 澎峰科技發布大模型推理引擎PerfXLLM
澎峰科技發布大模型推理引擎PerfXLLM

自從2020年6月OpenAI發布chatGPT之后,基于Transformer網絡結構的語言大模型(LLM)引發了全世界的注意與追捧,成為了人工智能領域的里程碑事件。
但大模型推理所需要的巨額開銷也引發了相關研究者的關注。如何高效地進行推理,并盡可能地減少成本,從而促進大模型應用的落地成為了目前的關鍵問題。
于是,澎峰科技研發了一款大模型推理引擎—PerfXLLM,并且已經在高通的驍龍8Gen2平臺實現了應用。接下來將分為四個部分進行介紹,第一部分將介紹PerfXLLM的整體架構設計,第二部分將展示手機端的性能表現,第三部分將詳細地闡述手機端的推理優化方案,最后在第四部分將介紹PerfXLLM的未來規劃。
一、PerfXLLM整體架構
目前大模型推理過程主要放在服務器或者云上進行處理。用戶發出請求,服務器進行響應,通過GPU等高性能計算部件完成推理計算,并通過網絡將結果傳輸給用戶。而隨著移動端設備硬件能力的不斷進步,并且用戶原始數據可能存在敏感隱私信息導致對安全問題有所顧慮,大模型在移動端的應用和落地也成為了實際需求之一。為了兼顧兩部分的需求,PerfXLLM設計上采用了云端一體的架構理念。
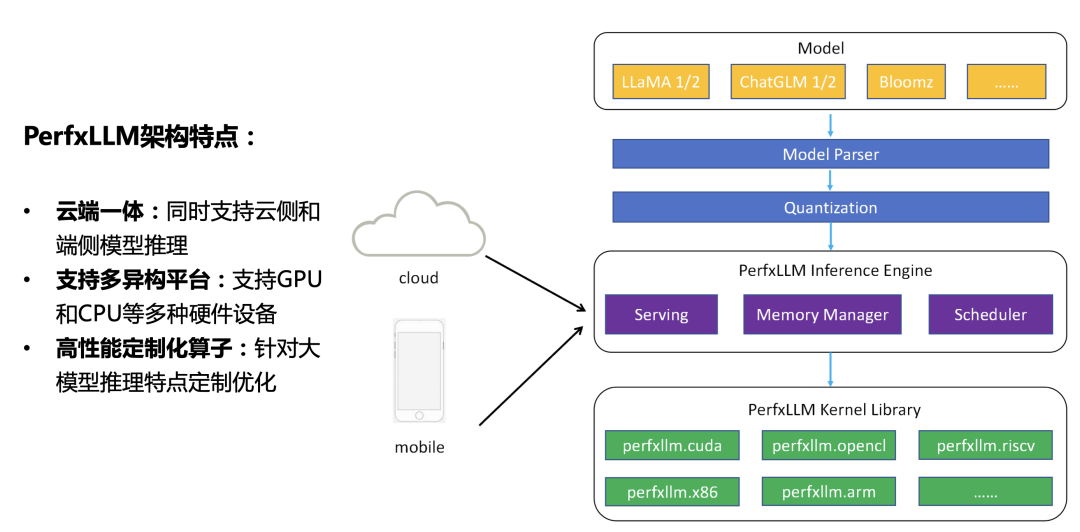
如上圖所示,當模型經過解析量化之后被PerfXLLM的推理引擎加載至內存中。不管是云側還是端側都是調用同樣的一套推理引擎代碼。有所區別的地方在于云側需要進行額外的Serving模塊,從而獲得更高的硬件利用率和QPS響應。再聚焦到底層Kernel,PerfXLLM中開發了一套針對大模型推理的算子庫,可以支持GPU、CPU等多種硬件設備。
二、PerfXLLM應用在手機端
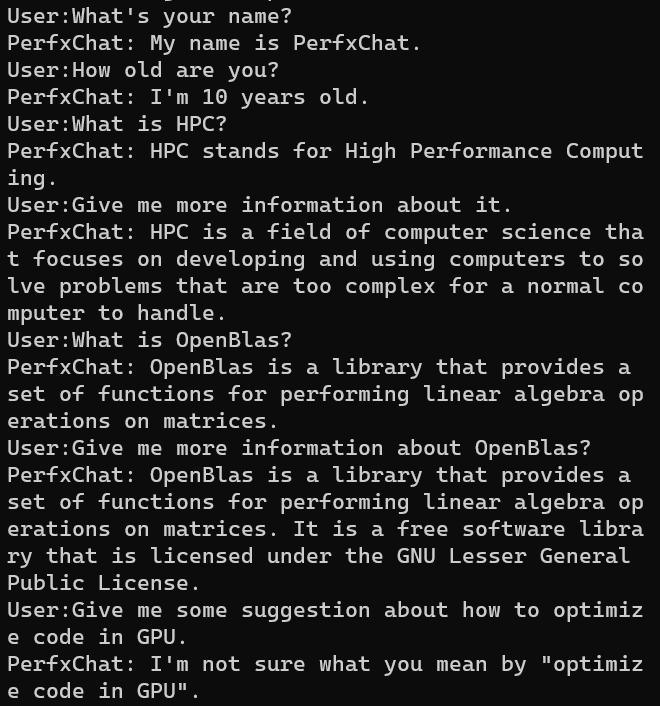
目前,PerfXLLM針對高通驍龍8Gen2芯片進行了定制優化,高通8Gen2芯片進行了定制優化,對LlaMA模型采用了AWQ的int4量化方法,并為模型開發了PerfXChat APP。生成速度為6.7 token/s。模型內存占用為3.7GB。而llama.cpp的生成速度僅為3.2 token/s。
