 算力時代,你的GPU選對了嗎?三張表看清專業卡與消費卡的本質差異
算力時代,你的GPU選對了嗎?三張表看清專業卡與消費卡的本質差異

顯存大小只是冰山一角,單/雙精度算力才是決定GPU真實性能的關鍵。
一、顯存越大越好?警惕選購陷阱
許多用戶在挑選GPU時,第一眼總盯著顯存容量。我們整理了當前顯存Top 10的王者:
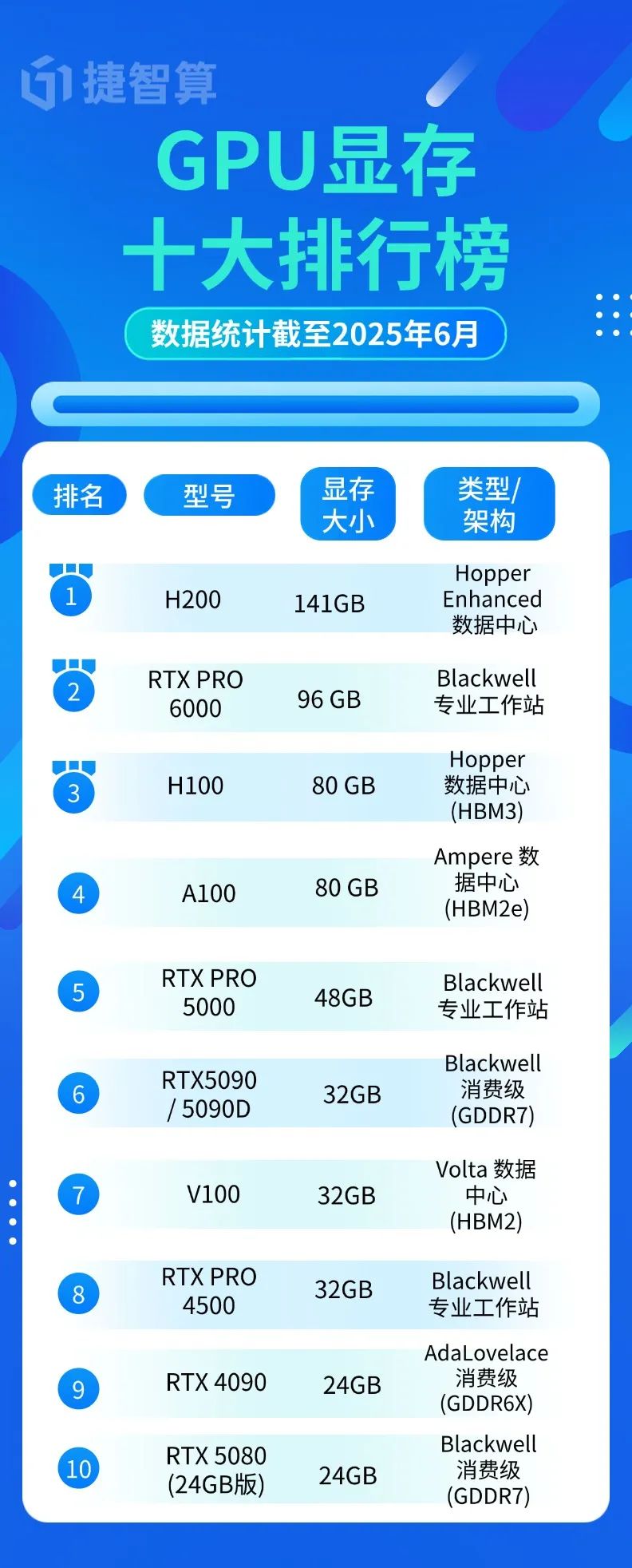
關鍵發現:
- H200以141GB成為科學計算新王者
- 旗艦RTX 5090僅32GB,甚至落后于5年前的數據中心卡V100
- 顯存類型決定帶寬:GDDR6X(如RTX 4090)性能遠遜于HBM3
選購建議:大模型訓練選96GB PRO 6000,4K游戲選24GB RTX 4090足矣!
二、單精度算力:游戲與創作的性能基石
當涉及圖形渲染、AI推理等場景,FP32算力才是核心指標:
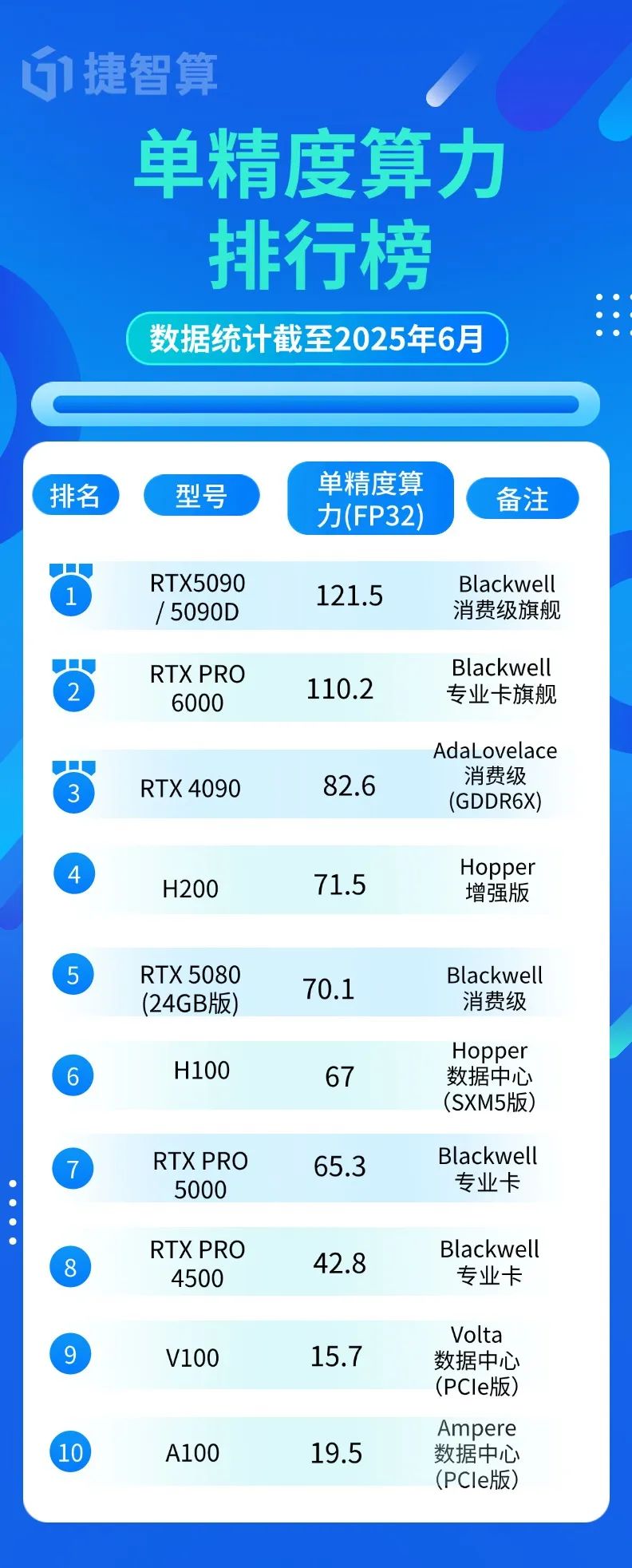
顛覆認知的真相:
- 消費級RTX 5090/5090竟以121.5 TFLOPS超越所有專業卡
- 專業卡RTX PRO 6000(110.2 TFLOPS)更適合多卡并聯的穩定計算
- 老將RTX 4090仍以82.6 TFLOPS穩居消費卡第二
選購建議:游戲/視頻剪輯優先看FP32,RTX 5090 > RTX 4090 > RTX 5080
三、雙精度算力:科學計算的照妖鏡
FP64性能差距才是專業卡與消費卡的本質分水嶺:

