") NVIDIA 攜手騰訊開發(fā)和優(yōu)化 Spark UCX 實現(xiàn)性能躍升
NVIDIA 攜手騰訊開發(fā)和優(yōu)化 Spark UCX 實現(xiàn)性能躍升

什么是 Spark 平臺?
TDW-Spark 是騰訊公司級數(shù)據(jù)平臺,是騰訊海量數(shù)據(jù)處理平臺中最核心的模塊,支持百 PB 級的數(shù)據(jù)存儲和計算,業(yè)務涉及公司各個 BG,為騰訊公司提供海量、高效、穩(wěn)定的大數(shù)據(jù)平臺支撐和決策支持,是騰訊公司最大的離線數(shù)據(jù)處理平臺。
Spark 業(yè)務所面臨的挑戰(zhàn)
Spark 網絡目前的現(xiàn)狀包括大規(guī)模部署 QP 連接數(shù)不夠用,使用 RDMA DC 解決連接數(shù)過多的問題;Spark 不同應用場景需要不同的 EP 個數(shù)、RPC 調用次數(shù)、Spark UCX 線程數(shù)、Block 大小等,需要聯(lián)合調配;RDMA 和 TCP 混合部署,需要兼容和故障逃生;以及網絡帶寬低,需要提升帶寬,降低延時。
Spark 原始的業(yè)務問題包括:
-
通信耗時占比高:Spark Shuffle 時間占 Spark 運行總時間的 30% - 40%,造成 Spark 任務完成時間長。
-
業(yè)務需求:網絡 IO 和磁盤 IO 是 Spark Shuffle 的瓶頸,需要提高通信效 率,提高計算效率。
-
降本增效:五萬張已經部署的 NVIDIA ConnectX-5 網卡需要提高性能利用率,切換到 RDMA,提高業(yè)務帶寬。
為了應對上述問題及挑戰(zhàn),騰訊進行了 Spark RDMA 大規(guī)模部署網絡的工作,主要從兩個方面著手:Spark RDMA 網絡部署和優(yōu)化,以及 Spark UCX / UCX 性能優(yōu)化。
Spark RDMA 網絡部署和調優(yōu)
具體部署調優(yōu)步驟:
-
搭建 37 節(jié)點 NVIDIA ConnectX-5 網卡和 26 節(jié)點 NVIDIA ConnectX-6 網卡 Spark 環(huán)境,部署 Spark、Spark UCX、UCX 代碼進行長穩(wěn)調優(yōu)。
-
基于 GroupByTest 和現(xiàn)網 Spark 業(yè)務流量,在 UCX、Spark UCX、Spark 三個層次調優(yōu)對比 DC、RC 和 TCP 效果。
-
優(yōu)化 Spark UCX、UCX 代碼,根據(jù) Spark 業(yè)務調優(yōu)網卡和交換機配置。
-
通過在 NVIDIA ConnectX-5 和 NVIDIA ConnectX-6 Dx bond 引入 DCT,提升 Spark 業(yè)務帶寬利用率。