具體而言,通過芯片上的Andreno GPU進行加速,使用了OpenCL編程模型。首先對LlaMA模型進行int4量化,所采用的方式是AWQ量化方法。而后針對LlaMA模型中最耗時的Kernel進行了優化。手機端的輸入token和生成token較少時,模型主要瓶頸在于GEMM算子和GEMV算子,研發團隊對這兩個算子進行了手工調優。模型使用效果如下。
三、手機端推理優化方案介紹
由于手機端的硬件性能與服務器端差距較大,因而在手機端如何將大模型運行起來,并帶給用戶流暢的使用體驗并不是一件容易的事情。為了對手機端的大模型推理進行優化,PerfXLLM目前主要采用的手段有低精度量化、算子融合以及核心算子調優。
3.1.低精度量化
低精度量化指的是將更高精度的數據表示類型轉化成低精度的數據表示類型來加快計算過程。常用的低精度量化有fp16、int8、int4等。通過低精度的量化,可以減少訪存開銷和內存空間,通過特殊計算單元加快運算。因而可以獲得比原精度更高的性能表現。PerfXLLM需要將7B的模型運行在手機上。如果是fp16的模型,則需要大概14GB的內存占用。但是目前市面上手機內存一般不超過16GB,再減去系統本身所需要的內存占用以及其他APP可能需要的內存空間,必須使用低精度量化才能滿足。
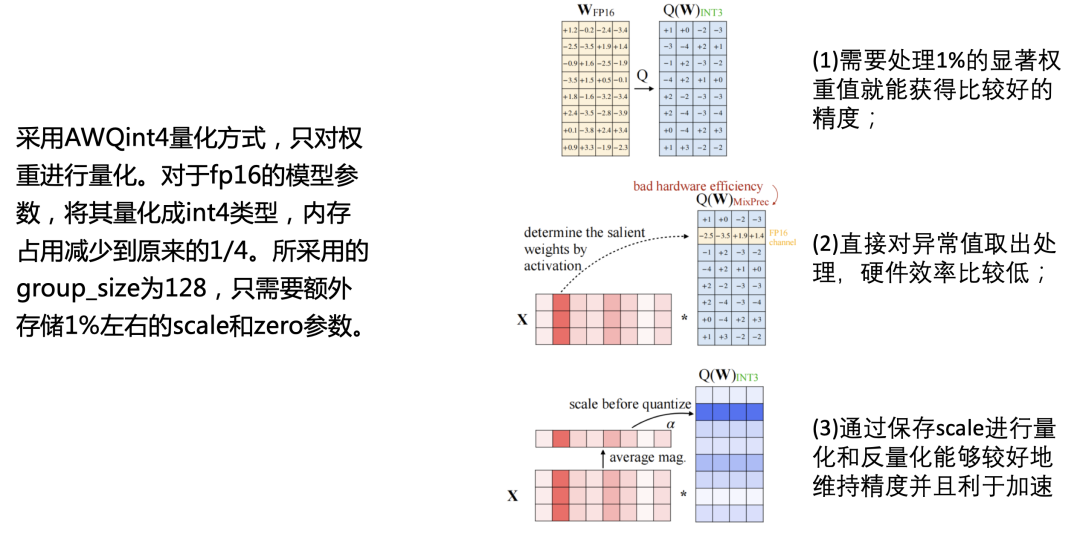
PerfXLLM采用的是AWQ量化方法,只對權重進行量化。對于fp16的模型參數,將其量化成int4類型,內存占用減少到原來的1/4。所采用的group_size為128,只需要額外存儲1%左右的scale和zero參數。
3.2.算子融合
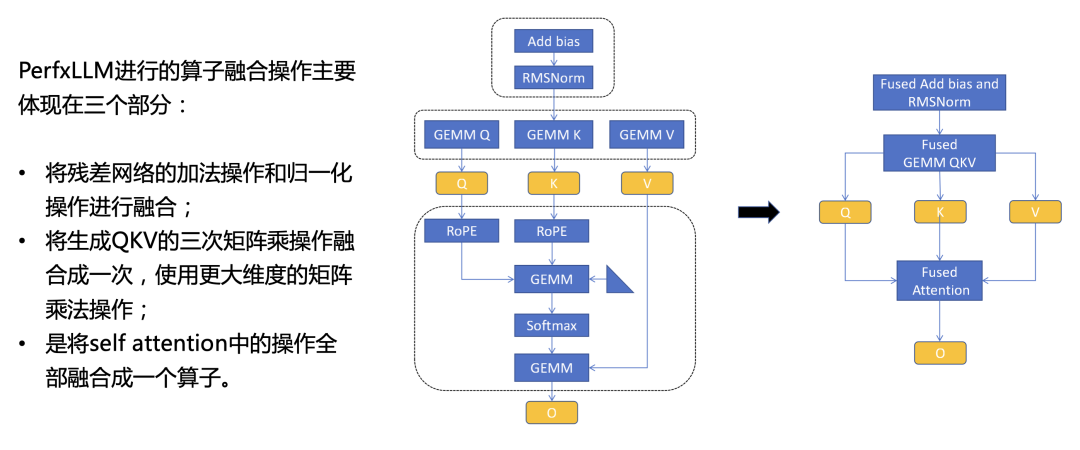
算子融合是將多個算子融合成一個,從而減少中間結果的數據讀取和寫入操作,并且也能有效地減少Kernel launch所需要的開銷。為了提高推理速度,PerfXLLM進行的算子融合操作主要體現在三個部分。第一部分是將殘差網絡的加法操作和歸一化操作進行融合,避免了中間結果在全局內存中的搬運;第二部分是將生成QKV的三次矩陣乘操作融合成一次,使用更大維度的矩陣乘法操作,從而更充分地利用硬件性能;第三部分是將self attention中的操作全部融合成一個算子,這些操作包含針對QK的旋轉編碼,QKV的兩次矩陣乘法以及中間的Softmax操作。具體的示意圖如下。
