") NPU技術如何提升AI性能
NPU技術如何提升AI性能

隨著人工智能技術的飛速發(fā)展,深度學習作為AI領域的核心驅動力,對計算能力的需求日益增長。NPU技術應運而生,為AI性能的提升提供了強大的硬件支持。
NPU技術概述
NPU是一種專門為深度學習算法設計的處理器,與傳統(tǒng)的CPU和GPU相比,它在執(zhí)行深度學習任務時具有更高的效率和更低的能耗。NPU通過專門優(yōu)化的硬件結構和指令集,能夠更快地處理神經(jīng)網(wǎng)絡中的大量并行計算任務。
1. 優(yōu)化硬件架構
NPU技術通過優(yōu)化硬件架構來提升AI性能。以下是幾個關鍵點:
- 專用計算單元 :NPU包含大量專用的計算單元,這些單元專為深度學習中的矩陣運算和數(shù)據(jù)并行處理設計,能夠高效執(zhí)行這些操作。
- 內(nèi)存層次結構 :NPU通常具有優(yōu)化的內(nèi)存層次結構,包括高速緩存和片上存儲,以減少數(shù)據(jù)訪問延遲,提高數(shù)據(jù)處理速度。
- 并行處理能力 :NPU支持大規(guī)模并行處理,這意味著它可以同時處理多個深度學習任務,從而提高整體的計算效率。
2. 提高能效比
NPU技術通過提高能效比來提升AI性能。以下是幾個關鍵點:
- 低功耗設計 :NPU采用低功耗設計,通過優(yōu)化電路和使用先進的制程技術,減少能耗。
- 動態(tài)調(diào)整頻率和電壓 :NPU可以根據(jù)工作負載動態(tài)調(diào)整頻率和電壓,以實現(xiàn)最佳的能效比。
- 專用指令集 :NPU擁有專用的指令集,這些指令集針對深度學習算法進行了優(yōu)化,減少了不必要的計算和能量消耗。
3. 加速數(shù)據(jù)處理
NPU技術通過加速數(shù)據(jù)處理來提升AI性能。以下是幾個關鍵點:
- 數(shù)據(jù)預處理 :NPU可以加速數(shù)據(jù)預處理步驟,如歸一化和特征提取,這些步驟對于深度學習模型的訓練和推理至關重要。
- 批量處理 :NPU支持批量處理,這意味著它可以同時處理多個數(shù)據(jù)樣本,從而提高吞吐量。
- 異構計算 :NPU可以與其他類型的處理器(如CPU和GPU)協(xié)同工作,實現(xiàn)異構計算,以充分利用不同處理器的優(yōu)勢。
4. 支持多種深度學習框架
NPU技術通過支持多種深度學習框架來提升AI性能。以下是幾個關鍵點:
- 框架兼容性 :NPU支持主流的深度學習框架,如TensorFlow、PyTorch等,使得開發(fā)者可以無縫遷移現(xiàn)有的模型和算法。
- 自動優(yōu)化 :NPU可以自動優(yōu)化深度學習模型的執(zhí)行,通過分析模型結構和數(shù)據(jù)流,動態(tài)調(diào)整計算資源。
- 硬件抽象層 :NPU提供了硬件抽象層,使得開發(fā)者可以專注于算法開發(fā),而不必關心底層硬件細節(jié)。
5. 實時AI應用
NPU技術通過支持實時AI應用來提升AI性能。以下是幾個關鍵點:
- 低延遲 :NPU可以實現(xiàn)低延遲的AI推理,這對于需要快速響應的應用(如自動駕駛、實時語音識別)至關重要。
- 高吞吐量 :NPU的高吞吐量使得它可以同時處理大量AI任務,滿足高并發(fā)的需求。
- 邊緣計算 :NPU適合部署在邊緣設備上,實現(xiàn)數(shù)據(jù)的本地處理,減少對云端的依賴,降低延遲。
結論
NPU技術通過優(yōu)化硬件架構、提高能效比、加速數(shù)據(jù)處理、支持多種深度學習框架和支持實時AI應用等方面,顯著提升了AI性能。隨著技術的不斷進步,NPU將繼續(xù)在AI領域扮演越來越重要的角色,推動人工智能技術的發(fā)展。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
處理器
+關注
關注
68文章
20250瀏覽量
252211 -
AI
+關注
關注
91文章
39755瀏覽量
301361 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265291 -
NPU
+關注
關注
2文章
373瀏覽量
21088
發(fā)布評論請先 登錄
相關推薦
熱點推薦
使用NORDIC AI的好處
提升能效,適合音頻、圖像和高采樣率傳感器等更重的 AI 負載。[Axon NPU 技術頁]
模型更小、更快、更省電
Neuton 模型相較 TensorFlow Lite:* 內(nèi)存
發(fā)表于 01-31 23:16
【新品發(fā)布】艾為重磅發(fā)布端側AI高性能NPU語音芯片,打造智能語音體驗新標桿
數(shù)模龍頭艾為電子全新推出高性能NPU神經(jīng)網(wǎng)絡智能語音處理芯片:AWA89601,集成音頻專用NPU(神經(jīng)網(wǎng)絡處理器),通過聲音模型訓練與NPU硬件結合,該芯片在