-
RDMA 和 TCP 網絡共存的情況下,保障長穩(wěn)運行和 RDMA 故障逃生。
圖 1:37 節(jié)點的 ConnectX-5 機群與 26 節(jié)點的 ConnectX-6 機群
RDMA 部署優(yōu)化完成情況:
-
大規(guī)模:使用 DCT 技術共享 QP 連接,解決了大規(guī)模 QP 不夠用 的問題。大規(guī)模仿真下 Spark 應用 RDMA 網絡滿足預期。
-
Spark 應用和網絡聯(lián)合調優(yōu):實現(xiàn)了最優(yōu)的網卡和交換機配置,以 及 Spark 任務配置,降低了 15% - 20% 左右的讀完成時間。
-
故障逃生:Spark UCX 和 UCX 代碼層面實現(xiàn)了 RDMA 和 TCP 通道備份。確保 RDMA 故障逃生 TCP,保證穩(wěn)定運行。
-
穩(wěn)定性保證:開發(fā)了驅動版本檢測、網卡配置和檢測、自動化安裝升級檢測功能。開發(fā)了測試網絡性能模塊,保證 Spark RDMA 各層帶寬和延時滿足預期。
Spark UCX 性能優(yōu)化
1. 參數(shù)調優(yōu):通過調整 maxReqsInFlight、numListenerThreads 等 Spark / Spark UCX 參數(shù),提升任務執(zhí)行效率,獲得最好傳輸速率,發(fā)揮最大系統(tǒng)效能。
2. CPU 利用率優(yōu)化:啟用 sleep / wakeup 特性,替代 busy waiting 模式。讓出 CPU 給 Spark 計算任務,減少了 CPU 浪費,體現(xiàn)了 RDMA 的優(yōu)勢。
3. 網路 IO 優(yōu)化:網路 IO 由阻塞模型改為非阻塞模型,數(shù)據(jù)接收由同步等待改為異步通知。避免了因為網路 IO 等待而 阻塞計算任務執(zhí)行,提高了每個線程的任務吞吐量,提升了收發(fā)效率和帶寬。
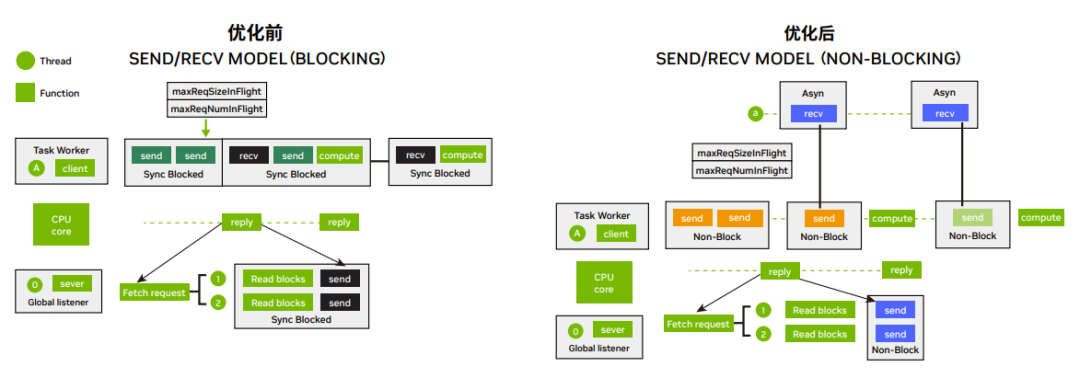
圖 2:網絡 IO 優(yōu)化
4. 調度優(yōu)化:worker 的調度方式改用全局 round-robin (RR) 調度模式,替代原有的按照 thread id 選擇 worker 的 方式。避免了 thread id 不連續(xù)引起的多個線程選擇同一 worker 的問題。
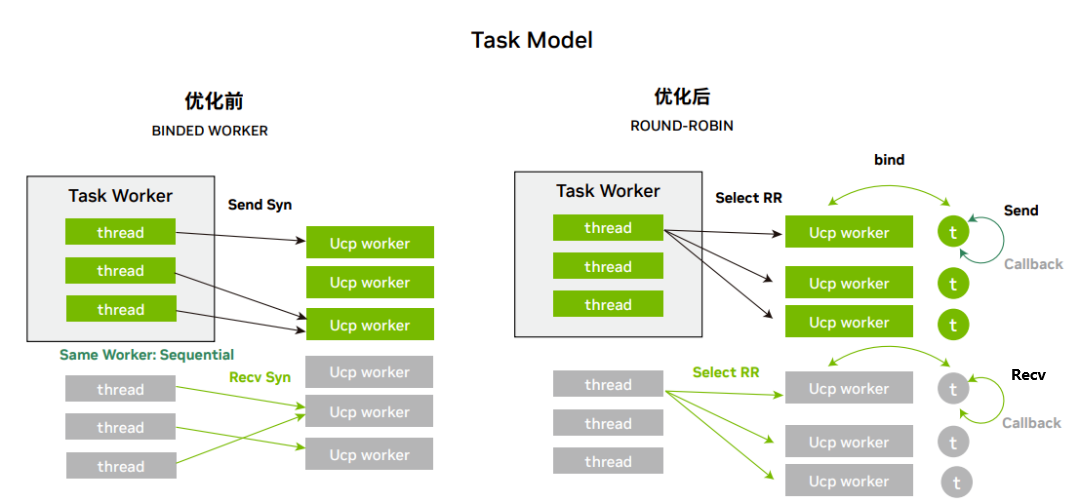
圖 3:調度優(yōu)化
5. 數(shù)據(jù)競爭優(yōu)化:將 send / receive / progress 方法打包至獨立線程運行,保證每個 worker 資源僅被單個線程 訪問 / 修改,避免了數(shù)據(jù)競爭,提升了線程運行效率。
