 安謀科技:端側NPU技術創新,拉動AI算力落地引擎
安謀科技:端側NPU技術創新,拉動AI算力落地引擎

電子發燒友網報道(文/黃晶晶)在日前舉行的2025集成電路發展論壇(成渝)暨三十一屆集成電路設計業展覽會(ICCAD-Expo2025)上,安謀科技產品總監鮑敏祺接受行業媒體采訪,談及最新發布的周易X3 NPU IP以及生態建設、NPU發展趨勢等話題。

圖:安謀科技產品總監鮑敏祺
周易X3 NPU IP正當時
安謀科技周易X3 NPU IP面向端側AI落地需求,基于專為大模型的DSP+DSA架構,協同AI軟件平臺,可應用于加速卡、智能座艙、具身智能、ADAS、AI PC等設備為其提供AI計算核芯。
該產品支持CNN與Transformer模型架構,單Cluster最高支持4核配置,可提供8~80 FP8TFLOPS靈活算力范圍。其單核帶寬達256GB/s,相較于上一代周易產品在同等工藝下FP16算力提升16倍,計算核心帶寬提升4倍,Softmax與LayerNorm性能提升超過10倍,多核算力線性度達70%~80%。
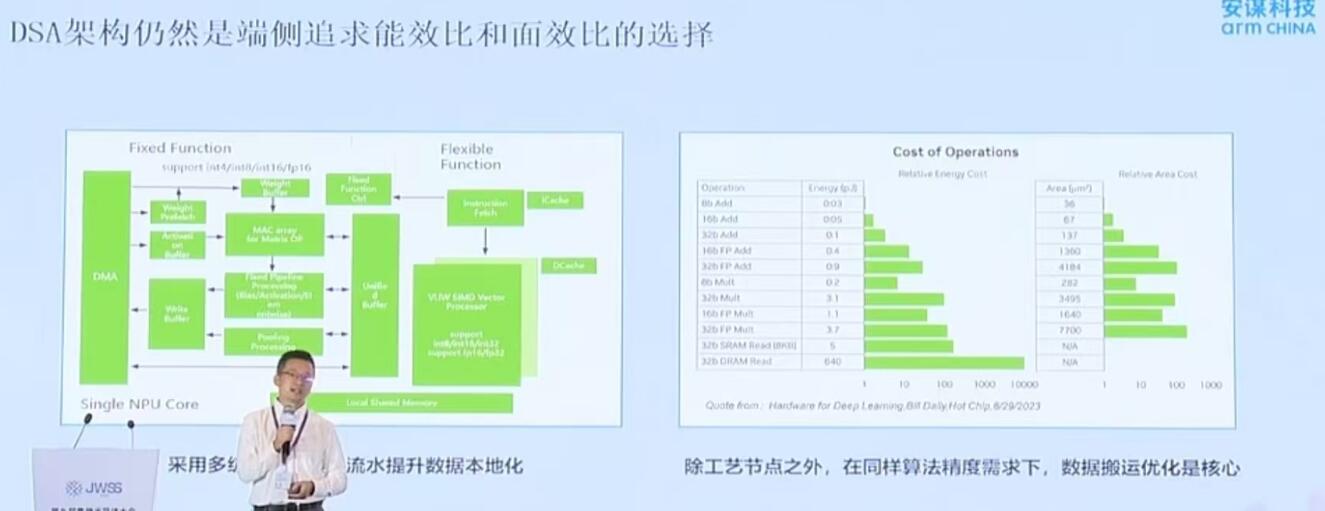
該產品具備多項核心技術優勢,包括通用與專用計算單元深度融合的DSP+DSA架構;支持橫向擴展的多核設計與層級化內存互連方案;軟硬件協同優化的任務調度機制;同時面向開發者提供開放的生態系統,支持硬件自定義接口與軟件層面的算子擴展,增強平臺適配性與應用靈活性。
鮑敏祺表示,周易NPU的核心優勢根植于研發階段對軟件生態的巨大投入,成熟的軟件體系與完善的生態布局,構成了其立足市場的核心競爭力。
在端側 AI 領域,當行業聚焦于同工藝下馮諾依曼架構相差無幾的面積與功耗指標時,周易NPU走出差異化路線。產品面向大模型重點強化了浮點支持能力。這并非簡單集成 FP8浮點等計算單元,更關鍵的是攻克特定精度下模型穩定運行的量化相關技術難題。團隊融入 W4A16、W4A8等一系列計算范式,通過降低神經網絡模型的數值表達位寬來減少計算量、內存占用和功耗,同時盡量保持模型性能,從而讓浮點運算與大模型適配。
周易NPU 的推出時機,源于一年半前的產品定義與對市場趨勢的精準預判。彼時,端側 AI 的價值尚存在爭議,全球 AI 應用還普遍依賴云端算力。而當下,端側 AI 的發展必要性已然凸顯,這既順應行業風向,也契合國內市場的特殊需求。
從行業趨勢來看,今年3月起國際大廠紛紛轉向端側AI賽道,釋放出明確的技術信號。從國內市場來看,面臨著與國外不同的發展環境,例如在算力卡領域,國外已采用3 納米工藝,而由于工藝限制,國內大算力芯片(如 GPU)的單卡性能僅為國際先進水平的 1/5。
同時,中國龐大的用戶群體,也對算力供給提出更高要求。從前些年2T、4T 的算力需求,到如今 8T 乃至更高的算力訴求,市場對端側算力的需求持續攀升。以運行 Llama2 7B 模型為例,僅支撐 256token 的對話功能,算上50%利用率,理論上就需要 3.2TFLOPS 的算力,算力需求的增長可見一斑。正是基于對行業趨勢的深刻洞察,以及對客戶真實需求的精準把握,安謀科技認為當下正是周易NPU 推向市場的最佳時機。
生態伙伴協同
鮑敏祺表示,從生態上來看不同類型企業在AI 賽道的側重點各有不同。算法公司更關注如何通過高效的 AI 算法,在具體業務場景中創造效益、提升效率,底層的算力與芯片并非其關注的核心;SoC公司則聚焦快速go to market的目標,部分企業選擇自研算法,更多企業則傾向于挑選適配的 IP 來加速產品市場化進程。無論是算法公司的效率訴求,還是SoC公司的市場化需求,最終都指向IP高效交付與快速推向市場的核心能力,而這正是安謀科技踐行 AI Arm China 戰略的發力點。
