") 基于LSS范式的BEV感知算法優(yōu)化部署詳解
基于LSS范式的BEV感知算法優(yōu)化部署詳解

簡介
BEV即Bird's Eye View(鳥瞰視圖)是一種從空中俯視場景的視角。由多張不同視角采集的圖像通過不同的空間轉(zhuǎn)換方式形成,如下圖所示,左側(cè)為6張不同位置的相機(jī)采集的圖像,右側(cè)為轉(zhuǎn)換的BEV圖像。

BEV感知模型指的是直接輸出BEV坐標(biāo)系下的感知結(jié)果,如動(dòng)靜態(tài)檢測目標(biāo),車道線,路面標(biāo)識等。BEV坐標(biāo)系好處是:
1. 成本低。相比3D點(diǎn)云的方式來補(bǔ)充3維信息,純視覺方案的成本更低;
2. 可以直接給到下游任務(wù),例如預(yù)測和規(guī)劃;
3. 可以在模型中融合各視角的特征,提升感知效果;
4. 可以更好的和各類傳感器進(jìn)行融合。
對于下游的預(yù)測和規(guī)控任務(wù)而言,需要的是3D的目標(biāo),因此在傳統(tǒng)的自動(dòng)駕駛方案中,2D的感知推理結(jié)果需要通過復(fù)雜的后處理去解決3D坐標(biāo)提升的問題。而BEV感知模型是更接近于一種端到端的解決方案。
當(dāng)前主要的BEV 轉(zhuǎn)換方式為以下三種:
? IPM-based:基于地面平坦假設(shè)的逆透視映射方式,技術(shù)簡單成本低,但是對上下坡情況擬合效果不好。
? LSS-based:通過顯示的深度估計(jì)方式構(gòu)建三維視錐點(diǎn)云特征,也是較常用的轉(zhuǎn)換方式。
? Transformer-based:用transformer機(jī)制學(xué)習(xí)3D query和2D 圖像特征之間的關(guān)系來建模。部署時(shí)global attention的計(jì)算量較大, 需要考慮端側(cè)運(yùn)行時(shí)對性能的影響。
在實(shí)際部署時(shí),需要考慮算法的端側(cè)性能。地平線的參考算法目前已賦能多家客戶實(shí)現(xiàn)BEV感知算法在征程5上的部署和開發(fā),多家客戶已實(shí)現(xiàn)BEV demo開發(fā)。本文以LSS范式的BEV感知算法為例,介紹地平線提供的參考算法如何在公版的基礎(chǔ)上做算法在征程5芯片的適配和模型的優(yōu)化。
整體框架
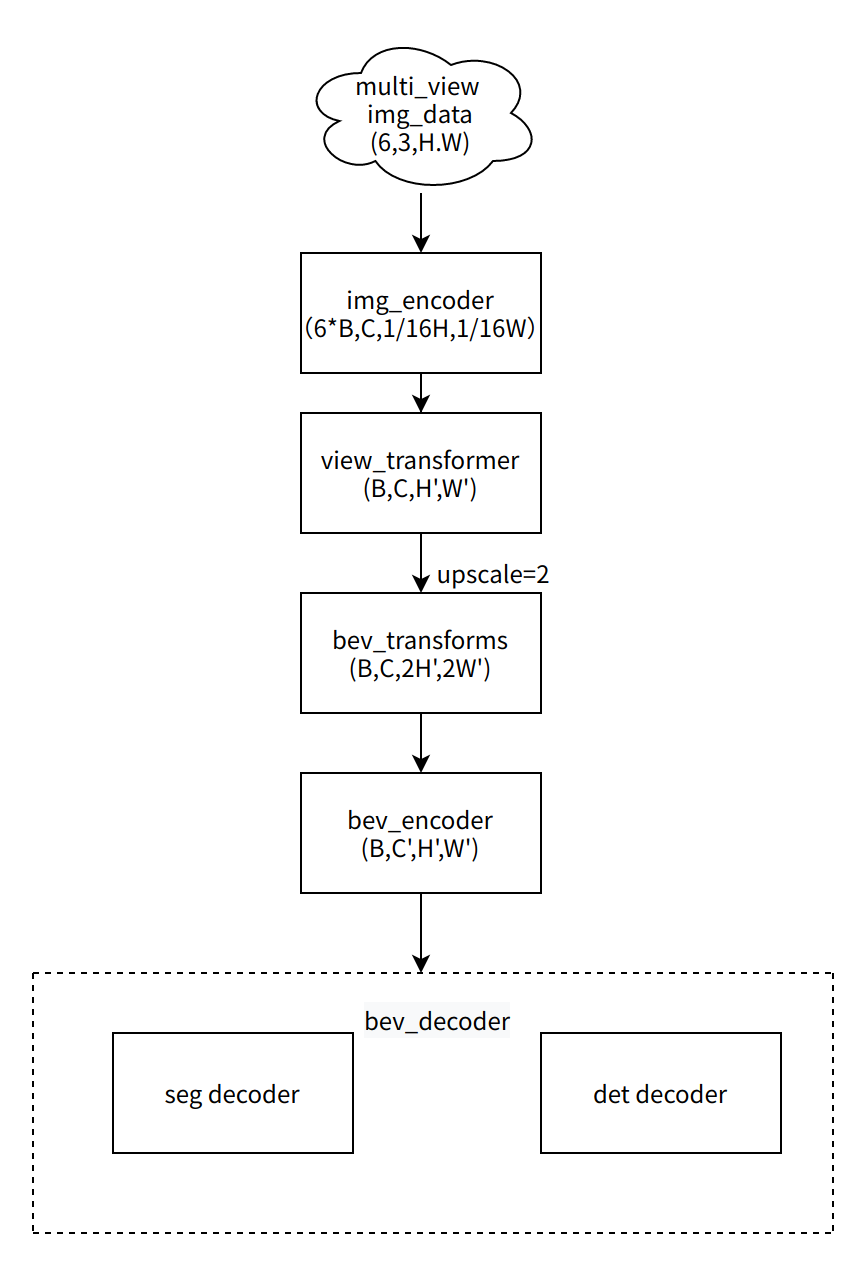
BEV 感知架構(gòu)