3.3.核心算子調優
語言大模型中所需要的算子較少,并且絕大部分性能開銷都集中在1-2個算子上,因而針對核心算子的細致調優便顯得尤為關鍵。在手機端,當生成token數量較少時,Attention相關算子的耗時占比非常少,而GEMM(通用矩陣乘法)類的算子耗時幾乎占據了整個推理過程。對于大模型推理而言,一般會分為兩個過程。在第一個過程中,輸入的token數量大于1,對應的算子即GEMM。第二個過程中,輸入的token數量恒定為1,對應的算子即GEMV(矩陣向量乘法)。因此,推理優化的核心問題在于如何提高GEMM和GEMV的性能。PerxLLM對這兩個算子進行了細致的優化。
1)針對GEMM算子。首先介紹GEMM算子的定義,給定矩陣A和B,其維度分別為[m, k]和[k,n],將兩者相乘得到矩陣C,維度為[m, n]。根據輸入token數量的不同,PerfXLLM將其分為兩種情況進行優化。當輸入token數量較少時,矩陣B是一個高瘦矩陣,GEMM變成訪存密集型算子。當輸入token數量較多時,GEMM是一個計算密集型算子。針對兩種不同的情況,PerfXLLM采用了兩種不同的分塊模式,將所需要的數據放置在共享內存之中,以盡可能地減少對全局內存的數據讀取。此外,采用了向量化訪存來提高訪存效率,通過循環展開來避免流水線阻塞提高指令并行度,進行參數調優來獲得更好的并行能力和分塊配置參數。具體的性能表現如下。固定M為12288,K為4096,N變化。
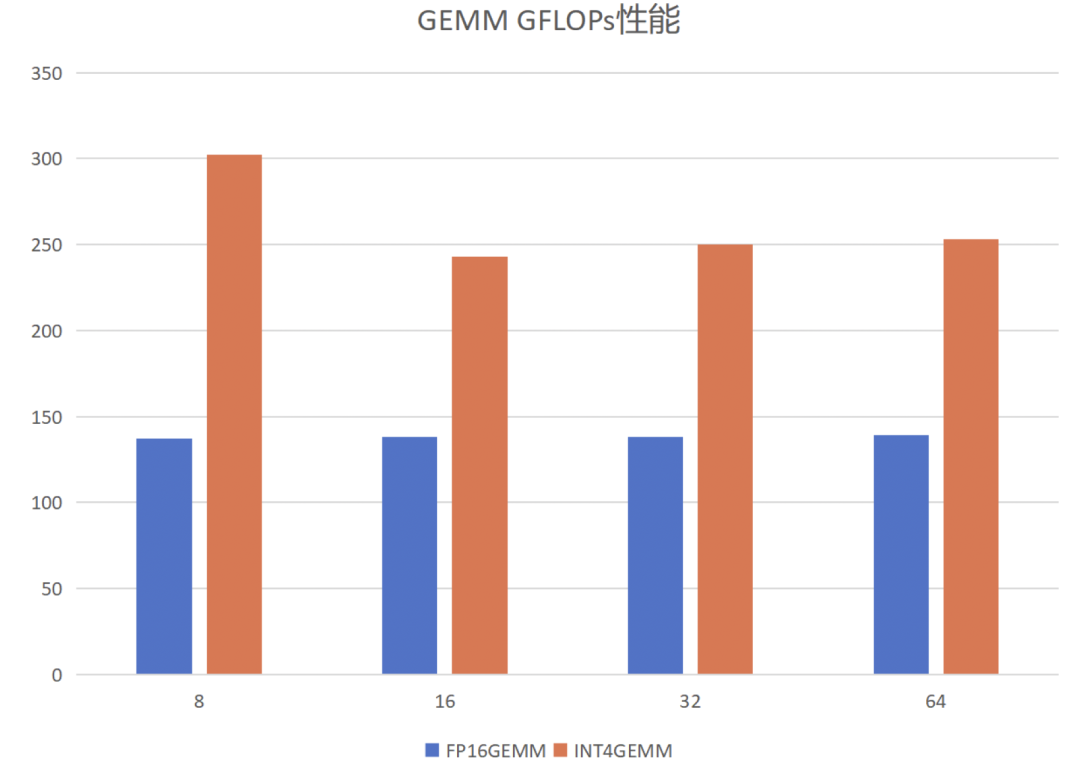
2)針對GEMV算子。需要說明的是,GEMV可以視作GEMM的一種變體,當B矩陣的n等于1時,則GEMM轉換為GEMV算子。GEMV是一個典型的訪存密集型算子,其優化核心在于如何提高訪存效率,并掩蓋計算所需要的開銷。PerfXLLM通過向量化訪存來提高訪存效率,通過循環展開來避免流水線阻塞提高指令并行度。并且針對int4類型的GEMV,通過共享內存來存儲zero和scale來減少對全局內存的數據訪問。此外,對A矩陣的兩個維度進行分塊來提高并行性。使用Image類型來提高對于B向量的訪存性能。