雙精度真相:
- 專業卡保留完整FP64單元(PRO 6000達55.1 TFLOPS)
- 消費級顯卡普遍存在雙精度閹割(FP64≈FP32的1/64)
- H200以40.2 TFLOPS成為新一代科學計算標桿
選購建議:流體仿真、量子計算等必須選專業卡(*以上建議僅供參考;本文數據來源于NVIDIA官方技術白皮書及TechPowerUp測試平臺,2025年6月更新。)面對專業顯卡高昂的成本與快速迭代的壓力,越來越多的的個人和企業用戶轉向算力租賃服務。捷智算平臺提供4090、5090、A100等多種高性能GPU顯卡租賃,靈活選擇型號和時長,無需購置硬件即可享受頂尖算力資源。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
gpu
+關注
關注
28文章
5194瀏覽量
135435 -
顯存
+關注
關注
0文章
112瀏覽量
14094 -
算力
+關注
關注
2文章
1532瀏覽量
16742
發布評論請先 登錄
相關推薦
熱點推薦
華為領銜,三劍客入局!十萬卡智算集群落地,國產算力芯片強勢崛起
中國移動宣布,將持續加大對人工智能領域的投入力度,總體投入翻一番,建成國內規模最大、技術領先的智算基礎設施,探索十萬卡智算集群建設,全國產智能算力

