 spark運行的基本流程
spark運行的基本流程

前言:
由于最近對spark的運行流程非常感興趣,所以閱讀了《Spark大數據處理:技術、應用與性能優化》一書。通過這本書的學習,了解了spark的核心技術、實際應用場景以及性能優化的方法。本文旨在記錄和分享下spark運行的基本流程。
一、spark的基礎組件及其概念
1. ClusterManager
在Standalone模式中即為Master,控制整個集群,監控Worker。在YARN模式中為資源管理器。
2. Application
用戶自定義的spark程序, 用戶提交后, Spark為App分配資源, 將程序轉換并執行。
3. Driver
在Spark中,driver是一個核心概念,指的是Spark應用程序的主進程,也稱為主節點。負責運行Application的main( ) 函數并創建SparkContext。
4. Worker
從節點,負責控制計算節點,啟動Executor或Driver。在YARN模式中為NodeManager,負責計算節點的控制。
5. Executor
執行器,在Worker節點上執行任務的組件、用于啟動線程池運行任務。每個Application擁有獨立的一組Executors。
6. RDD Graph
RDD是spark的核心結構, 可以通過一系列算子進行操作( 主要有Transformation和Action操作) 。 當RDD遇到Action算子時, 將之前的所有算子形成一個有向無環圖( DAG) , 也就是RDD Graph。 再在Spark中轉化為Job, 提交到集群執行。一個App中可以包含多個Job。
7. Job
一個RDD Graph觸發的作業, 往往由Spark Action算子觸發, 在SparkContext中通過runJob方法向Spark提交Job。
8. Stage
每個Job會根據RDD的寬依賴關系被切分很多Stage, 每個Stage中包含一組相同的Task, 這一組Task也叫TaskSet。
9. Task
一個分區對應一個Task, Task執行RDD中對應Stage中包含的算子。 Task被封裝好后放入Executor的線程池中執行。
二、spark架構
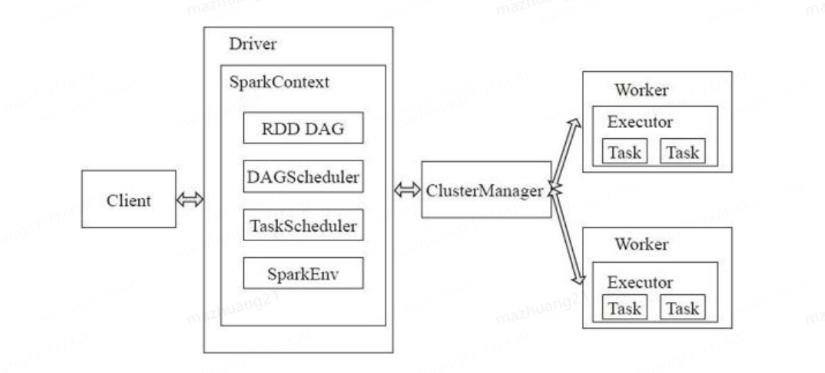
spark架構采用了分布式計算中的Master-Slave模型。Master作為整個集群的控制器,負責整個集群的正常運行;Worker相當于是計算節點,接收主節點命令與進行狀態匯報;Executor負責任務的執行;Client作為用戶的客戶端負責提交應用,Driver負責控制一個應用的執行。
?
??
如圖所示,spark集群部署后,需要在主節點和從節點分別啟動Master進程和Worker進程,對整個集群進行控制。在一個spark應用的執行過程中,Driver和Worker是兩個重要角色。Driver程序是應用邏輯執行的起點,負責作業的調度,即Task任務的分發,而多個Worker用來管理計算節點和創建Executor并行處理任務。在執行階段,Driver會將Task和Task所依賴的file和jar序列化后傳遞給對應的Worker機器,同時Executor對相應數據分區的任務進行處理。
三、Spark的工作機制
1. Spark的整體流程
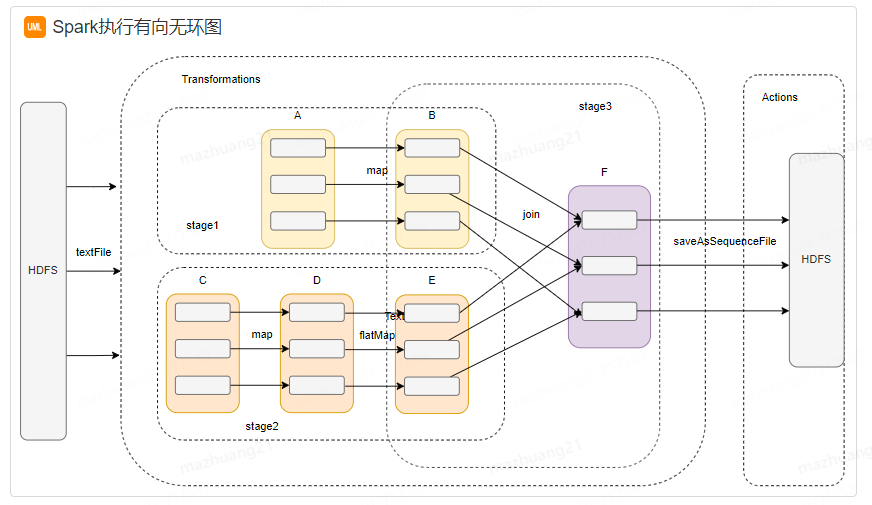
Client提交應用,Master找到一個Worker啟動Driver,Driver向Master或者資源管理器申請資源,之后將應用轉化為RDD Graph,再由DAG Scheduler將RDD Graph轉化為Stage的有向無環圖提交給TaskScheduler,由TaskScheduler提交任務給Executor執行。
?
??
