 如何利用NPU與模型壓縮技術優化邊緣AI
如何利用NPU與模型壓縮技術優化邊緣AI

| 本文作者:
Johanna Pingel,MathWorks 產品市場經理
Jack Ferrari,MathWorks 產品經理
Reed Axman,MathWorks 高級合作伙伴經理
隨著人工智能模型從設計階段走向實際部署,工程師面臨著雙重挑戰:在計算能力和內存受限的嵌入式設備上實現實時性能。神經處理單元(NPU)作為強大的硬件解決方案,擅長處理 AI 模型密集的計算需求。然而,AI 模型體積龐大,部署在 NPU上常常面臨困難,這凸顯了模型壓縮技術的重要性。要實現高效的實時邊緣 AI,需要深入探討NPU 與模型壓縮技術(如量化與投影)如何協同工作。
NPU 如何在嵌入式設備上實現實時性能
在嵌入式設備上部署AI模型的關鍵挑戰之一是最小化推理時間——即模型生成預測所需的時間,以確保系統具備實時響應能力。例如,在實時電機控制應用中,推理時間通常需要低于10 毫秒,以維持系統穩定性與響應性,并防止機械應力或部件損壞。工程師必須在速度、內存、功耗與預測質量之間取得平衡。
NPU 專為 AI 推理與神經網絡計算而設計,非常適合處理能力有限且對能效要求極高的嵌入式系統。與通用處理器(CPU)或高性能但耗能較大的圖形處理器(GPU)不同,NPU 針對神經網絡中常見的矩陣運算進行了優化。雖然 GPU 也能執行AI推理任務,但 NPU 在成本與能耗方面更具優勢。
從成本角度看,NPU是比微控制器(MCU)、GPU 或 FPGA 更具經濟性的AI處理方案。盡管集成 NPU 的芯片初期成本可能高于傳統微控制器,但其卓越的能效與 AI 處理能力使其在整體價值上更具吸引力。NPU專為加速神經網絡推理而設計,在功耗遠低于 CPU 的同時提供更高的性能。這種效率不僅降低了運行成本,還延長了嵌入式設備的電池壽命,從而在長期使用中更具成本效益。此外,NPU 可實現實時AI處理,無需依賴更昂貴、耗能更高的 GPU 或 FPGA,進一步增強了其經濟吸引力。
NPU 是一種經濟、高能效的解決方案,專為嵌入式系統中的高效 AI 推理與神經網絡計算而設計。
盡管 NPU 在 AI 推理方面效率極高,但在嵌入式系統中,其內存與功耗仍然有限。因此,模型壓縮成為關鍵手段,以減小模型體積與復雜度,使 NPU 在不超出系統限制的前提下實現實時性能。
利用投影與量化壓縮 AI 模型
模型壓縮技術通過減小模型體積與復雜度,提升推理速度并降低功耗,從而幫助大型AI模型部署到邊緣設備。然而,過度壓縮可能會影響預測精度,因此工程師需謹慎評估在滿足硬件限制的前提下可接受的精度損失范圍。
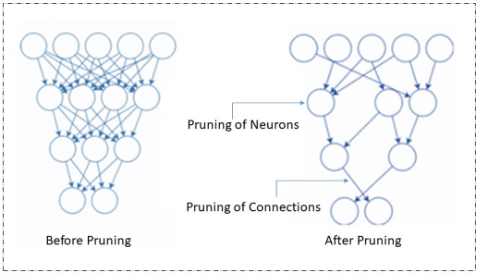
投影與量化是兩種互補的壓縮技術,可聯合使用以優化 AI 模型在 NPU 上的部署。投影通過移除冗余的可學習參數來減小模型結構,而量化則將剩余參數轉換為低精度(通常為整數)數據類型,從而進一步壓縮模型。兩者結合可同時壓縮模型結構與數據類型,在保持精度的同時提升效率。
推薦的做法是先使用投影對模型進行結構壓縮,降低其復雜度與體積,再應用量化以進一步減少內存占用與計算成本。
投影
神經網絡投影是一種結構壓縮技術,可通過將層的權重矩陣投影到低維子空間來減少模型中的可學習參數。在MATLAB Deep Learning Toolbox中,該方法基于主成分分析(PCA),識別神經激活中變化最大的方向,并通過更小、更高效的表示來近似高維權重矩陣,從而移除冗余參數。這種方式在保留模型準確性與表達能力的同時,顯著降低了內存與計算需求。
量化
量化是一種數據類型壓縮技術,通過將模型中的可學習參數(權重與偏置)從高精度浮點數轉換為低精度定點整數類型,來減少模型的內存占用與計算復雜度。這種方法可顯著提升模型的推理速度,尤其適用于NPU部署。雖然量化會帶來一定的數值精度損失,但通過使用代表實際運行情況的輸入數據對模型進行校準,通常可以在可接受的范圍內保持準確性,滿足實時應用需求。
應用案例:在 STMicroelectronics 微控制器上部署量化模型
