 NVIDIA RTX 5090痛失512位顯存!
NVIDIA RTX 5090痛失512位顯存!

NVIDIA有望在今年底或明年初發布下一代RTX 50系列顯卡,大概率首發配備新一代GDDR7顯存,但是顯存位寬和之前的說法不太一樣。
早先有傳聞稱,RTX 50系列可能會回歸消失多年的最多512位顯存,大大提升帶寬。
但是根據曝料專家@kopite7kimi的最新說法,GB20x系列核心的顯存配置和現有AD10x的基本沒什么區別。
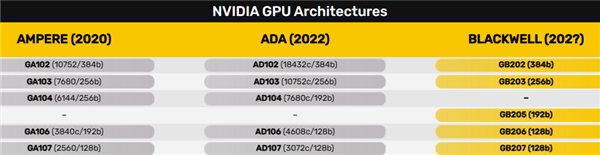
Ada Lovelace架構家族的核心有五種AD102、AD103、AD104、AD106、AD107,位寬分別為384、256、192、128、128-bit。
其中,AD104、AD106相比上代GA104、GA106,位寬都縮水降低了一個檔次。
Blackwell架構家族的核心據說也是五種,分別叫GB202、GB203、GB205、GB206、GB207。
如此說來,它們的位寬配置應該還是384、256、192、128、128-bit。
GDDR7顯存的等效頻率起步就有32GHz,相比于GDDR6X 24GHz提高了三分之一,搭配384-bit位寬就能提供1.5TB/s的帶寬,相當富裕了,自然不再需要成本高得多、需要大量晶體管的512-bit。
GDDR7顯存的初期容量仍然是單顆2GB,美光稱2025年內就會量產3GB,只是不知道是否來得及配給RTX 5090,如果來得及就能做到36GB!
GB202、GB203、GB205三個中高端核心都有望搭配GDDR7,低端的GB206、GB207幾乎肯定不會上。
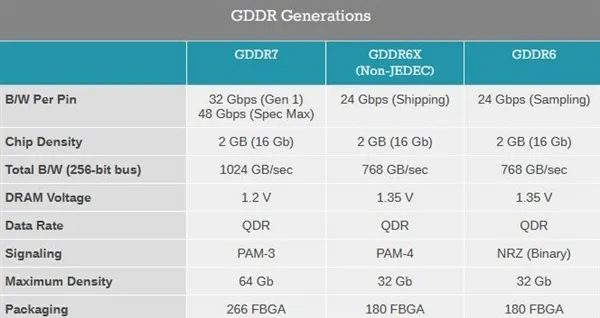
JEDEC組織日前已經正式公布了GDDR7顯存技術規范,各方面指標都有顯著進步,但沒想到在容量密度上停滯不前,只能期待未來了。
GDDR7升級為四通道傳輸架構,每針腳帶寬增至32-48Gbps,相當于GDDR6/6X的整整2-3倍,256-bit位寬下的帶寬最高可達1.5TB/s,還支持片上ECC,而電壓從1.35V降低至1.2V,進一步節省功耗。
此外,信號調制從PAM-4降低到PAM-3,減輕負擔,封裝方式改為266 FBGA。
第一批GDDR7顯存的單顆容量將會只有2GB(16Gb),和如今的GDDR6/6X完全一致,因此首發搭載的NVIDIA RTX 50系列、AMD RX 8000系列,仍然需要相當多的顯存才能達成超大容量。
