 NVIDIA CUDA Tile的創新之處、工作原理以及使用方法
NVIDIA CUDA Tile的創新之處、工作原理以及使用方法

NVIDIA CUDA 13.1 推出 NVIDIA CUDA Tile,這是自 2006 年 NVIDIA CUDA 平臺發明以來,最大的一次技術進步。這一令人振奮的創新引入了一套面向 Tile-based 并行編程的虛擬指令集,使開發者能夠在更高層級編寫算法,而無需關心底層專用硬件(如 Tensor Cores)的復雜細節。
本文將介紹 CUDA Tile 的創新之處、工作原理以及使用方法。
為什么在 GPU 上需要 Tile 編程?
CUDA 為開發者提供了一種單指令多線程(SIMT)的硬件與編程模型。這既要求也允許開發者對代碼執行方式進行非常細致的控制,從而實現最大化的靈活性。然而,要讓代碼在各種不同的 GPU 架構上都表現良好,往往需要投入大量的調優工作。
NVIDIA CUDA-X、NVIDIA CUTLASS 等庫為開發者提供了性能優化工具,而 CUDA Tile 則進一步提供了一種比傳統 SIMT 更高層次的 GPU 編程方式。
隨著計算任務的發展,尤其是 AI 領域中,Tensors 已經成為基礎的數據類型。NVIDIA 也開發了面向 Tensors 運算的專用硬件,例如 NVIDIA Tensor Cores(TC)和 NVIDIA Tensor Memory Accelerators(TMA),并已成為所有新 GPU 架構的核心組件。
但硬件越復雜,軟件就越需要承擔抽象與封裝的職責。CUDA Tile 對 Tensor Cores 及其編程模式進行了抽象,讓使用 CUDA Tile 的代碼天然兼容當前與未來的 Tensor Core 架構。
Tile-based 編程的方式是:你只需指定一塊塊數據,即Tiles,以及這些 Tiles 上要執行的運算即可。你不再需要在元素級別指定算法的執行方式,編譯器和運行時(runtime )會自動處理。
圖 1 展示了 CUDA Tile 引入的 Tile 模型,與傳統 CUDA SIMT 模型之間的概念性差異。