UCX 性能優(yōu)化
1. 參數(shù)調優(yōu):使用 DC 替換 RC 模式,提升傳輸帶寬,減少系統(tǒng) CPU、內存資源消耗。開啟 CQE zipping 和 PCI relax ordering 減少 PCI 負載。調整 UCX_ZCOPY_THRESH、UCX_RNDV_THRESH 和 UCX_RND_SCHEME,獲得穩(wěn)定高速的傳輸帶寬。
2. 網絡負載均衡優(yōu)化:隨機化 UDP 源端口取值,減輕由于固定端口,交換機對 5 元組哈希得到相同出端口而引起的 負載不均衡問題,優(yōu)化網絡傳輸帶寬。
“Spark UCX 是 Apache Spark 的高性能 Shuffle Manager 插件,它使用 UCX 支持的 RDMA 和其他高性能傳輸來加速 Spark 作業(yè)中的 Shuffle 數(shù)據(jù)傳輸。RDMA DC(動態(tài)連接)是一種傳輸服務,旨在解決大型系統(tǒng)在使用可靠連接時的可擴展性問題。使用 DC,用戶可以打開有限數(shù)量的資源,無論集群大小如何。這一優(yōu)勢對于 Spark 如此大規(guī)模的應用程序來說非常有好處,并且可以提高性能。”
——Amit Krig
SVP, Software Engineering & Israel R&D Site Leader, NVIDIA
部署調優(yōu)后性能提升明顯
經過部署調優(yōu),NVIDIA ConnectX-6 環(huán)境 RDMA 傳輸性能比 TCP 平均有 18% 的提升;NVIDIA ConnectX-5 環(huán)境大部分場景 RDMA 傳輸性能比 TCP 平均有 16% 的提升。考慮到 Spark 任務有計算和本地 write,所以對 Spark 任務整體完成時間大概有 8% 的性能提升。
NVIDIA ConnetX-6 環(huán)境 RDMA 性能提升明顯(RDMA read 通信 18% 左右提升,整體完成時間 8% 左右提升),可以大規(guī)模灰度部署 Spark 業(yè)務真實流量。NVIDIA ConnectX-5 環(huán)境大部分場景性能平均提升(RDMA read 通信 16% 左右提升,整體完成時間 6% 左右提升),部分場景 RDMA 性能較差還需要調測優(yōu)化,可以灰度部署 Spark 業(yè)務,繼續(xù)優(yōu)化還有提升空間。
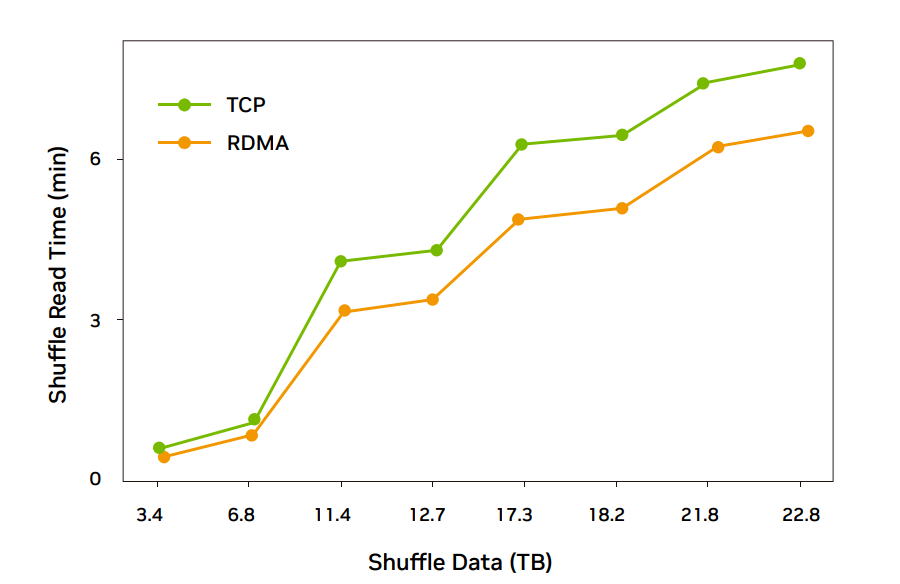
圖 4:ConnectX-6 網卡 26 臺規(guī)模 RDMA 完成時間比 TCP 低 20% 左右
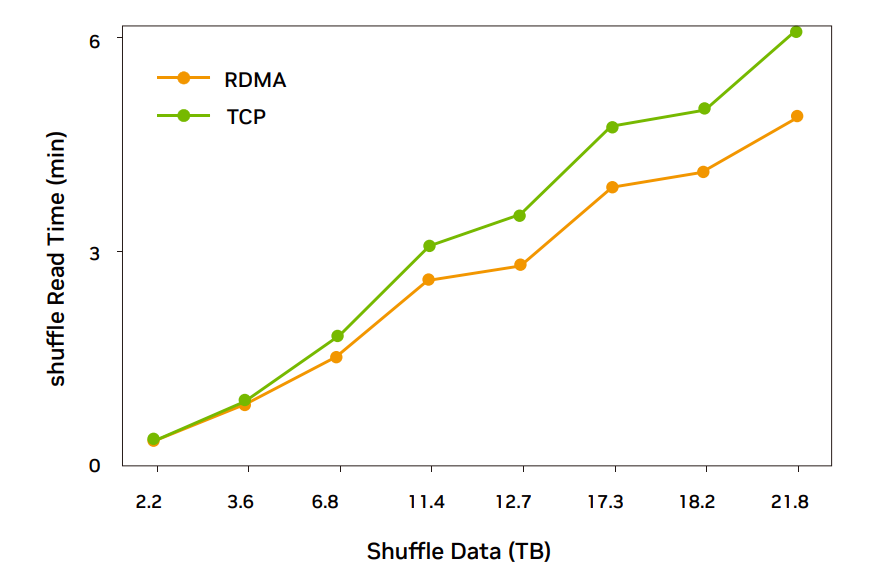
圖 5:ConnectX-5 網卡 37 臺規(guī)模 RDMA 完成時間比 TCP 低 18% 左右