還好,JEDEC也規劃了更高的容量密度,未來陸續會有3GB、4GB、6GB,甚至是8GB,其中3GB這種反常規容量是首次出現。
但何時量產,就要看三星、美光、SK海力士等巨頭的進度,以及NVIDIA、AMD的采納意愿。
值得一提的是,GDDR6時代也曾經設計過1.5GB單顆容量,但從未量產。
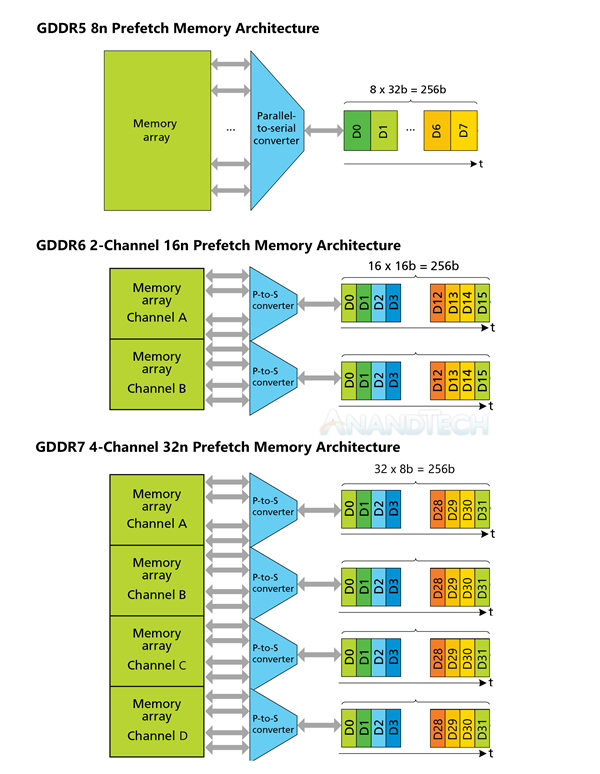
GDDR5/6/7通道架構圖
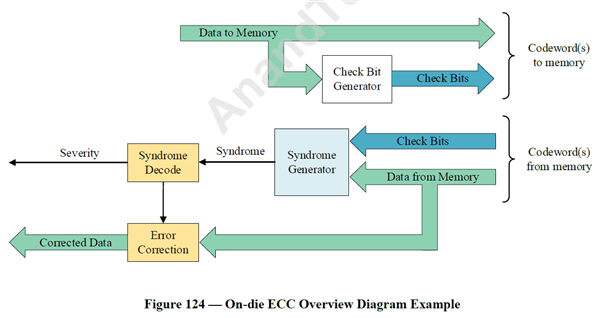
GDDR7片上ECC流程示意圖
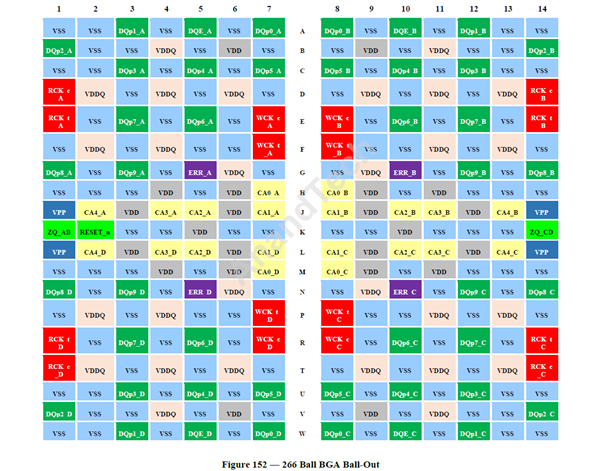
GDDR7針腳定義示意圖
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109717 -
晶體管
+關注
關注
78文章
10395瀏覽量
147723 -
PAM
+關注
關注
2文章
53瀏覽量
14014 -
信號調制
+關注
關注
0文章
40瀏覽量
9274
原文標題:RTX 5090痛失512位顯存!GDDR7足矣
文章出處:【微信號:hdworld16,微信公眾號:硬件世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

NVIDIA RTX PRO 4000 Blackwell GPU性能測試

NVIDIA RTX PRO 5000 72GB Blackwell GPU現已全面上市

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

借助NVIDIA Megatron-Core大模型訓練框架提高顯存使用效率

NVIDIA RTX PRO 4500 Blackwell GPU測試分析

NVIDIA Omniverse Extension開發秘籍
NVIDIA桌面GPU系列擴展新產品
NVIDIA RTX AI加速FLUX.1 Kontext現已開放下載
大模型推理顯存和計算量估計方法研究
算力時代,你的GPU選對了嗎?三張表看清專業卡與消費卡的本質差異


NVIDIA實現神經網絡渲染技術的突破性增強功能
NVIDIA Omniverse Kit 107的安裝部署步驟




 工商網監
工商網監
評論