") BEV感知中的Transformer算法介紹
BEV感知中的Transformer算法介紹

1、Camera only
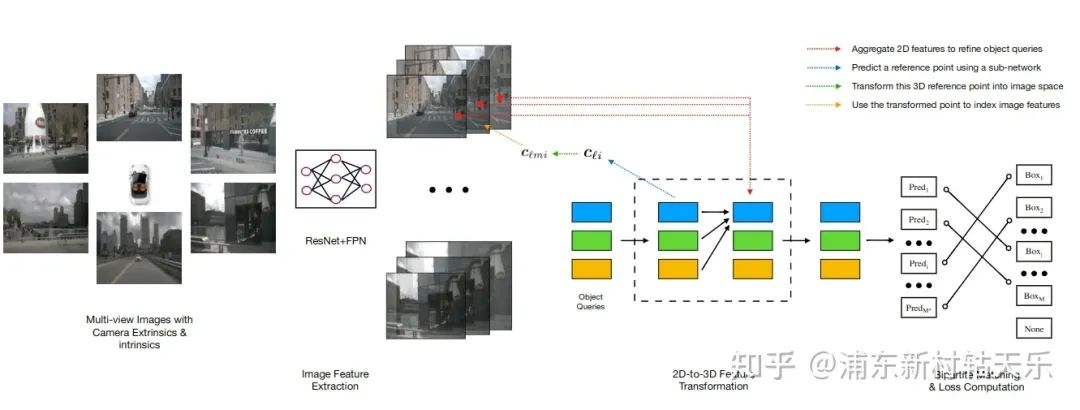
主要思想:固定900個query個數(shù),隨機初始化query。每個query對應一個3D reference point,然后反投影到圖片上sample對應像素的特征。
缺點:需要預訓練模型,且因為是隨機初始化,訓練收斂較慢
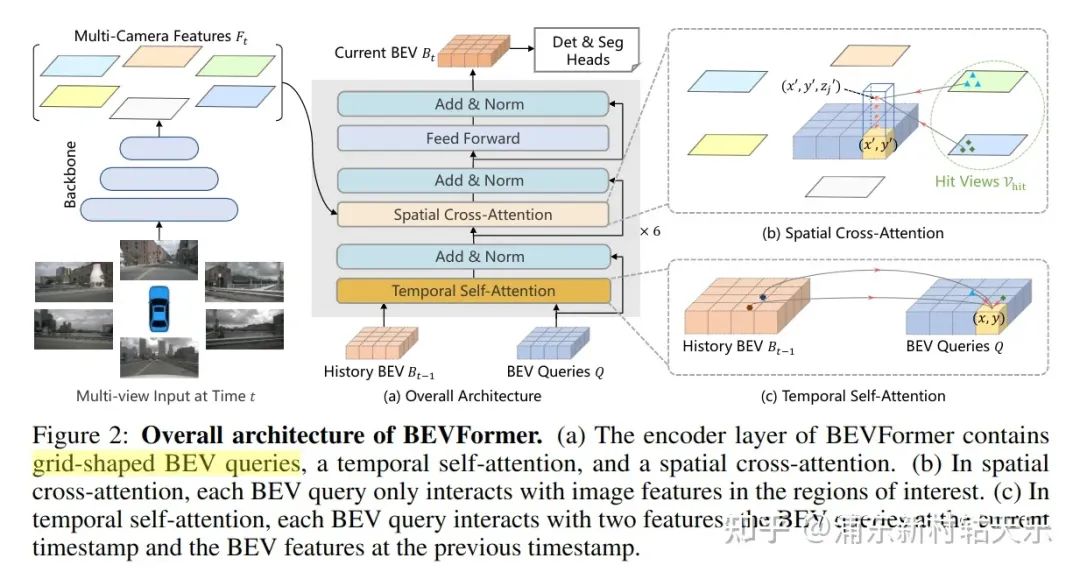
BEV Former
https://arxiv.org/abs/2203.17270
主要思想:將BEV下的每個grid作為query,在高度上采樣N個點,投影到圖像中sample到對應像素的特征,且利用了空間和時間的信息。并且最終得到的是BEV featrue,在此featrue上做Det和Seg。
Spatial Cross-Attention:將BEV下的每個grid作為query,在高度上采樣N個點,投影到圖像中獲取特征。
Temporal Self-Attention: 通過self-attention代替運動補償,align上一幀的feature到當前幀的Q
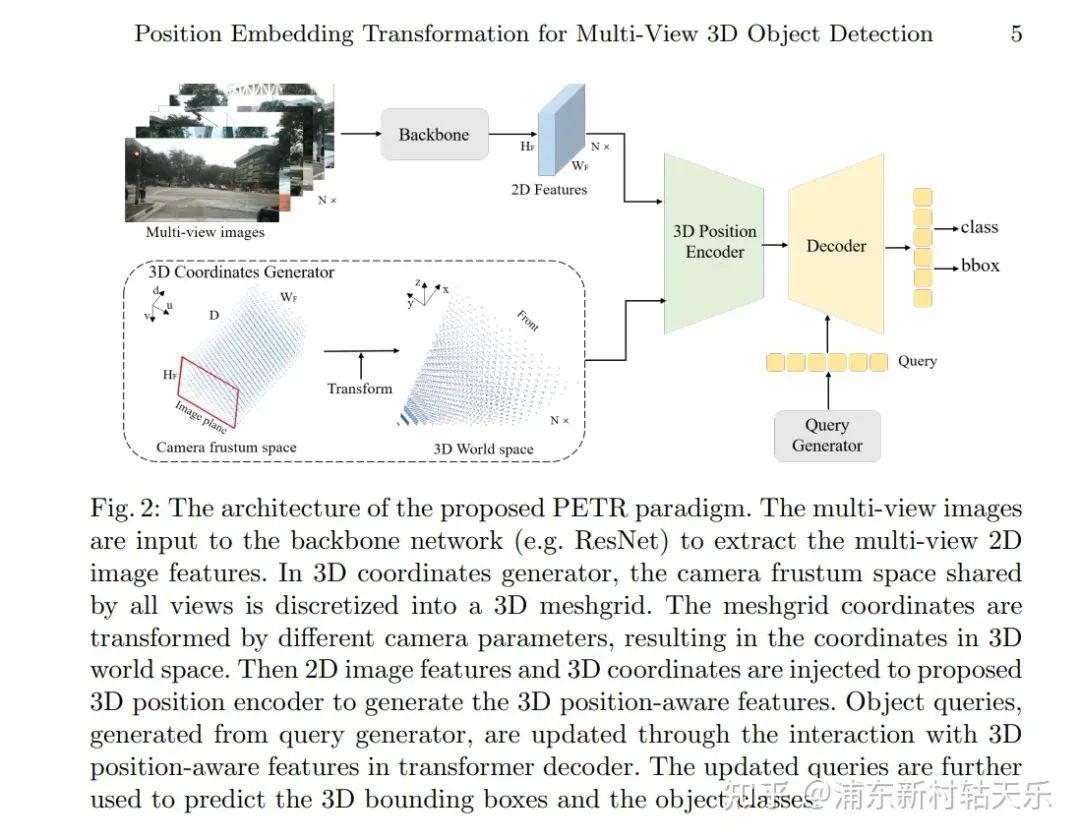
曠視,PETR
https://arxiv.org/pdf/2203.05625.pdf