別再用舊款了!RV1126B NPU實測2.6倍提速,YOLO算法絲滑運行
AI視覺芯片的核心競爭力,NPU性能尤為關鍵。瑞芯微RV1126B作為RV1126迭代款,性能提升有多少?繼上集CPU

瑞芯微SOC智能視覺AI處理器
。B2版本通常在功耗、穩(wěn)定性和部分外圍接口支持上有所優(yōu)化。NPU: 集成0.8 TOPS的NPU,支持INT8/INT16混合運算,能滿足大多數(shù)邊緣側的輕量級AI推理需求(如分類、檢測、識別)。多媒體
發(fā)表于 12-19 13:44
安謀科技:端側NPU技術創(chuàng)新,拉動AI算力落地引擎
X3 NPU IP以及生態(tài)建設、NPU發(fā)展趨勢等話題。 ? 圖:安謀科技產(chǎn)品總監(jiān)鮑敏祺 ? 周易X3 NPU IP正當時 ? 安謀科技周易X3 NPU IP面向端側

【RK3568 NPU實戰(zhàn)】別再閑置你的NPU!手把手帶你用迅為資料跑通Android AI檢測Demo,附完整流程與效果
【RK3568 NPU實戰(zhàn)】別再閑置你的NPU!手把手帶你用迅為資料跑通Android AI檢測Demo,附完整流程與效果

如何利用NPU與模型壓縮技術優(yōu)化邊緣AI
隨著人工智能模型從設計階段走向實際部署,工程師面臨著雙重挑戰(zhàn):在計算能力和內(nèi)存受限的嵌入式設備上實現(xiàn)實時性能。神經(jīng)處理單元(NPU)作為強大的硬件解決方案,擅長處理 AI 模型密集的計算需求。然而
實戰(zhàn)RK3568性能調(diào)優(yōu):如何利用迅為資料壓榨NPU潛能-在Android系統(tǒng)中使用NPU
《實戰(zhàn)RK3568性能調(diào)優(yōu):如何利用迅為資料壓榨NPU潛能-在Android系統(tǒng)中使用NPU》

AI體驗躍遷,天璣9500用雙NPU開創(chuàng)端側AI新時代
架構,從底層解決性能與功耗的矛盾:超性能 NPU 990 性能大幅提升,生成式 AI 引擎 2

