縮短了隊(duì)列長度——所有這些為改善尾部延遲提供了服務(wù)。
UEC支持安全性與加密
UEC傳輸協(xié)議從設(shè)計(jì)之初就融入了網(wǎng)絡(luò)安全概念,能夠加密并驗(yàn)證AI訓(xùn)練或推理作業(yè)中計(jì)算端點(diǎn)間發(fā)送的所有網(wǎng)絡(luò)流量。UEC傳輸協(xié)議借鑒了現(xiàn)代加密方法(如IPSec和PSP)中用于高效會(huì)話管理、認(rèn)證和保密的核心技術(shù)。隨著作業(yè)規(guī)模的擴(kuò)大,必須在不使主機(jī)和網(wǎng)絡(luò)接口的會(huì)話狀態(tài)急劇膨脹的前提下支持加密。為此,UET(UEC傳輸)引入了新的密鑰管理機(jī)制,允許成千上萬個(gè)參與同一作業(yè)的計(jì)算節(jié)點(diǎn)之間高效共享密鑰。它被設(shè)計(jì)成能在AI訓(xùn)練和推理所要求的高速和大規(guī)模下高效實(shí)現(xiàn)。托管在大型以太網(wǎng)網(wǎng)絡(luò)上的高性能計(jì)算(HPC)作業(yè)具有類似的特征,同樣需要相當(dāng)?shù)陌踩珯C(jī)制。這意味著UEC傳輸不僅能滿足AI領(lǐng)域的需求,也能適應(yīng)HPC環(huán)境中對(duì)于安全性和性能的嚴(yán)格要求,確保數(shù)據(jù)在大規(guī)模網(wǎng)絡(luò)中的傳輸既高效又安全。

UEC成員Arista公司表示,“當(dāng)PCI總線因主機(jī)CPU上的競爭工作負(fù)載或降速等原因出現(xiàn)擁塞時(shí),通常需要使用ECN(顯式擁塞通知)標(biāo)記。Arista在實(shí)現(xiàn)ECN標(biāo)記方面經(jīng)驗(yàn)豐富,可以對(duì)經(jīng)過擁塞隊(duì)列的數(shù)據(jù)包進(jìn)行標(biāo)記。此外,該公司還支持即將推出的多種網(wǎng)絡(luò)內(nèi)遙測(In-Network Telemetry)技術(shù),它們能提供更細(xì)粒度的網(wǎng)絡(luò)擁塞隊(duì)列深度信息,從而全面支持網(wǎng)絡(luò)內(nèi)遙測。這項(xiàng)新技術(shù)預(yù)計(jì)將與超以太網(wǎng)的網(wǎng)卡和未來的RDMA一起發(fā)揮更大作用。”
-
數(shù)據(jù)中心
+關(guān)注
關(guān)注
18文章
5734瀏覽量
75179 -
AI
+關(guān)注
關(guān)注
91文章
40746瀏覽量
302390 -
英偉達(dá)
+關(guān)注
關(guān)注
23文章
4112瀏覽量
99569
原文標(biāo)題:AI網(wǎng)絡(luò)熱點(diǎn) | NVIDIA Spectrum X如何推動(dòng)英偉達(dá)網(wǎng)絡(luò)業(yè)務(wù)實(shí)現(xiàn)31億美元收入
文章出處:【微信號(hào):奇異摩爾,微信公眾號(hào):奇異摩爾】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
狂攬430億凈利!英偉達(dá)Q4炸裂財(cái)報(bào):數(shù)據(jù)中心獨(dú)吞90%營收

AI不是泡沫,是訂單!英偉達(dá)Q3業(yè)績超預(yù)期,數(shù)據(jù)中心營收超512億美元
英偉達(dá)5萬億市值背后,是一場賭上未來的燒錢競賽

硅光成AI勝負(fù)手?英偉達(dá)20億美元戰(zhàn)略投資Marvell
NVIDIA Spectrum-X以太網(wǎng)硅光技術(shù)助力AI工廠網(wǎng)絡(luò)創(chuàng)新
英偉達(dá) Q3 狂攬 308 億
黃仁勛:英偉達(dá)AI芯片訂單排到2026年 英偉達(dá)上季營收加速增長62%再超預(yù)期
今日看點(diǎn):英偉達(dá)三季度營收達(dá)570億美元,云 GPU 已售罄;蔚來智駕芯片被曝首次技術(shù)外供
NVIDIA新聞:英偉達(dá)10億美元入股諾基亞 英偉達(dá)推出全新量子設(shè)備
NVIDIA Spectrum-X 以太網(wǎng)交換機(jī)助力 Meta 和 Oracle 加速網(wǎng)絡(luò)性能

今日看點(diǎn):蘋果認(rèn)證中國快充品牌遭美調(diào)查;英偉達(dá)擬向OpenAI投資最高1000億美元
英偉達(dá)斥資50億美元入股英特爾,芯片巨頭攜手重塑行業(yè)格局
安森美攜手英偉達(dá)推動(dòng)下一代AI數(shù)據(jù)中心發(fā)展
英偉達(dá)2026財(cái)年Q1營收公布 一季度營收441億美元 英偉達(dá)Q1凈利潤187.8億美元
從游戲到智能駕駛,英偉達(dá)有哪些技術(shù)升級(jí)?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論