Hailo-8算力卡 + RK3588實測!26TOPS加持,助力AI視覺升級!
近年來,AI視覺在邊緣端應用廣泛,行業對AI推理硬件的要求也日益提升。傳統CPU在CNN等視覺模型推理任務中逐漸顯露瓶頸,而專用AI加速器成為破局的關鍵。 Hailo-8 AI算力加速卡憑借“高效

中科曙光scaleX萬卡超集群重塑超大規模算力基礎設施
在“人工智能+”行動深入推進的當下,算力基礎設施已成為國家戰略競爭力的核心,而超大規模集群的運維管控難題卻日益凸顯。中科曙光scaleX萬卡超集群打造的智能管理體系,正以“能管住-管得
GPU 利用率<30%?這款開源智算云平臺讓算力不浪費 1%
作為 AI 開發者,你是否早已受夠這些困境:花數百萬采購的 GPU 集群,利用率常年低于 30%,算力閑置如同燒錢;跨 CPU/GPU/NP
墨芯人工智能千卡集群正式簽約入駐新疆算力中心
在“東數西算”國家工程全面推進的大背景下,新疆憑借其豐富的清潔能源和獨特的區位優勢,正迅速崛起為國家級算力網絡的關鍵樞紐。近日,墨芯人工智能(以下簡稱“墨芯”)的千卡集群正式簽約入駐新

英偉達 H100 GPU 掉卡?做好這五點,讓算力穩如泰山!
H100服務器停工一天損失的算力成本可能比維修費還高。今天,我們給大家總結一套“防掉卡秘籍”,從日常管理到環境把控,手把手教你把掉卡風險壓到最低。一、供電是“生命線”,這3點必須盯緊H

aicube的n卡gpu索引該如何添加?
請問有人知道aicube怎樣才能讀取n卡的gpu索引呢,我已經安裝了cuda和cudnn,在全局的py里添加了torch,能夠調用gpu,當還是只能看到默認的gpu0,顯示不了
發表于 07-25 08:18
拉曼光譜專題2 | 拉曼光譜中的共聚焦方式,您選對了嗎?
拉曼光譜專題2|拉曼光譜中的共聚焦方式,您選對了嗎?——共聚焦技術與AUT-XperRam共聚焦顯微拉曼光譜儀系統什么是共聚焦技術:共聚焦技術的核心就像給相機和探測器配備了一對“精準定位的眼睛

熱插拔算力集群
能力? 服務器節點熱插拔?:集群服務器支持在線更換計算節點(如2U服務器容納12個熱插拔AI節點,單節點集成5個算力卡)。 GPU/算
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
自家GPU 提出的多卡算力互連技術,是早期為了應對深度學習對超高算力需求而單卡
發表于 06-18 19:31
智算加速卡是什么東西?它真能在AI戰場上干掉GPU和TPU!
隨著AI技術火得一塌糊涂,大家都在談"大模型"、"AI加速"、"智能計算",可真到了落地環節,算力才是硬通貨。你有沒有發現,現在越來越多的AI企業不光用GPU,也不怎么迷信TPU了?他

控制系統調優必備知識:“運動控制卡 控制周期怎么算”你真的懂了嗎?
在工業自動化領域,運動控制卡控制周期這個參數常常被忽視,但它卻是影響整個系統穩定性、精度甚至產能的關鍵因素。你是不是也遇到過這些問題:電機總是抖動?軌跡跟蹤老是偏?想優化系統卻無從下手?大概率是你的運動控制

千卡算力破局:科通技術以"AI大模型+AI芯片"重構智算底座
“科通技術”)推出的“DeepSeek+AI芯片”全場景方案,在云AI領域取得重大突破。除了GPU的算力總量,云AI的一大挑戰來源于GPU集群的數據互聯效率。某大型互聯網集團為解決云A



 工商網監
工商網監
評論