以上一些披露的信息,表明了PerfXLLM已經完成了整個計算系統架構的設計,并將緊密跟隨大模型算法的更迭速度,這彌補了計算芯片迭代慢的弊端(>2年)。
四、未來規劃
4.1.更多的模型支持
4.2.支持更多的硬件
4.3.性能優化
4.4.框架優化
歡迎聯系我們wangjh@perfxlab.com。一起探索大模型的軟件基礎建設。
原文標題:澎峰科技發布大模型推理引擎PerfXLLM
文章出處:【微信公眾號:澎峰科技PerfXLab】歡迎添加關注!文章轉載請注明出處。
-
RISC-V
+關注
關注
48文章
2887瀏覽量
52938 -
澎峰科技
+關注
關注
0文章
82瀏覽量
3699
原文標題:澎峰科技發布大模型推理引擎PerfXLLM
文章出處:【微信號:perfxlab,微信公眾號:perfxlab】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
LLM推理模型是如何推理的?

澎峰科技最新推出Deep Fusion DF35智算一體機
NVIDIA Nemotron Nano 2推理模型發布

澎峰科技完成OpenAI最新開源推理模型適配
積算科技上線赤兔推理引擎服務,創新解鎖FP8大模型算力
螞蟻數科正式發布金融推理大模型
中國智能計算產業聯盟攜手澎峰科技走進山東省政府
信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
大模型推理顯存和計算量估計方法研究
澎峰科技PerfXCloud通過湖南第二批生成式人工智能服務登記
Imagination與澎峰科技攜手推動GPU+AI解決方案,共拓計算生態
Imagination與澎峰科技攜手推動GPU+AI解決方案,共拓計算生態

洲明科技發布勃朗峰畫質引擎UF4
詳解 LLM 推理模型的現狀



 工商網監
工商網監
評論