從行業趨勢來看,AI 算法正逐步走向收斂。以往 CNN 等傳統模型遷移過程中,基于cuda編寫的算子往往面臨遷移難題。如今,無論是英偉達向上層 Python、應用層MaaS延伸,還是 OpenAI 等企業的技術推動,國內廠商都形成較高的適配統一性。大模型的運行門檻已大幅降低,僅需支持幾十個左右的算子即可實現大模型部署,所需計算量相較以往大幅減少。與此同時,行業也正經歷從GPGPU 向 ASIC AI 的轉型,博通等企業的快速發展印證了這一趨勢。專用架構能更好地突破GPGPU的能效天花板,實現更優的能效與面積表現。
端側NPU技術趨勢
伴隨 AI 技術的深入演進,端側 NPU 的發展方向逐漸清晰,其未來趨勢將圍繞云邊端協同、通用性提升、專用算力強化三大核心展開,同時在物理工藝與算力功耗的限制下,探尋效率與靈活性的最優解。
鮑敏祺談到,以機器人領域為例,云端負責統籌規劃,邊側承擔協調部署,端側聚焦執行落地。在這一體系中,國外憑借先進算力優勢,可通過持續堆疊硬件提升性能。國內則受限于工藝天花板,難以無限突破物理邊界,因此云邊端協同成為破局關鍵。
算力與功耗的限制,進一步框定端側 NPU 的發展邊界。在電池技術未出現革命性突破的前提下,短期之內端側 AI難以復刻云端的超大算力規模。因此,在有限算力范圍內,提升NPU的通用性與綜合能力,成為行業的核心發力點。
以安謀科技周易X3 NPU IP為代表,DSP+DSA 的組合架構已成為兼顧效率與靈活性的關鍵選擇。周易NPU已支持270余個公開模型,加上客戶定制模型更是達到 400 余個,端側 NPU的通用化已成為必然趨勢。未來,NPU不再局限于適配單一類型模型,而是要具備快速對接多元算法、滿足多場景需求的能力。
針對端側AI不同需求,NPU未來需在專用與通用之間找到平衡。如NPU需要強化Tensor 計算能力,通過增加 Tensor core與帶寬,提升專用算力的效率,但同時也需保留一定的通用 Vector core能力。
總體而言,端側 NPU 的未來發展,將是在云邊端協同的大框架下,以通用化適配海量模型,以專用算力保障運行效率,最終在有限的物理與功耗約束中,實現性能與靈活性的雙重提升。周易NPU從2018 年發展至今已迭代至第六代,最新一代重點面向大模型,未來還將不斷拔高端側NPU IP規格,持續迭代升級穩步深耕。
端側AI時代已經到來,秉持AI Arm China這一發展戰略,安謀科技將聚焦AI技術,依托Arm生態,全力服務于中國本土市場的創新。
發布評論請先 登錄
邊緣AI算力臨界點:深度解析176TOPS香橙派AI Station的產業價值
應對端側AI算力、內存、功耗“三堵墻”困境,安謀科技Arm China “周易”X3給出技術錦囊


架構/算力/軟件/應用全面突破,安謀科技Arm China用“周易”X3破局端側AI

安謀發布“周易”X3 NPU,破局AI算力,智繪未來藍圖

矢量計算性能提升200%,安謀STAR-MC3賦能端側AI革命
AI體驗躍遷,天璣9500用雙NPU開創端側AI新時代


積算科技上線赤兔推理引擎服務,創新解鎖FP8大模型算力
端側AI需求大爆發!安謀科技發布新一代NPU IP,賦能AI終端應用
騰視科技TS-SG-SM7系列AI算力模組:32TOPS算力引擎,開啟邊緣智能新紀元

蘋芯科技 N300 存算一體 NPU,開啟端側 AI 新征程




 工商網監
工商網監
評論