工業(yè)“MCU+AI”技術發(fā)展的核心要點
? 一、AI功能實現(xiàn)方式 ? ? Arm Helium?技術 ? ? 特點 ?:提升DSP和機器學習性能(最高達4倍),降低實時負載。 ? 代表產(chǎn)品 ?: 瑞薩RA8x1(Cortex
DevEco Studio AI輔助開發(fā)工具兩大升級功能 鴻蒙應用開發(fā)效率再提升
HarmonyOS應用的AI智能輔助開發(fā)助手——CodeGenie,該AI助手深度集成在DevEco Studio中,提供鴻蒙知識智能問答、鴻蒙ArkTS代碼補全/生成和萬能卡片生成等功能,提升了開發(fā)效率,深受廣大
發(fā)表于 04-18 14:43
RK3588核心板在邊緣AI計算中的顛覆性優(yōu)勢與場景落地
與低功耗。相比傳統(tǒng)四核A72方案(如RK3399),單線程性能提升80%,多線程任務處理能力翻倍。
6TOPS獨立NPU:
支持INT8/INT16混合精度計算,可直接部署YOLOv5
發(fā)表于 04-15 10:48
首創(chuàng)開源架構,天璣AI開發(fā)套件讓端側AI模型接入得心應手
的端側部署,Token產(chǎn)生速度提升了40%,讓端側大模型擁有更高的計算效率和推理性能,使端側AI交互響應更及時,用戶體驗更貼心。
聯(lián)發(fā)科還與vivo和全民K歌攜手,借助天璣AI人聲萃
發(fā)表于 04-13 19:52
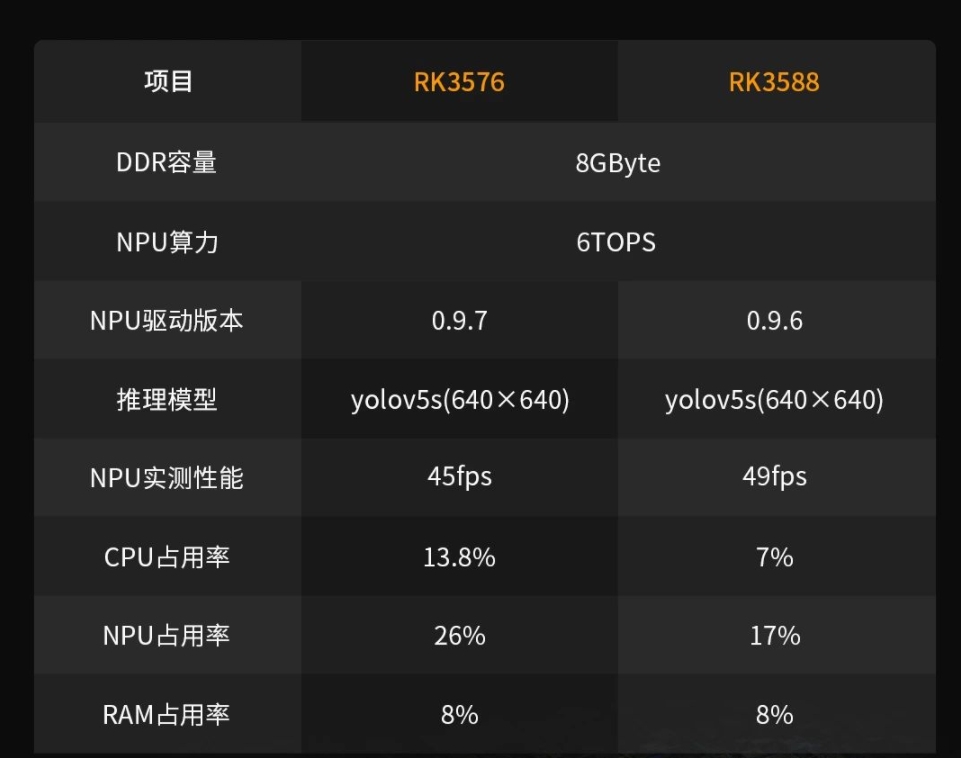
NPU性能深度評測:瑞芯微RK3588、RK3576、RK3568、RK3562
隨著AI技術不斷發(fā)展,越來越多的嵌入式設備開始集成NPU(神經(jīng)網(wǎng)絡處理單元),以實現(xiàn)更高效的AI推理。作為國產(chǎn)芯片廠商的佼佼者,瑞芯微推出的RK3588、RK3576、RK3568、R
如何在NXP MCU上啟用D-Cache?
我正在 NXP FRDM-MCXN947 MCU 上測試 TFLite AI 模型的推理時間和性能。雖然我使用 NPU 獲得了良好的性能,但在不使用
發(fā)表于 03-27 07:48



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論