BEV系列的模型使用多視圖的當(dāng)前幀的6個(gè)RGB圖像作為輸入。輸出是目標(biāo)的3D Box和BEV分割結(jié)果。多視角圖像首先使用2D主干獲取2D特征。然后投影到3D BEV視角。接著對BEV feature 編碼獲取BEV特征。最后,接上任務(wù)特定的head,輸出多任務(wù)結(jié)果。模型主要包括以下部分:
Part1—2D Image Encoder:圖像特征提取層。使用2D主干網(wǎng)絡(luò)(efficientnet)和FastSCNN輸出不同分辨率的特征圖。返回最后一層--上采樣至1/16原圖大小層,用于下一步投影至3D BEV坐標(biāo)系中;
Part2—View transformer:采用不同的轉(zhuǎn)換方式完成圖像特征到BEV 3D特征的轉(zhuǎn)換;
Part3—BEV transforms:對BEV特征做數(shù)據(jù)增強(qiáng),僅發(fā)生在訓(xùn)練階段;
Part4—3D BEV Encoder:BEV特征提取層;
Part5—BEV Decoder:分為Detection Head和Segmentation Head。
LSS方案
公版的LSS方案如下:
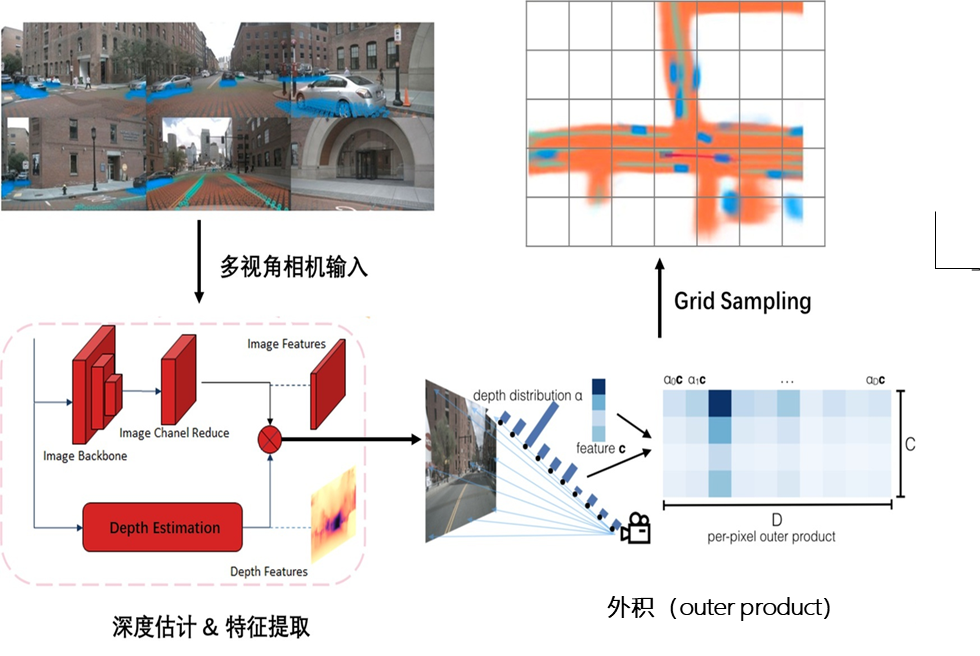
公版的LSS方案分為3個(gè)部分:
1. 將圖像從2d平面提升到3d空間,生成3d視錐(frustum)點(diǎn)云,并對點(diǎn)云上所有的點(diǎn)預(yù)測context特征,生成context特征點(diǎn)云;
2. 對視錐點(diǎn)云和context特征點(diǎn)云進(jìn)行 “Splat” 操作,在BEV網(wǎng)格中構(gòu)建BEV特征;
3. BEV特征后,可通過“Shooting”完成特定的下游任務(wù),比如Motion Planning。
模型部署分析
在部署之前,需要對公版模型做部署分析,避免模型中有BPU無法支持的算子和某些對性能影響較大的算子。對于無法支持的算子,需要做替換;對于影響性能的算子需要做優(yōu)化。同時(shí)為了達(dá)到更好的精度會增加訓(xùn)練策略的優(yōu)化和量化策略的優(yōu)化。本章節(jié)先對公版模型做部署分析,最后給出地平線的優(yōu)化方式。
問題1 大尺寸運(yùn)算導(dǎo)致性能瓶頸
由于深度特征的增加,feature的維度是高于4維的,考慮到transpose算子的耗時(shí)問題和部署問題,LSS方案中會存在維度的折疊,對feature做view和H維度的折疊。對應(yīng)的操作為:depth_feature會做view和Dim、H和W的折疊。維度折疊會導(dǎo)致feature的維度變大,在生成視錐點(diǎn)云時(shí),其涉及的操作mul操作的輸入也就增大了,在做部署時(shí)會導(dǎo)致DDR帶寬問題。因此公版的步驟1中的大尺寸算子計(jì)算需要做對應(yīng)的優(yōu)化。
