") 機器學(xué)習(xí)theta是什么?機器學(xué)習(xí)tpe是什么?
機器學(xué)習(xí)theta是什么?機器學(xué)習(xí)tpe是什么?

機器學(xué)習(xí)theta是什么?機器學(xué)習(xí)tpe是什么?
機器學(xué)習(xí)是近年來蓬勃發(fā)展的一個領(lǐng)域,其相關(guān)技術(shù)和理論受到了廣泛的關(guān)注和應(yīng)用。在機器學(xué)習(xí)中,theta和tpe是兩個非常重要的概念。
首先,我們來了解一下theta。在機器學(xué)習(xí)中,theta通常表示模型的參數(shù)。在回歸問題中,theta可能表示線性回歸的斜率和截距;在分類問題中,theta可能表示多項式模型的各項系數(shù)。這些參數(shù)通常是通過訓(xùn)練數(shù)據(jù)自動學(xué)習(xí)得到的,而不是手工設(shè)置的。
在機器學(xué)習(xí)中,優(yōu)化theta是一個非常關(guān)鍵的過程。因為模型的表現(xiàn)很大程度上依賴于theta的質(zhì)量。優(yōu)化theta的方法有很多種,包括梯度下降(Gradient Descent)、共軛梯度法(Conjugate Gradient)、牛頓法等等。不同的方法適用于不同的模型和問題。其中,梯度下降是最常用的優(yōu)化方法之一。
接下來,我們來了解一下tpe。TPE(Tree-structured Parzen Estimator)是一種針對貝葉斯優(yōu)化的算法。在優(yōu)化過程中,TPE將目標(biāo)函數(shù)分解為兩個部分:先驗分布和后驗分布。先驗分布看做是對模型復(fù)雜度的限制(由于模型復(fù)雜度過高會導(dǎo)致過擬合,因此需要進(jìn)行限制),后驗分布則是數(shù)據(jù)不確定性的反映,并且利用貝葉斯定理不斷更新對其進(jìn)行優(yōu)化。
TPE算法的主要優(yōu)點在于,它可以在一個高維參數(shù)空間中快速找到全局最優(yōu)解,并且相對于常見的優(yōu)化算法,TPE算法更容易適應(yīng)復(fù)雜的函數(shù)形式。因此,在很多機器學(xué)習(xí)應(yīng)用中,TPE算法已經(jīng)得到了廣泛的應(yīng)用。
總的來說,theta和tpe是機器學(xué)習(xí)領(lǐng)域中非常重要的概念。theta通常表示模型的參數(shù),而tpe則是一種針對貝葉斯優(yōu)化的算法,可以在高維參數(shù)空間中快速找到全局最優(yōu)解。熟練掌握這些概念和相關(guān)的優(yōu)化方法,對于機器學(xué)習(xí)實踐者來說,是非常重要的。
-
貝葉斯算法
+關(guān)注
關(guān)注
1文章
7瀏覽量
9196 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136928
發(fā)布評論請先 登錄
人工智能與機器學(xué)習(xí)在這些行業(yè)的深度應(yīng)用
強化學(xué)習(xí)會讓自動駕駛模型學(xué)習(xí)更快嗎?

機器學(xué)習(xí)和深度學(xué)習(xí)中需避免的 7 個常見錯誤與局限性

基于ETAS嵌入式AI工具鏈將機器學(xué)習(xí)模型部署到量產(chǎn)ECU
量子機器學(xué)習(xí)入門:三種數(shù)據(jù)編碼方法對比與應(yīng)用

如何在機器視覺中部署深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)

如何解決開發(fā)機器學(xué)習(xí)程序時Keil項目只能在調(diào)試模式下運行,但無法正常執(zhí)行的問題?
貿(mào)澤電子2025邊緣AI與機器學(xué)習(xí)技術(shù)創(chuàng)新論壇回顧(上)
FPGA在機器學(xué)習(xí)中的具體應(yīng)用
機器學(xué)習(xí)賦能的智能光子學(xué)器件系統(tǒng)研究與應(yīng)用

使用MATLAB進(jìn)行無監(jiān)督學(xué)習(xí)

機器人主控芯片平臺有哪些 機器人主控芯片一文搞懂

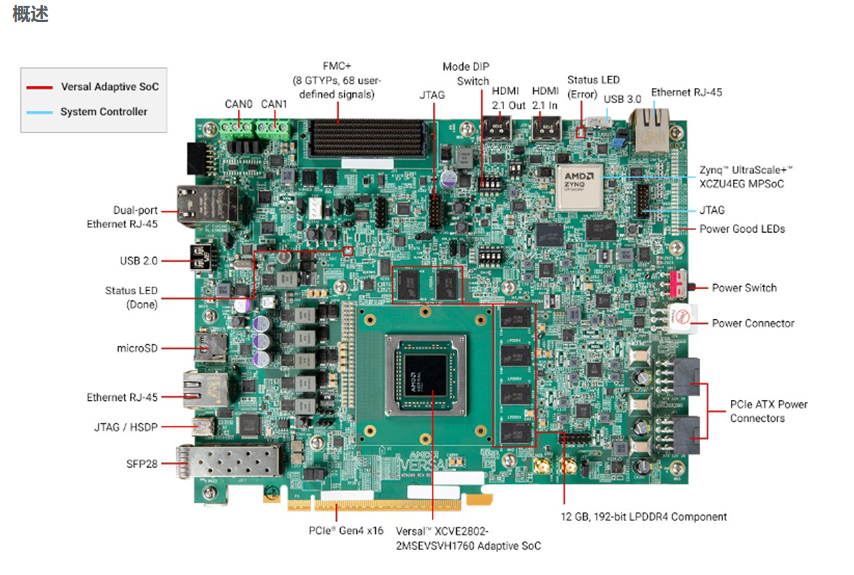
面向AI與機器學(xué)習(xí)應(yīng)用的開發(fā)平臺 AMD/Xilinx Versal? AI Edge VEK280



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論