STMicroelectronics 開發了一套基于 MATLAB 與 Simulink 的工作流程,用于將深度學習模型部署到 STM32 微控制器。工程師首先設計并訓練模型,隨后進行超參數調優與知識蒸餾以降低模型復雜度。接著,他們應用投影技術移除冗余參數以實現結構壓縮,并使用量化將權重與激活值轉換為8位整數,從而減少內存使用并提升推理速度。這種雙階段壓縮方法使得深度學習模型能夠在資源受限的 NPU 與 MCU 上部署,同時保持實時性能。
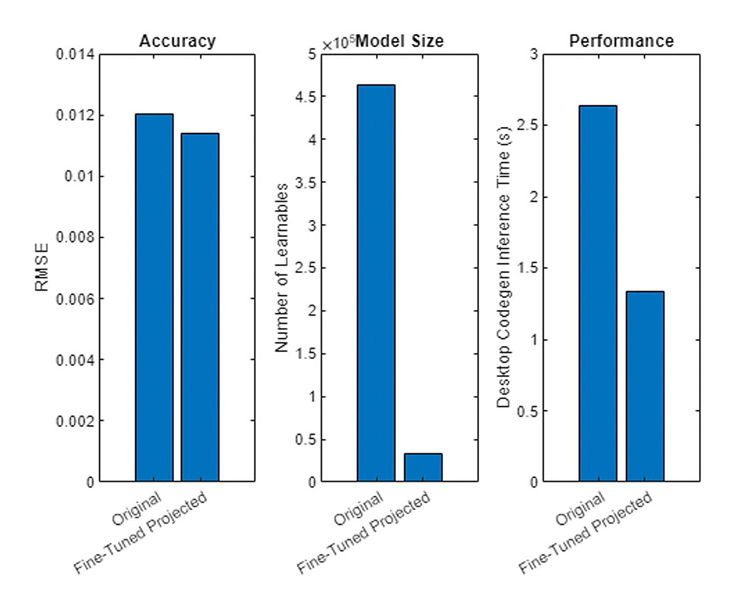
對一個包含LSTM層的循環神經網絡在建模電池荷電狀態時,投影并調優前后的準確率、模型大小與推理速度進行對比。
在 NPU上部署 AI 模型的最佳實踐
投影與量化等模型壓縮技術可顯著提升 AI 模型在 NPU 上的性能與可部署性。然而,由于壓縮可能影響模型精度,因此必須通過仿真與硬件在環(HIL)驗證進行迭代測試,以確保模型滿足功能與資源要求。盡早且頻繁地測試有助于工程師在問題擴大前及時發現并解決,從而降低后期返工風險,確保嵌入式系統部署順利進行。
統一的開發生態系統也能解決 AI 模型部署中面臨的諸多挑戰,簡化集成流程,加快開發進度,并在整個過程中支持全面測試。在當今軟件環境日益碎片化的背景下,這一點尤為重要。工程師常常需要將不同代碼庫集成到仿真流程或更大的系統環境中。由于各平臺與標準開發環境分離,集成與驗證的復雜性進一步增加。引入 NPU 后,工具鏈的復雜性也隨之上升,因此更需要統一的生態系統來應對這些挑戰。
面向邊緣設計:在功耗、精度與性能之間尋求平衡
嵌入式 AI 的未來以性能為核心,專為邊緣環境而構建,并由驅動復雜工程系統的 AI 模型提供動力。工程師的成功依賴于對模型壓縮權衡的深入理解、在硬件上盡早進行測試,以及構建具備適應性的系統。通過將智能的 NPU 與 AI 模型設計相結合,并輔以戰略性的壓縮技術,工程師能夠將嵌入式設備轉變為強大的實時決策引擎。
| 本文作者
Johanna Pingel, MathWorks
Johanna Pingel 是 MathWorks 的產品市場經理。她專注于機器學習和深度學習應用,致力于讓人工智能變得實用、有趣且易于實現。她于 2013 年加入公司,專長于使用 MATLAB 進行圖像處理和計算機視覺應用。
Jack Ferrari, MathWorks
Jack Ferrari 是 MathWorks 的產品經理,致力于幫助 MATLAB 和 Simulink 用戶將 AI 模型壓縮并部署到邊緣設備和嵌入式系統中。他擁有與多個行業客戶合作的經驗,包括汽車、航空航天和醫療器械行業。Jack 擁有波士頓大學機械工程學士學位。
Reed Axman, MathWork
Reed Axman 是 MathWorks 的高級合作伙伴經理,負責為 STMicroelectronics、Texas Instruments 和 Qualcomm 等公司提供以硬件為中心的 AI 工作流程支持。他與 MathWorks 的合作伙伴及內部團隊協作,幫助客戶將嵌入式 AI 能力集成到其產品中。他擁有亞利桑那州立大學機器人與人工智能碩士學位,研究方向為用于醫療應用的軟體機器人。
-
嵌入式
+關注
關注
5201文章
20516瀏覽量
335019 -
AI
+關注
關注
91文章
40197瀏覽量
301785 -
模型
+關注
關注
1文章
3772瀏覽量
52158 -
NPU
+關注
關注
2文章
379瀏覽量
21147
原文標題:更智能、更小巧、更快速:工程師如何通過 NPU 與模型壓縮優化邊緣 AI
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
模型壓縮技術,加速AI大模型在終端側的應用
NanoEdge AI的技術原理、應用場景及優勢
AI賦能邊緣網關:開啟智能時代的新藍海
無法在NPU上推理OpenVINO?優化的 TinyLlama 模型怎么解決?
邊緣AI算力臨界點:深度解析176TOPS香橙派AI Station的產業價值
【HarmonyOS HiSpark AI Camera】邊緣計算安全監控系統
音頻處理SoC在500 μW以下運行AI
嵌入式邊緣AI應用開發指南
ST MCU邊緣AI開發者云 - STM32Cube.AI
邊緣AI的模型壓縮技術
邊緣AI的模型壓縮技術



 工商網監
工商網監
評論