問題2 BEVpooling的索引操作支持問題
公版在做2D到3D轉(zhuǎn)換時(shí),從圖像空間的index映射到BEV空間的index,相同的BEV空間index相加后再賦值到BEV tensor上,即公版的步驟二。考慮到征程5對索引操作無法支持,因此該操作在部署時(shí)需要做替換。
問題3 分割頭粒度太粗
地平線提供的是多任務(wù)的BEV感知算法,對于多任務(wù)模型來說不同的任務(wù)需要特定的范圍和粒度,特別是對于分割模型來說,分割的目標(biāo)的粒度較小,因此相比于檢測任務(wù)來說feature需要細(xì)化,即用更大的分辨率來表示。
問題4 grid 量化精度誤差問題
對于依賴相機(jī)內(nèi)外參的模型來說,轉(zhuǎn)換時(shí)的點(diǎn)坐標(biāo)極其重要,因此需要保障該部分的精度。同時(shí)grid的表示范圍需要使用更大比特位的量化。
針對以上4個(gè)問題,本章節(jié)會介紹該部分在征程5的實(shí)現(xiàn)方式使其可以在板端部署并高速運(yùn)行。
性能優(yōu)化
mul的性能優(yōu)化
為了減少大量的transpose操作和優(yōu)化mul算子的耗時(shí)問題, 我們選擇把深度和 feature 分別做grid_sample后執(zhí)行mul操作,具體操作如下:
Python #depth B, N, D,H, W depth = tensor(B,N,D,H,W) feat = tensor(B,N,C,H,W) #depth B, 1, N *D, H*W depth = depth.view(B, 1, N*D, H*W) #feat -> B,C,N,H,W-> B, C, N*H, W feat = feat.permute(0, 2, 1, 3, 4).view(B, C, N*H, W) for i in range(self.num_points): homo_feat = self.grid_sample( feat, fpoints[i * B : (i + 1) * B], ) homo_dfeat = self.dgrid_sample( dfeat, dpoints[i * B : (i + 1) * B], ) homo_feat = self.floatFs.mul(homo_feat, homo_dfeat) homo_feats.append(homo_feat)