圖 1. Tile 模型(左)將數據劃分為 Blocks,而編譯器將其映射到 Threads。SIMT 模型(右)則將數據映射到 Blocks 和 Threads
這種編程模式在 Python 這樣的語言中很常見,用戶可以通過 NumPy 這樣的庫指定矩陣等數據類型,然后用簡單的代碼指定并執行批量操作。在底層,一切都會按正確的方式運行,而你的計算對你來說始終完全透明。
CUDA Tile IR:Tile 編程的基礎
CUDA Tile 的基礎是 CUDA Tile IR(中間表示)。CUDA Tile IR 引入了一套虛擬指令集,使得以 Tile Operations 的方式對硬件進行原生編程成為可能。開發者可以編寫更高層級的代碼,并且在多代 GPU 上僅需做極少的改動即可高效執行。
雖然 NVIDIA Parallel Thread Execution(PTX)為 SIMT 程序提供了可移植性,但 CUDA Tile IR 為 CUDA 平臺擴展了對 Tile-based 程序的原生支持。開發者專注于將他們的數據并行程序劃分為 Tiles 和 Tile Blocks,并讓 CUDA Tile IR 來處理將其映射到諸如 Threads、內存層次結構以及 Tensor Cores 等硬件資源上。
通過提升抽象層級,CUDA Tile IR 使用戶能夠為 NVIDIA 硬件構建更高層次的、面向硬件的編譯器、框架以及領域專用語言(DSLs)。用于 Tile 編程的 CUDA Tile IR 類似于用于 SIMT 編程的 PTX。
需要指出的一點是,這并不是一個非此即彼的選擇。GPU 上的 Tile 編程是編寫 GPU 代碼的另一種方法,但你不必在 SIMT 和 Tile 編程之間做選擇,它們是共存的。當你需要 SIMT 時,你依舊像以往一樣編寫你的 Kernels。當你希望使用 Tensor Cores 來執行運算時,你就編寫 Tile Kernels。
圖 2 展示了一個關于 CUDA Tile 如何嵌入典型軟件棧的高層示意圖,以及 Tile 路徑如何作為一條獨立但互補于現有 SIMT 路徑的編譯路徑。
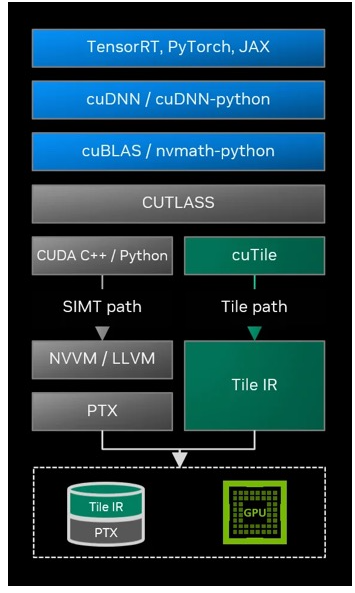
圖 2. Tile 的編譯路徑嵌入完整的軟件棧之中,并與 SIMT 路徑并列存在
開發者應如何使用 CUDA Tile 編寫 GPU 應用?
CUDA Tile IR 位于與絕大多數程序員交互的 Tile 編程的下一層級。除非你正在編寫一個編譯器或庫,否則你大概不需要關心 CUDA Tile IR 軟件的細節。
NVIDIA cuTile Python:大多數開發者將通過諸如 NVIDIA cuTile Python 這樣的軟件與 CUDA Tile 編程進行交互——這是一種由 NVIDIA 提供的 Python 實現,使用 CUDA Tile IR 作為后端。我們有一篇博客解釋了如何使用 cuTile-python,并附上了示例代碼和文檔的鏈接。
CUDA Tile IR:對于希望構建自己 DSL 編譯器或庫的開發者而言,CUDA Tile IR 就是你與 CUDA Tile 交互的地方。CUDA Tile IR 文檔和規范包含關于 CUDA Tile IR 編程抽象、語法和語義的信息。如果你正在編寫一個當前以 PTX 為目標的工具/編譯器/庫,那么你可以調整你的軟件以同時以 CUDA Tile IR 為目標。
如何獲取 CUDA Tile 軟件
CUDA Tile 隨 CUDA 13.1 一同發布。開發者可以通過 CUDA Tile 頁面,獲取包括文檔鏈接、GitHub 庫以及示例代碼等信息。
關于作者
Jonathan Bentz 領導 NVIDIA 的 CUDA 技術營銷工程團隊,其團隊專注于創建和提供引人入勝的內容,并與 CUDA 開發者建立聯系。Jonathan 擁有愛荷華州立大學化學博士學位和計算機科學碩士學位。
Tony Scudiero 是 CUDA 平臺的技術營銷工程師。他致力于將 CUDA 帶給各種類型和能力的開發者。在 NVIDIA 任職期間,他曾使用過大型 HPC 系統和應用、實時聲學模擬 (VRWorks Audio) 和 Omniverse RTX 渲染器。
-
NVIDIA
+關注
關注
14文章
5675瀏覽量
110041 -
硬件
+關注
關注
12文章
3610瀏覽量
69115 -
編程
+關注
關注
90文章
3721瀏覽量
97368
原文標題:專注于你的算法 – 讓 NVIDIA CUDA Tile 來處理硬件細節
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

NVIDIA Grid SERIES K2卡兼容CUDA?
Grid K2 cuda下載位置是?
數碼管的工作原理及使用方法
SRAM的工作原理及其使用方法了解
CUDA核心是什么?CUDA核心的工作原理

點焊機的工作原理及使用方法

在Python中借助NVIDIA CUDA Tile簡化GPU編程




 工商網監
工商網監
評論