") 軟件生態(tài)上超越CUDA,究竟有多難?
軟件生態(tài)上超越CUDA,究竟有多難?

電子發(fā)燒友網(wǎng)報道(文/周凱揚)近日,英偉達憑借持續(xù)上漲的股價,正式超過了微軟成為全球市值最高的公司,這固然離不開GPU這一AI硬件的火熱,但之所以能一舉做到世界第一,也離不開軟件的加持,真正將其推向神壇的,還是圍繞CUDA打造的一系列軟件生態(tài)。
英偉達——CUDA的絕對統(tǒng)治
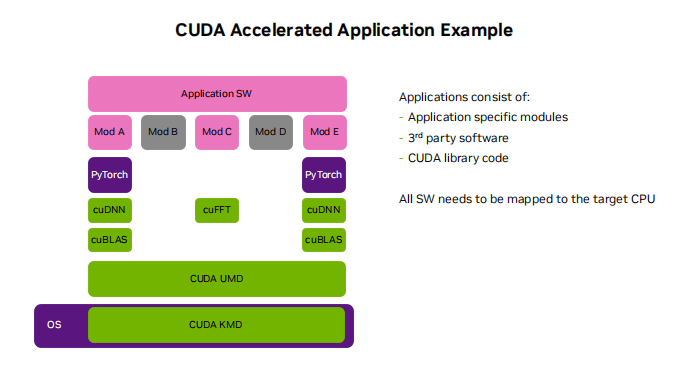
相信對GPU有過一定了解的都知道,英偉達的最大護城河就是CUDA。CUDA在后端架構(gòu)上處于絕對的統(tǒng)治地位,隨著AI發(fā)展越快,英偉達GPU+CUDA的開發(fā)生態(tài)發(fā)展愈發(fā)壯大,甚至到了很多競爭對手望其項背的水平。CUDA自2006年推出以來,即便在AI和深度學習沒有成為主流的時期,也在不斷發(fā)展并行計算,為開發(fā)者提供豐富的庫、工具和算法。
時至今日,CUDA已經(jīng)為全球開發(fā)者打造了一個龐大的社區(qū),幾乎所有的深度學習框架,包括TensorFlow、Pytorch等都對CUDA做了優(yōu)化。為了盡快切入市場,絕大多數(shù)開發(fā)者都更傾向于選擇CUDA作為首要計算平臺。
與此同時,英偉達也在圍繞著CUDA在硬件架構(gòu)上做更深入的創(chuàng)新和升級,借助更先進的工藝和封裝技術(shù)提升計算性能和效率。比如隨著Volta架構(gòu)中引入Tensor核心后,英偉達GPU的矩陣運算得到大幅加強,深度學習訓練和推理的性能實現(xiàn)飛躍。兩者結(jié)合之下,使得CUDA坐穩(wěn)了第一的寶座。
在游戲軟件領(lǐng)域,英偉達的DLSS可以說是市面上最先進的專有超分技術(shù),且得益于持續(xù)的訓練,每一次版本升級都能帶來圖形渲染領(lǐng)域的突破。
最后是生產(chǎn)力工具相關(guān)的軟件生態(tài)上,英偉達在這塊的優(yōu)勢就更加足了,過去蘋果與AMD還在GPU上合作之際,不少生產(chǎn)力工具還是針對AMD的GPU做了不少硬件優(yōu)化的。然而隨著蘋果走向Arm架構(gòu),英偉達慢慢在這個市場壯大起來。
無論是Adobe旗下的多媒體處理軟件,還是一些獨立開發(fā)商打造的軟件,很多都有英偉達CUDA硬件加速的支持,甚至連英特爾的核顯在一些軟件支持上,都要好于AMD。正因如此,除了一些特效制作相關(guān)的工作外,工作站里的AMD GPU越來越少。
盡管谷歌、英特爾和高通等科技巨頭也在尋找打破CUDA壟斷地位的契機,但對于軟件生態(tài)而言,合作并不一定意味著共贏,最后很可能只是為市場提供更多的可選擇項,但在易用性、性能等方面,仍不如沒有駐足一路狂奔的CUDA。
AMD
AMD對于其GPU軟件生態(tài)則持以較為開放的態(tài)度,且極其重視開源開發(fā)社區(qū)。AMD的ROCm對標的正是英偉達的CUDA,但其并沒有對硬件做出限制,除了Radeon、Instinct系列的GPU外,也在擴展至其他硬件廠商的設(shè)備。這也得益于AMD沒有在硬件內(nèi)引入Tensor核心這樣的專有硬件,但也正是因為如此,導致其ROCm在某些任務(wù)上略顯遜色。
ROCm作為開源平臺,也提供多種庫和框架支持,也有一整套的開源工具鏈。正因如此,在HPC和云計算等領(lǐng)域,廠商其實更寧愿使用AMD的GPU,而不必要忍受英偉達的專用軟件棧。但苦于英偉達先行的軟件生態(tài),他們不得不首選英偉達的GPU。
AMD即便有了ROCm,整體軟件生態(tài)的成熟度依然不敵英偉達,對于HPC中部分不以商業(yè)成功為目標的項目而言,AMD已經(jīng)斬獲了不少份額,比如TOP500中前十的幾臺超算。但以整個TOP500榜單來看,英偉達依然占據(jù)主導地位。然而對于云供應(yīng)商來說,短時間內(nèi)依然沒法擺脫英偉達的統(tǒng)治,因為租用這些云服務(wù)的客戶們,更愿意在英偉達的CUDA平臺上開發(fā)。
