 如何應對邊緣設備上部署GenAI的挑戰
如何應對邊緣設備上部署GenAI的挑戰

過去十年間,人工智能(AI)和機器學習(ML)領域發生了巨大的變化。卷積神經網絡(CNN)和循環神經網絡(RNN)逐漸被Transformer和生成式人工智能(GenAI)所取代,這標志著該領域進入了一個全新的發展階段。這一轉變源于人們需要更準確、高效且具備上下文理解能力、能處理復雜任務的模型。
起初,AI和ML模型在執行音頻、文本、語音和視覺處理等任務時,高度依賴數字信號處理器(DSP)。這些模型雖有一定成效,但在準確性和可擴展性方面存在局限。神經網絡,尤其是CNN的出現,帶來了重大突破,大幅提升了模型的準確率。比如,AlexNet作為開創性的CNN,在圖像識別方面的準確率達到了65%,超越了DSP的50%。
Transformer的誕生帶來了又一次重大突破。2017年,谷歌在論文《Attention is All You Need》中提出了該模型,憑借更高效的序列數據處理方式,在該領域掀起了一場革命。與局部處理數據的CNN不同,Transformer使用注意力機制來評估輸入數據不同部分的重要性,能夠捕捉數據中的復雜關系與依賴,在自然語言處理(NLP)和圖像識別等任務中展現出卓越的性能。
Transformer推動了GenAI的興起。GenAI借助這些模型,可以依據學習到的模式生成新數據,例如文本、圖像甚至音樂。Transformer能夠理解和生成復雜數據,因此成為ChatGPT和DALL-E等熱門AI應用的基礎。這些模型已展現出卓越能力,比如生成邏輯連貫的文本、根據文字描述生成圖像,充分彰顯了GenAI的巨大潛力。
為何要在邊緣設備上部署GenAI
對于實時處理、隱私和安全要求極高的應用來說,在邊緣設備上部署GenAI具有顯著優勢。智能手機、物聯網設備和自動駕駛汽車等邊緣設備,都能從GenAI的強大能力中獲益。
在邊緣設備上部署GenAI的主要原因之一,是對低延遲處理的需求。自動駕駛、實時翻譯、語音助手等應用需要即時響應,云端處理的延遲會嚴重影響其響應速度。直接在邊緣設備上運行GenAI模型,能最大限度地減少延遲,確保響應快速可靠。
隱私和安全也是重要的考慮因素。將敏感數據傳到云端進行處理,存在數據泄露和未經授權訪問的風險。通過在邊緣設備上部署GenAI,數據處理始終在設備本地進行,這既能增強隱私保護,又能降低安全漏洞風險。這在數據處理需格外謹慎的應用中尤為關鍵,例如醫療健康應用中的患者數據處理。
網絡連接受限也是推動在邊緣設備上部署GenAI的因素。在互聯網接入不可靠的偏遠或欠發達地區,搭載GenAI的邊緣設備可以脫離云連接獨立運行,確保功能持續可用。這對災難救援等可能缺乏可靠通信基礎設施的應用場景至關重要。
應對邊緣設備上部署GenAI的挑戰
在邊緣設備上部署GenAI好處眾多,但也面臨多種挑戰,必須克服這些挑戰,才能確保其有效實施與運行。這些挑戰主要涉及計算復雜性、數據要求、帶寬限制、功耗和硬件約束。
GenAI模型的計算復雜性是一大挑戰。Transformer作為GenAI模型的基礎,因其注意力機制和大規模矩陣乘法運算,計算量極大。這些運算需要強大的處理能力和大量內存,給邊緣設備有限的計算資源帶來沉重壓力。此外,邊緣設備常常需要實時處理,尤其是在自動駕駛或實時翻譯等應用中。GenAI模型對算力的高要求,使得在邊緣設備上實現所需的速度和響應能力困難重重。