如圖所示,在spark應用中,整個執行流程在邏輯上會形成有向無環圖。Action算子觸發之后,將所有累計的算子形成一個有向無環圖,然后由調度器調度該圖上的任務進行運算。spark根據RDD之間不同的依賴關系切分形成不同的階段(stage),一個階段包含一系列函數執行流水線。途中A、B、C、D、E、F、分別代表不同的RDD,RDD內的方框代表分區。數據從HDFS輸入spark,形成RDD A和RDD C,RDD C上執行map操作,轉換為RDD D,RDD B和RDD E執行Join操作,轉換為F。而在B和E連接轉化為F的過程中又會執行Shuffle,最后RDD F通過函數saveAsSequenceFile輸出并保存到HDFS中。
2. Stage的劃分
如上面這個運行流程所示,在 Apache Spark 中,一個作業(Job)通常會被劃分為多個階段(Stage),每個階段包含一組并行的任務(Task)。這種劃分主要是基于數據寬窄依賴進行的,以便更有效地進行任務調度和執行。以下是關于 Spark 中 Stage 劃分的一些關鍵點:
?寬窄依賴
窄依賴(Narrow Dependency):父 RDD 的每個分區只會被一個子 RDD 的分區使用,或者多個子 RDD 分區計算時都使用同一個父 RDD 分區。窄依賴允許在一個集群節點上以流水線的方式(pipeline)計算所有父分區,不會造成網絡之間的數據混洗。
寬依賴(Wide Dependency):父 RDD 的每個分區都可能被多個子 RDD 分區所使用,會引起 shuffle。
?Stage的劃分
Spark 根據 RDD 之間的寬窄依賴關系來劃分 Stage。遇到寬依賴就劃分一個 Stage,每個 Stage 里面包含多個 Task,Task 的數量由該 Stage 最后一個 RDD 的分區數決定。一個 Stage 內部的多個 Task 可以并行執行,而 Stage 之間是串行執行的。只有當一個 Stage 中的所有 Task 都計算完成后,才會開始下一個 Stage 的計算。
?Shuffle 與 Stage 邊界
當 Spark 遇到一個寬依賴(如 `reduceByKey`、`groupBy` 等操作)時,它需要在該操作之前和之后分別創建一個新的 Stage。這是因為寬依賴需要 shuffle 數據,而 shuffle 通常涉及磁盤 I/O,因此將寬依賴作為 Stage 之間的邊界可以提高效率。
3. Stage和Task調度方式
Stage的調度是由DAGScheduler完成的。 由RDD的有向無環圖DAG切分出了Stage的有向無環圖DAG。 Stage的DAG通過最后執行Stage為根進行廣度優先遍歷, 遍歷到最開始執行的Stage執行, 如果提交的Stage仍有未完成的父母Stage, 則Stage需要等待其父Stage執行完才能執行。 同時DAGScheduler中還維持了幾個重要的Key-Value集合構, 用來記錄Stage的狀態, 這樣能夠避免過早執行和重復提交Stage。waitingStages中記錄仍有未執行的父母Stage, 防止過早執行。 runningStages中保存正在執行的Stage, 防止重復執行。failedStages中保存執行失敗的Stage, 需要重新執行。
每個Stage包含一組并行的Task,這些Task被組織成TaskSet(任務集合)。DAGScheduler將劃分好的TaskSet提交給TaskScheduler。TaskScheduler是負責Task調度和集群資源管理的組件。TaskScheduler通過TaskSetManager來管理每個TaskSet。TaskSetManager會跟蹤和控制其管轄的Task的執行,包括任務的啟動、狀態監控和失敗重試等。當TaskSet被提交到TaskScheduler時,TaskScheduler會決定在哪些Executor上運行Task,并通過集群管理器(如YARN、Mesos或Spark Standalone)將Task分發到相應的節點上執行。Executor接收到Task后,會在其管理的線程池中執行任務。執行過程中,Task的狀態會不斷更新,并通過狀態更新機制通知TaskSetManager。TaskSetManager根據接收到的狀態更新來跟蹤Task的執行情況,如遇到任務失敗,會觸發重試機制直至達到設定的重試次數。