mul操作的計(jì)算量大幅減少,性能上提升4~5倍!
BEV_pooling部署優(yōu)化
使用grid_sample代替公版的3D空間轉(zhuǎn)換。即從原來的前向wrap-從圖像空間特征轉(zhuǎn)換到BEV空間特征,改為從BEV空間拉取圖像空間特征。
公版實(shí)現(xiàn):
a.通過一個(gè)深度估計(jì)變成6D的tensor
Python volume = depth.unsqueeze(1) * cvt_feature.unsqueeze(2) volume = volume.view(B, N, volume_channel_index[-1], self.D, H, W) volume = volume.permute(0, 1, 3, 4, 5, 2)
b.從圖像空間的index映射到BEV空間的index,相同的BEV空間index相加后再賦值到BEV tensor上
Python
def voxel_pooling(self, geom_feats, x):
...
# flatten x
x = x.reshape(Nprime, C)
# flatten indices
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long()
geom_feats = geom_feats.view(Nprime, 3)
...
# filter out points that are outside box
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < nx[0])
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < nx[1])
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < nx[2])
geom_feats = geom_feats[kept]
x = x[kept]
...
# argsort and get tensors from the same voxel next to each other
ranks = geom_feats[:, 0] * (nx[1] * nx[2] * B)
+ geom_feats[:, 1] * (nx[2] * B)
+ geom_feats[:, 2] * B
+ geom_feats[:, 3]
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]
...