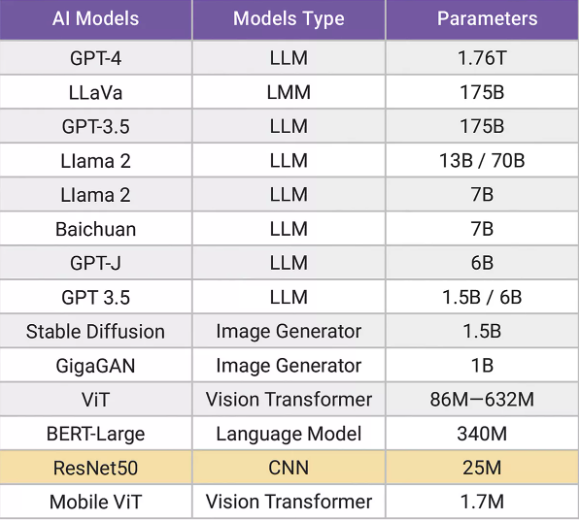
▲表1:GenAI模型(包括大語言模型(LLM)和圖像生成器)的參數量明顯大于CNN
數據要求也帶來了巨大挑戰。訓練GenAI模型需要海量數據。例如,GPT-4等模型訓練使用了數TB的數據,要在存儲和內存容量有限的邊緣設備上處理和存儲這些數據,根本不現實。即便在推理階段,為生成準確且相關的輸出,GenAI模型也可能需要大量數據。受存儲限制,在邊緣設備上管理和處理這些數據頗具挑戰性。
帶寬限制讓GenAI在邊緣設備上的部署變得更為復雜。邊緣設備通常使用低功耗內存接口,如低功耗雙倍數據速率(LPDDR)內存,其帶寬低于數據中心使用的高帶寬內存(HBM)。這會限制邊緣設備的數據處理能力,從而影響GenAI模型的性能。在內存和處理單元之間高效傳輸數據,對GenAI模型的性能至關重要。有限的帶寬會妨礙這一過程,導致處理時間延長、效率降低。
功耗是在邊緣設備上部署GenAI的又一關鍵問題。GenAI模型因計算需求大,耗電量高。這對依靠電池供電的邊緣設備,如智能手機、物聯網設備和自動駕駛汽車等,是個嚴重問題。高功耗會導致發熱增加,因此需要有效的熱管理解決方案。在緊湊的邊緣設備進行散熱管理難度大,還可能影響設備壽命和性能。
硬件約束同樣是在邊緣設備上部署GenAI的一大挑戰。與數據中心服務器相比,邊緣設備的處理能力通常有限。選擇既能滿足GenAI的需求、又能兼顧低功耗和高性能的合適處理器至關重要。邊緣設備有限的內存和存儲容量,限制了可部署GenAI模型的規模和復雜性。因此,必須開發能在這些約束條件下運行且性能不受影響的優化模型。
模型優化對于應對這些挑戰至關重要。模型量化(降低模型參數精度)和剪枝(去除冗余參數)等技術,可幫助降低GenAI模型的計算和內存需求。不過,在采用這些技術時需要謹慎,以保證模型的準確性和功能性。開發專門針對邊緣部署優化的模型,能幫助應對部分挑戰。這需要創建GenAI模型的輕量級版本,使其能在邊緣設備上高效運行,同時不降低性能。
軟件和工具鏈支持也很關鍵。在邊緣設備上高效部署GenAI,離不開支持模型優化、部署和管理的強大軟件工具和框架。確保與邊緣硬件兼容并提供高效的開發流水線至關重要。優化推理過程以縮短延遲并提高效率,對實時應用非常重要。這涉及微調模型并利用硬件加速器實現最佳性能。
安全和隱私問題也必須得到妥善解決。確保邊緣設備所處理數據的安全性極為重要。采用魯棒的加密技術和安全的數據處理做法,是保護敏感信息的關鍵。在邊緣設備上本地處理數據,可最大限度地減少將敏感數據傳到云端的需求,有助于解決隱私問題。但同時,也要確保GenAI模型本身不會無意中泄露敏感信息。
通過精心挑選硬件、優化模型并利用先進軟件工具來應對這些挑戰,可讓邊緣設備部署GenAI變得更加可行和有效。這將使眾多應用受益于GenAI的強大能力,同時保留邊緣計算的優勢。
邊緣GenAI的處理器選擇
在邊緣設備上運行GenAI,選擇合適的嵌入式處理器對于克服上述挑戰至關重要。選擇時必須兼顧計算能力、功耗和處理各種AI工作任務的靈活性。
GPU和CPU靈活性高且可編程,適用于廣泛的AI應用。但從功耗角度看,它們可能并非邊緣設備的最佳選擇。尤其是GPU,耗電量大,對電池供電的設備不太友好。