在驅(qū)動軟件上,尤其是針對Linux的顯卡驅(qū)動,AMD采取了開源和閉源兩條路線,持續(xù)更新閉源驅(qū)動的同時,也允許開源社區(qū)定制化開源驅(qū)動。以基于Linux系統(tǒng)中AMD Radeon顯卡打造的Vulkan驅(qū)動AMDVLK為例,就支持了光線追蹤。然而,盡管開源驅(qū)動由于手動配置和社區(qū)貢獻的原因,兼容性要更高一些,但如果追求的是更高的性能,那么閉源驅(qū)動還是更具優(yōu)勢。
摩爾線程
國產(chǎn)GPU主要分為兩個方向,分別是支持圖形渲染的和不支持圖形渲染的,后者仍然想在AI領(lǐng)域內(nèi)突破,前者在推進C端產(chǎn)品的同時,也在布局B端的一系列AI GPU產(chǎn)品。在國產(chǎn)GPU產(chǎn)品中,在軟件生態(tài)上做得比較好的當屬摩爾線程了,他們在AI和圖形渲染上的軟件支持都有喜人的進展。
基于MUSA這一統(tǒng)一架構(gòu),摩爾線程打造了MTT S80這樣的桌面顯卡,以及面面向服務(wù)器應(yīng)用的MTT S3000等。與之配套的,是摩爾線程打造的軟件開發(fā)平臺,包括AI開發(fā)平臺、MUSA SDK、MT Smart Media和MTVerse XR等。
而且摩爾線程打造的這套生態(tài)架構(gòu)中,可以充分兼容現(xiàn)有軟件生態(tài),借助MUSIFY工具實現(xiàn)代碼零成本遷移到MUSA平臺。與AMD的ROCm一樣,MUSA做的也是兼容CUDA的路線,而不是像ZLUDA一樣重新編譯二進制代碼,所以并不違反英偉達的EULA條款。
從摩爾線程近來官方發(fā)布的消息看來,他們在AI上選擇了逐步對大模型完成適配支持的路線。在摩爾線程的夸娥千卡智算集群上,他們已經(jīng)完成了30億到700億參數(shù)的大模型訓練和推理適配。摩爾線程的GPU在算力上對比國際大廠還是略有遜色,不過隨著未來他們在IP、硬件設(shè)計上進一步突破,相信他們也能打造出高性能的AI算力底座。
在針對消費級圖形顯卡的驅(qū)動程序上,摩爾線程也在不斷更新優(yōu)化性能。以5月底發(fā)布的v260.70版本驅(qū)動為例,除了提供對OpenGL 4.0功能的支持和優(yōu)化Blender 3.6 LTS體驗外,也為諸多熱門游戲在DirectX 11下的性能做了明顯優(yōu)化。盡管這類驅(qū)動更新的規(guī)模比起英偉達還有所差距,但也代表了廠商持續(xù)優(yōu)化性能表現(xiàn)的決心。
寫在最后
其實從越來越多的廠商進軍GPU,越來越多的GPU廠商發(fā)力AI就可以看出,即便CUDA有著深厚的生態(tài)積累,但在日新月異的AI中,其他廠商仍有分一杯羹的機會,甚至可能在某個應(yīng)用中后來者居上。但在圖形渲染相關(guān)的軟件生態(tài)上,廠商面臨的技術(shù)壁壘更加厚。不僅要帶著鉆研十數(shù)年的決心,還要持續(xù)打磨硬件產(chǎn)品,與產(chǎn)業(yè)軟件生態(tài)圈合作,挖掘和培養(yǎng)更多的圖形研究人才。
-
gpu
+關(guān)注
關(guān)注
28文章
5177瀏覽量
135235 -
CUDA
+關(guān)注
關(guān)注
0文章
127瀏覽量
14459 -
英偉達
+關(guān)注
關(guān)注
23文章
4077瀏覽量
99016 -
軟件生態(tài)系統(tǒng)
+關(guān)注
關(guān)注
0文章
9瀏覽量
7199
發(fā)布評論請先 登錄
RV生態(tài)又一里程碑:英偉達官宣CUDA將兼容RISC-V架構(gòu)!
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
聲智科技亮相2026瑞芯微AI軟件生態(tài)大會
NVIDIA CUDA Tile的創(chuàng)新之處、工作原理以及使用方法

在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA CUDA 13.1版本的新增功能與改進
首款全國產(chǎn)訓推一體AI芯片發(fā)布,兼容CUDA生態(tài)

弱電智能化中究竟有多少個子系統(tǒng)?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論