return final
2. 地平線實(shí)現(xiàn):
使用grid_sample代替公版的3D空間轉(zhuǎn)換。grid_sample為采樣算子,通過輸入圖像特征和2D點(diǎn)坐標(biāo)grid,完成圖像特征到BEV特征的轉(zhuǎn)換,其工作原理見下圖。
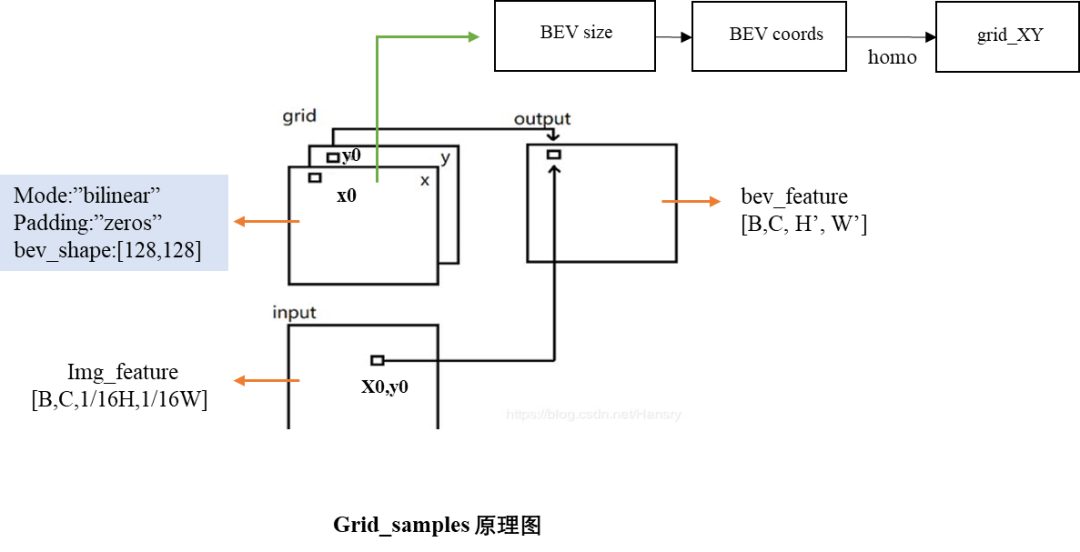
Grid_Samples 原理圖
horizon_plugin_pytorch提供的grid_sample算子和公版輸入略有差異,地平線已支持公版的grid_sample算子。
由于該轉(zhuǎn)換方式是前向映射,前向映射會產(chǎn)生的BEV index并不均勻,最多的一個(gè)voxel有100多個(gè)點(diǎn),最少有效點(diǎn)為0。我們在提供的源代碼中使用了每個(gè)voxel使用了10個(gè)點(diǎn),如果想要提升精度可以考慮增加每個(gè)voxel的有效點(diǎn)。
Python
#num_point為10
for i in range(self.num_points):
homo_feat = self.grid_sample(
feat,
fpoints[i * B : (i + 1) * B],
)
homo_dfeat = self.dgrid_sample(
dfeat,
dpoints[i * B : (i + 1) * B],
)
homo_feat = self.floatFs.mul(homo_feat, homo_dfeat)
homo_feats.append(homo_feat)
精度優(yōu)化
多任務(wù)模型的精度優(yōu)化
參考BEVerse模型對多任務(wù)根據(jù)不同粒度進(jìn)行細(xì)化,在分割頭做解碼之前,將BEV feature的分辨率增大,map size為[200,400],實(shí)現(xiàn)上由grid_sample完成。
Python
#init map module
if (self.bev_size and self.task_size and self.task_size != self.bev_size):
self.grid_sample = hnn.GridSample(
mode="bilinear",
padding_mode="zeros",
)
#decoder module forward
def forward(self, feats: Tensor, meta: Dict) -> Any:
feat = feats[self.task_feat_index]
if hasattr(self, "grid_sample"):
batch_size = feat.shape[0]
new_coords = self.new_coords.repeat(batch_size, 1, 1, 1)
feat = self.grid_sample(feat, self.quant_stub(new_coords))
feat = [feat]
pred = self.head(feat)
return self._post_process(meta, pred)
浮點(diǎn)模型精度的優(yōu)化
在浮點(diǎn)模型的訓(xùn)練上,使用數(shù)據(jù)增強(qiáng)來增強(qiáng)模型的泛化能力,通過嘗試不同的增強(qiáng)方式,最終選取BEVRotate方式對輸入數(shù)據(jù)做transform。相比于未做數(shù)據(jù)增強(qiáng)的浮點(diǎn)模型mAP提升1.5個(gè)點(diǎn),NDS提升0.6個(gè)點(diǎn)。詳細(xì)實(shí)驗(yàn)記錄見實(shí)驗(yàn)結(jié)果章節(jié)。