ASIC是針對特定任務優化的硬連線解決方案,具有高能效和高性能。然而,它缺乏靈活性,難以適應不斷發展的AI模型和工作任務。
神經處理單元(NPU)在靈活性和能效之間取得了平衡。NPU(包括新思科技ARC NPX NPU IP)專為AI工作任務設計,針對矩陣乘法和張量運算等運行GenAI模型的關鍵任務,能實現優化的性能。NPU解決方案可編程且功耗低,適合邊緣設備。
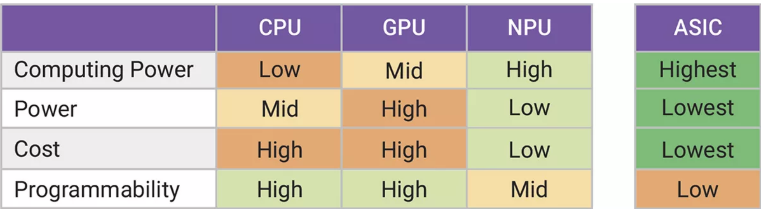
▲圖2:CPU、GPU、NPU和ASIC在邊緣AI/ML中的表現比較。NPU除了可編程性和易于使用之外,還擁有最高效的處理能力。
例如,在NPU上運行Stable Diffusion等GenAI模型僅需2瓦電力,而在GPU上運行則需200瓦,節能效果顯著。NPU還支持混合精度算法和內存帶寬優化等高級功能,對滿足GenAI模型的計算需求至關重要。
結語
向Transformer和生成式人工智能(GenAI)的過渡,是人工智能(AI)和機器學習(ML)領域的重大進步。這些模型性能卓越、功能多樣,支持從自然語言處理到圖像生成的廣泛應用。在邊緣設備上部署GenAI能夠開啟新的可能,提供低延遲、安全、可靠的AI能力。
然而,要充分發揮邊緣GenAI的潛力,必須克服計算復雜性、數據要求、帶寬限制和功耗等挑戰。選擇NPU等合適的處理器,能為邊緣應用提供兼顧性能與能效的平衡解決方案。
隨著AI持續發展,GenAI在邊緣設備上的集成將發揮關鍵作用,有助于推動創新并擴大智能技術的應用范圍。通過克服這些挑戰并利用先進處理器的優勢,我們將為AI全面融入日常生活的美好未來鋪平道路。
-
cpu
+關注
關注
68文章
11279瀏覽量
224964 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265320 -
機器學習
+關注
關注
66文章
8553瀏覽量
136940 -
Transformer
+關注
關注
0文章
156瀏覽量
6937
原文標題:為何要在邊緣設備上部署GenAI?
文章出處:【微信號:Synopsys_CN,微信公眾號:新思科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
戴爾如何構建更敏捷、可靠的邊緣站點
如何在基于Arm架構的邊緣AI設備上部署飛槳模型
有哪些技術可以提高邊緣計算設備的安全性?

部署邊緣計算設備時需要考慮哪些問題?

Arm方案 基于Arm架構的邊緣側設備(樹莓派或 NVIDIA Jetson Nano)上部署PyTorch模型
打通邊緣智能之路:面向嵌入式設備的開源AutoML正式發布----加速邊緣AI創新
無法運行Whisper Asr GenAI OpenVINO? Notebook怎么解決?
使用Openvino? GenAI運行Sdxl Turbo模型時遇到錯誤怎么解決?
stm32N657上部署cubeAI生成代碼,編譯出錯的原因?怎么解決?
邊緣AI實現的核心環節:硬件選擇和模型部署

RAKsmart企業服務器上部署DeepSeek編寫運行代碼
邊緣部署GenAI機遇與挑戰并存,NPU成破局關鍵




 工商網監
工商網監
評論