2、多模態(tài)
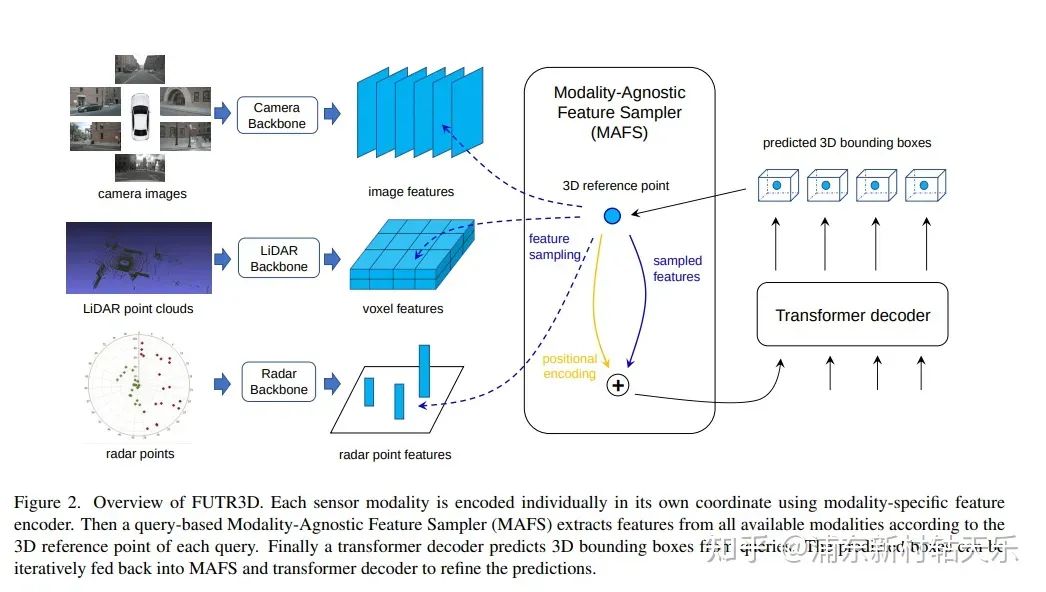
清華,F(xiàn)UTR3D
https://arxiv.org/pdf/2203.10642.pdf
在DETR的基礎上,將3D reference point投影到Lidar voxel特征和radar point 特征上。
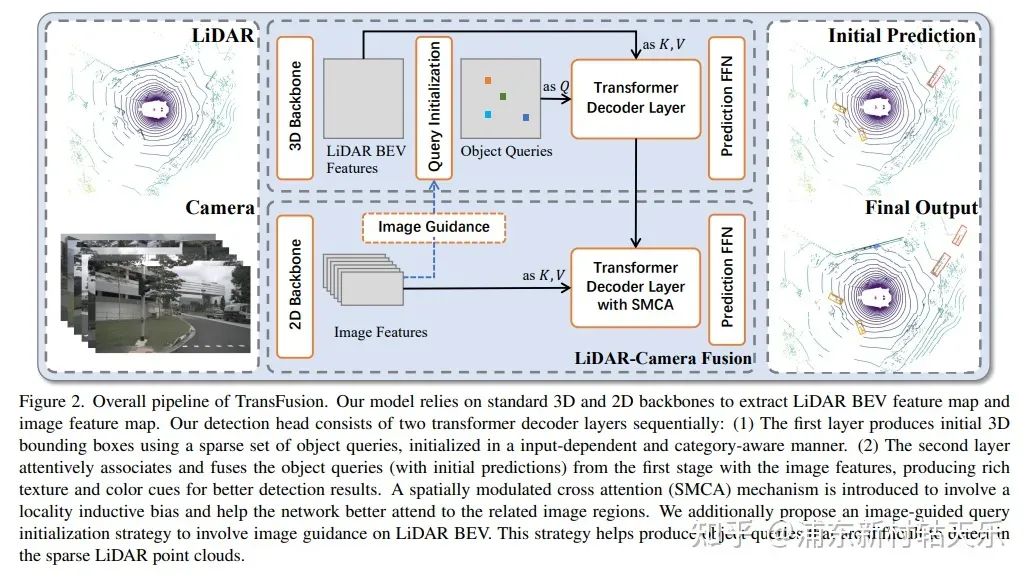
香港科技大學,Transfusion
https://arxiv.org/pdf/2203.11496.pdf
利用CenterPoint在heatmap上獲取Top K個點作為Query(這K個點可以看做是通過lidar網(wǎng)絡初始化了每個目標的位置,這比DETR用隨機點作為Qurey收斂要快),先經(jīng)過Lidar Transformer得到proposal,把這個proposal作為Query,再和image feature做cross attention。
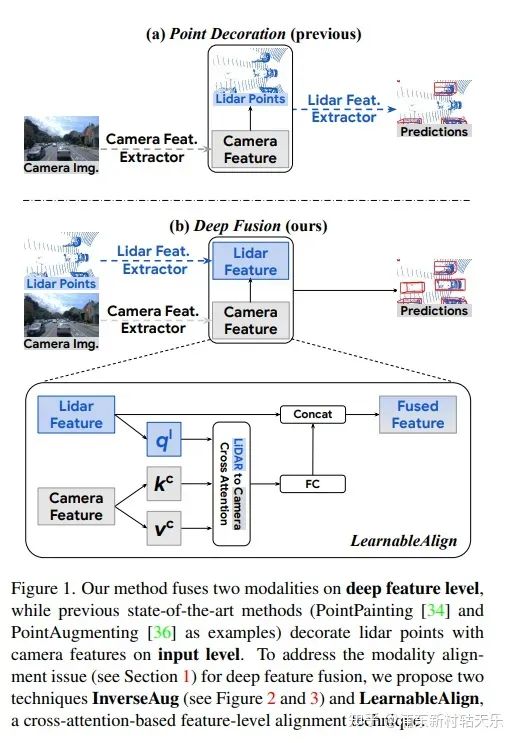
Google,DeepFusion
https://arxiv.org/abs/2203.08195
直接將Lidar feature和Camera feature做cross attention,這個思路牛逼,我不看到這篇論文是絕對想不到還能這么搞的。
編輯:黃飛
-
算法
+關注
關注
23文章
4787瀏覽量
98282 -
感知
+關注
關注
1文章
78瀏覽量
12703 -
Transformer
+關注
關注
0文章
156瀏覽量
6949
原文標題:BEV感知中的Transformer算法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
基于LSS范式的BEV感知算法優(yōu)化部署詳解

BEV感知算法:下一代自動駕駛的核心技術
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
BEV+Transformer對智能駕駛硬件系統(tǒng)有著什么樣的影響?
黑芝麻智能在BEV感知方面的研發(fā)進展
基于幾何變換器的2D-to-BEV視圖轉換學習
基于Transformer的目標檢測算法

BEV人工智能transformer
CVPR上的新頂流:BEV自動駕駛感知新范式

利用Transformer BEV解決自動駕駛Corner Case的技術原理
智能駕駛感知算法梳理 高階自動駕駛落地關鍵分析

基于Transformer的多模態(tài)BEV融合方案
黑芝麻智能開發(fā)多重亮點的BEV算法技術 助力車企高階自動駕駛落地

自動駕駛中一直說的BEV+Transformer到底是個啥?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論