該實(shí)驗(yàn)結(jié)果為中間結(jié)果,非最終精度數(shù)據(jù)
量化精度的優(yōu)化
BEV_LSS的量化訓(xùn)練采用horizon_plugin_pytorch的Calibration方式來實(shí)現(xiàn)的,通過插入偽量化節(jié)點(diǎn)對多個(gè)batch的校準(zhǔn)數(shù)據(jù)基于數(shù)據(jù)分布特征來計(jì)算量化系數(shù),從而達(dá)到模型的量化。BEV_LSS模型無需QAT訓(xùn)練就可以達(dá)到和浮點(diǎn)相當(dāng)?shù)木取?/p>
除了量化方式上的優(yōu)化,地平線對輸入的grid也做了優(yōu)化,包括了
1. 手動(dòng)計(jì)算scale,使用固定的scale作為grid的量化系數(shù)。
Python
#fix scale
def get_grid_quant_scale(grid_shape, view_shape):
max_coord = max(*grid_shape, *view_shape)
coord_bit_num = math.ceil(math.log(max_coord + 1, 2))
coord_shift = 15 - coord_bit_num
coord_shift = max(min(coord_shift, 8), 0)
grid_quant_scale = 1.0 / (1 << coord_shift)
return grid_quant_scale
#get grid_quant_scale
grid_quant_scale = get_grid_quant_scale(grid_size, featview_shape)
##init
self.quant_stub = QuantStub(grid_quant_scale)
2.grid_sample算子的輸入支持int16量化,為了保障grid的精度,地平線選擇int16量化。
Python
self.quant_stub.qconfig = qconfig_manager.get_qconfig(
activation_qat_qkwargs={"dtype": qint16, "saturate": True},
activation_calibration_qkwargs={"dtype": qint16, "saturate": True},
)
基于以上對量化精度的優(yōu)化后,最終定點(diǎn)精度達(dá)到和浮點(diǎn)相當(dāng)?shù)乃剑?strong>量化精度達(dá)到99.7%!
實(shí)驗(yàn)結(jié)果
1.性能和精度數(shù)據(jù)
| 數(shù)據(jù)集 | Nuscenes | |
| Input shape | 256x704 | |
| backbone | efficientnetb0 | |
| bev shape | 128x128 | |
| FPS(單核) | 138 | |
| latency(ms) | 8.21 | |
| 分割精度(浮點(diǎn)/定點(diǎn))iou | divider | 46.55/47.45 |
| ped_crossing | 27.91/28.44 | |
| Boundary | 47.06/46.03 | |
| Others | 85.59/84.49 | |
| 檢測精度(浮點(diǎn)/定點(diǎn)) | NDS | 0.3009/0.3000 |