圖 6:20 臺規(guī)模 Spark 業(yè)務灰度測試,RDMA read 平均降低 20% 左右
后期計劃
Spark 項目通過遠程直接內存訪問(RDMA)技術解決網絡傳輸中服務器數(shù)據(jù)處理延遲問題,為騰訊 Spark 大數(shù)據(jù)平臺業(yè)務提供高帶寬、低延時的通信。該技術已在二十多臺騰訊 Spark 大數(shù)據(jù)平臺服務器完成灰度測試,運行穩(wěn)定且 Spark Shuffle(數(shù)據(jù)讀取速率)時間平均降低 15% - 18% 左右,減少了 Spark 任務完成時間(大約 8% 左右),節(jié)約了服務器資源。計劃逐步部署到數(shù)千臺 Spark 服務器。
 ?
?點擊“閱讀原文”或掃描下方海報二維碼,注冊 NVIDIA DOCA 應用代碼分享活動,為新一代 AI 驅動的數(shù)據(jù)中心、高性能計算及云計算基礎設施帶來前所未有的創(chuàng)新。
原文標題:NVIDIA 攜手騰訊開發(fā)和優(yōu)化 Spark UCX 實現(xiàn)性能躍升
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
23文章
4086瀏覽量
99173
原文標題:NVIDIA 攜手騰訊開發(fā)和優(yōu)化 Spark UCX 實現(xiàn)性能躍升
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
Microchip發(fā)布專為NVIDIA DGX Spark而設計的MEC1723嵌入式控制器定制固件

全新軟件與模型優(yōu)化為NVIDIA DGX Spark注入強大動力
NVIDIA DGX Spark桌面級AI超級計算機助力開發(fā)者構建AI模型
如何在DGX Spark上運行NVIDIA Omniverse

NVIDIA DGX Spark系統(tǒng)恢復過程與步驟

NVIDIA DGX Spark助力構建自己的AI模型

在NVIDIA DGX Spark平臺上對NVIDIA ConnectX-7 200G網卡配置教程
NVIDIA DGX Spark快速入門指南

NVIDIA黃仁勛向SpaceX馬斯克交付DGX Spark
NVIDIA DGX Spark新一代AI超級計算機正式交付
MediaTek攜手NVIDIA開啟個人AI算力新紀元
NVIDIA DGX Spark桌面AI計算機開啟預訂

NVIDIA加速的Apache Spark助力企業(yè)節(jié)省大量成本

NVIDIA GTC2025 亮點 NVIDIA推出 DGX Spark個人AI計算機

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機




 工商網監(jiān)
工商網監(jiān)
評論