當所有Task都執行完成后,TaskScheduler會通知DAGScheduler,并由DAGScheduler負責觸發后續Stage的執行(如果存在)。
4. Shuffle機制
為什么spark計算模型需要Shuffle過程? 我們都知道, spark計算模型是在分布式的環境下計算的, 這就不可能在單進程空間中容納所有的計算數據來進行計算, 這樣數據就按照Key進行分區, 分配成一塊一塊的小分區, 打散分布在集群的各個進程的內存空間中, 并不是所有計算算子都滿足于按照一種方式分區進行計算。 例如, 當需要對數據進行排序存儲時, 就有了重新按照一定的規則對數據重新分區的必要, Shuffle就是包裹在各種需要重分區的算子之下的一個對數據進行重新組合的過程。
?
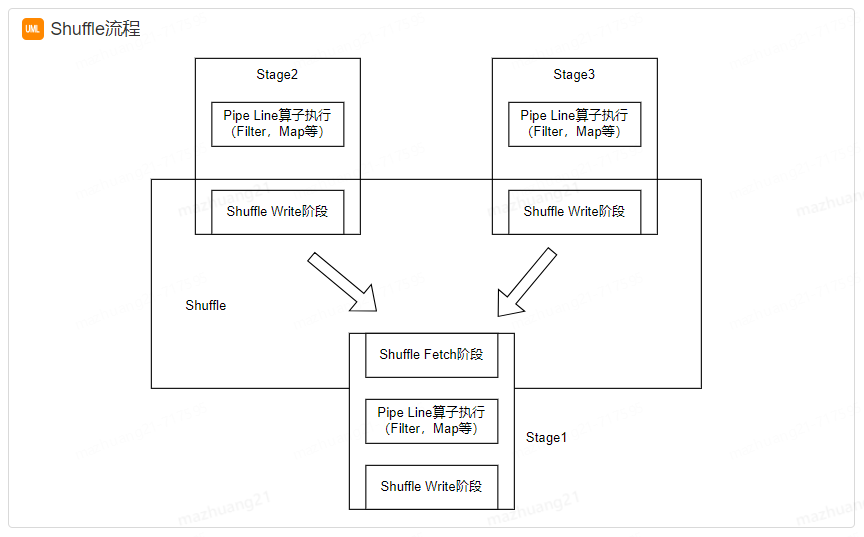
?如圖, 整個Job分為Stage1~Stage3, 3個Stage。首先從最上端的Stage2、 Stage3執行, 每個Stage對每個分區執行變換( transformation) 的流水線式的函數操作, 執行到每個Stage最后階段進行Shuffle Write,將數據重新根據下一個Stage分區數分成相應的Bucket, 并將Bucket最后寫入磁盤。 這個過程就是Shuffle Write階段。執行完Stage2、 Stage3之后, Stage1去存儲有Shuffle數據節點的磁盤Fetch需要的數據, 將數據Fetch到本地后進行用戶定義的聚集函數操作。 這個階段叫Shuffle Fetch, Shuffle Fetch包含聚集階段。 這樣一輪一輪的Stage之間就完成了Shuffle操作。
四、結語
在閱讀《Spark大數據處理:技術、應用與性能優化》一書后,我大概了解了spark的運行機制及原理。上文僅是做了一個簡單的總結,而且并沒有對一些細節進行深入解讀。在原書中有著十分詳細的介紹,包含其容錯、IO、網絡等機制以及從源碼解析spark的運行流程,而且書中通過大量實際案例,展示了如何在具體應用中使用Spark進行數據處理、分析和挖掘,使理論與實踐相結合,大家如有興趣可自行閱讀。
審核編輯 黃宇
-
大數據
+關注
關注
64文章
9084瀏覽量
143928 -
SPARK
+關注
關注
1文章
108瀏覽量
21265
發布評論請先 登錄
后量化模型在 iMX93 NPU 上運行,但輸出不正確怎么解決
首屆中國NVIDIA DGX Spark黑客松大賽開啟報名
NVIDIA DGX Spark助力高等教育領域重大項目
全新軟件與模型優化為NVIDIA DGX Spark注入強大動力
NVIDIA DGX Spark桌面級AI超級計算機助力開發者構建AI模型
如何在DGX Spark上運行NVIDIA Omniverse

CW32時鐘運行中失效檢測的流程是什么?CW32時鐘運行中失效檢測注意事項有哪些呢?
NVIDIA DGX Spark系統恢復過程與步驟

NVIDIA DGX Spark助力構建自己的AI模型

在NVIDIA DGX Spark平臺上對NVIDIA ConnectX-7 200G網卡配置教程
NVIDIA DGX Spark快速入門指南

FPGA板下載運行調試流程
NVIDIA黃仁勛向SpaceX馬斯克交付DGX Spark
NVIDIA DGX Spark新一代AI超級計算機正式交付
NVIDIA DGX Spark桌面AI計算機開啟預訂




 工商網監
工商網監
評論