| mAP | 0.2065/0.2066 | |
注:grid_sample的input_feature H,W ∈ [1, 1024] 且 H*W ≤ 720*1024
2. 不同數(shù)據(jù)增強(qiáng)方式對浮點(diǎn)模型的精度影響。
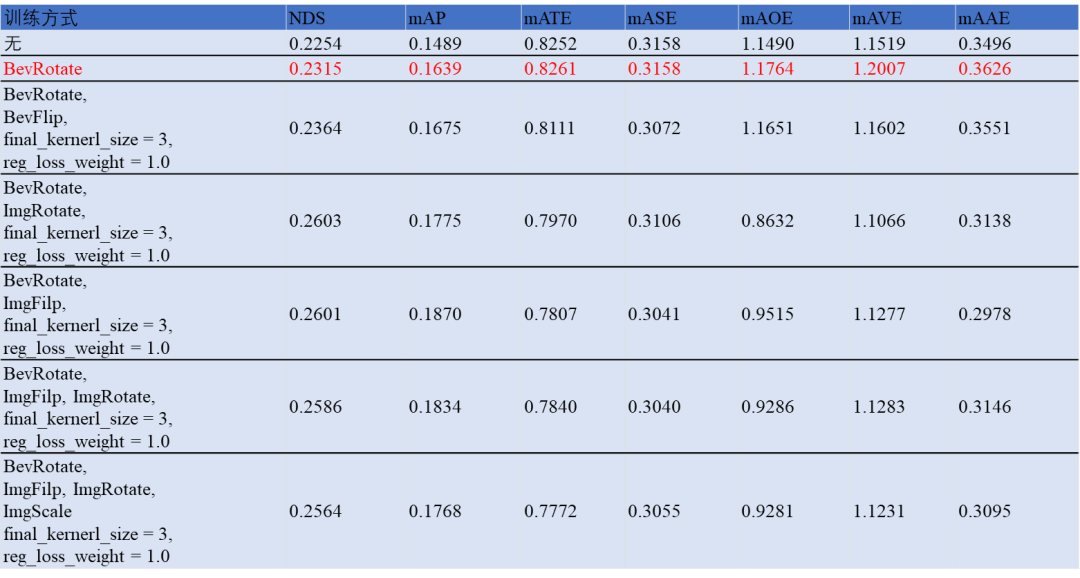
該實(shí)驗(yàn)結(jié)果為中間結(jié)果,非最終精度數(shù)據(jù)
3.地平線征程5部署LSS范式的BEV模型通用建議
?選用BPU高效支持的算子替換不支持的算子。
? num_point會直接影響性能和精度,可以根據(jù)需求做權(quán)衡。處于訓(xùn)練速度考慮使用topk選擇點(diǎn),若想要更高的精度可以對點(diǎn)的選擇策略做優(yōu)化。
? grid使用fixed scale來保障量化精度,如超過int8表示范圍則開啟int16量化,具體見grid量化精度優(yōu)化章節(jié)。
?對于分辨率較大導(dǎo)致帶寬瓶頸或不支持問題,可以拆分為多個(gè)計(jì)算,緩解帶寬壓力,保障模型可以順利編譯。
?對于常量計(jì)算(例如:grid計(jì)算)編譯時(shí)可以作為模型的輸入,提升模型的運(yùn)行性能。
總結(jié)
本文通過對LSS范式的BEV多任務(wù)模型在地平線征程5上量化部署的優(yōu)化,使得模型在該計(jì)算方案上用遠(yuǎn)低于1%的量化精度損失,得到latency為8.21ms的部署性能,同時(shí),通過LSS范式的BEV模型的部署經(jīng)驗(yàn),可以推廣到基于該范式的BEV模型的優(yōu)化中,以便更好的在端側(cè)部署。
審核編輯:劉清
-
NDS
+關(guān)注
關(guān)注
0文章
6瀏覽量
6886 -
LSS
+關(guān)注
關(guān)注
0文章
8瀏覽量
2199 -
pytorch
+關(guān)注
關(guān)注
2文章
813瀏覽量
14899
原文標(biāo)題:好算法更要配好用的芯片 —— 基于LSS范式的BEV感知算法優(yōu)化部署詳解
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
BEV感知算法:下一代自動(dòng)駕駛的核心技術(shù)
基于改進(jìn)群搜索優(yōu)化算法的認(rèn)知無線電協(xié)作頻譜感知
認(rèn)知無線網(wǎng)絡(luò)中多信道頻譜感知周期優(yōu)化算法_劉洋
基于粒子群優(yōu)化算法的水質(zhì)傳感器優(yōu)化部署研究_余幸運(yùn)
云計(jì)算中能耗和性能感知的虛擬機(jī)優(yōu)化部署算法
基于粒子群優(yōu)化PSO算法的部署策略
基于二項(xiàng)感知覆蓋的自適應(yīng)虛擬力粒子群優(yōu)化算法
LSS的功能介紹,它的應(yīng)用都有哪些

黑芝麻智能在BEV感知方面的研發(fā)進(jìn)展
Sparse4D系列算法:邁向長時(shí)序稀疏化3D目標(biāo)檢測的新實(shí)踐

CVPR上的新頂流:BEV自動(dòng)駕駛感知新范式

BEV感知中的Transformer算法介紹

BEV感知的二維特征點(diǎn)
Nullmax揭秘BEV-AI技術(shù)架構(gòu)加速量產(chǎn)方案演進(jìn)
黑芝麻智能開發(fā)多重亮點(diǎn)的BEV算法技術(shù) 助力車企高階自動(dòng)駕駛落地




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論