 特斯拉的自動駕駛標注員正在被DOJO超算取代
特斯拉的自動駕駛標注員正在被DOJO超算取代

電子發燒友網報道(文/周凱揚)這年頭不少車企都開始自主研發自動駕駛系統,連帶部署數據中心和超算已經不是什么新鮮事了。除了特斯拉的DOJO和GPU超算以外,小鵬也在本月宣布與阿里云合作搭建了全國最大的自動駕駛智算中心“扶搖”,算力可達600PFLOPS,看來新一輪的軍備競賽很快就會拉開帷幕。
對于自動駕駛的開發來說,模型訓練至關重要,尋常的服務器CPU基本無法滿足這個負載需求,所以不少車企都在借助英偉達的GPU開展訓練,特斯拉也不例外。正巧今年的Hot Chips大會上安排了三場特斯拉的分享,都與特斯拉的AI與DOJO平臺有關,特斯拉的幾位自動駕駛與AI部門負責人也都透露了他們在軟硬件上的一些進展,就當是作為下個月底特斯拉AI日的前瞻了。
DOJO超算
特斯拉的DOJO是他們自研自用的機器學習超級計算機,采用了高度可擴展而且完全分布式的系統,對神經網絡訓練負載進行了專門的優化,支持靈活適應新的算法和應用。根據特斯拉Autopilot硬件工程師Emil Talpes的說法,DOJO從設計之初就是為了大型系統設計的,而不是基于目前已有的商用小系統,再把規模做大。
DOJO的基礎組成部分,就是它的D1裸片。D1基于臺積電7nm工藝,單個裸片面積占645mm2。大家都知道蘋果M1 Ultra的die size相當大,可哪怕是M1 Ultra的單個裸片大小也只有432mm2。D1采用了極度模塊化的設計,每個D1上共有354個DOJO處理單元,而且以2D陣列的形式物理和邏輯排布,單個D1在2GHz下的算力可達362TFLOPS。

DOJO訓練模塊 / 特斯拉
由5x5排布的25個合格D1芯片(KGD)組成了一個DOJO訓練模塊,整個模塊從電、熱、機械結構上都是完全集成在一起的,模塊水平層面負責不同模塊之間的通信,而垂直層面則解決15kW的供電和散熱問題。
整個DOJO系統就是由DOJO訓練模塊按2D網格結構排列而成,網格邊緣配置了DOJO接口處理器(DIP)來提供共享內存支持。而本屆Hot Chips上,特斯拉終于放出了這一處理器的詳細情報。

DOJO接口處理器 / 特斯拉
表面看上去,DIP像是一張PCIe卡,而它實際上使用的也確實是32GB/s的PCIe 4.0接口,配有32GB的HBM內核,提供800GB/s的總內存帶寬。但這PCIe 4.0的接口只是用于連接主機,真正發揮其性能的是特斯拉自研的TTP協議接口,提供900GB/s的超大帶寬給訓練模塊。
訓練模塊的邊緣配置了5個DIP卡,如此一來每邊都提供了160GB的共享DRAM,并通過這5張卡實現4.5TB/s的最大帶寬。要想擴展網絡通信的話,比如SmartNIC或交換機,DIP也原生硬件支持標準以太網上的TTP通信,當然了選擇這種通信方式的話帶寬也會降低至50GB/s,延遲也會增加。
整個系統即一個ExaPOD,由10個機柜,超過100萬片D1 CPU組成,算力可達1.1EFLOPS。而這樣的算力為特斯拉帶來了前所未有的訓練性能,尤其是在自動標注上。
被機器取代的人工標注員
雖然是特斯拉本身的商用車走的純視覺方案,但特斯拉路測車隊并不局限于提供視頻片段,畢竟去年就有人發現特斯拉的路測車輛頂著激光雷達在收集數據。在特斯拉路測車隊提交的片段中,除了視頻數據以外,還有IMU、GPS和測距儀等傳感器給出的數據。
這些數據經過離線神經網絡后,根據汽車行駛軌跡進行靜態世界重構,同時根據移動物體和動力學對物體進行自動標注。特斯拉可以自行選擇需要進行標注的片段,比如查詢可視條件不佳下的最近車輛,系統會自動返回這些片段然后進行自動標注。再加上特斯拉的4D標注,也就是在標注一次后,同時標注所有相機中的多幀畫面,極大地加快了標注速度。根據特斯拉的說法,他們可以在一周之內收集并自動標注1萬個片段。
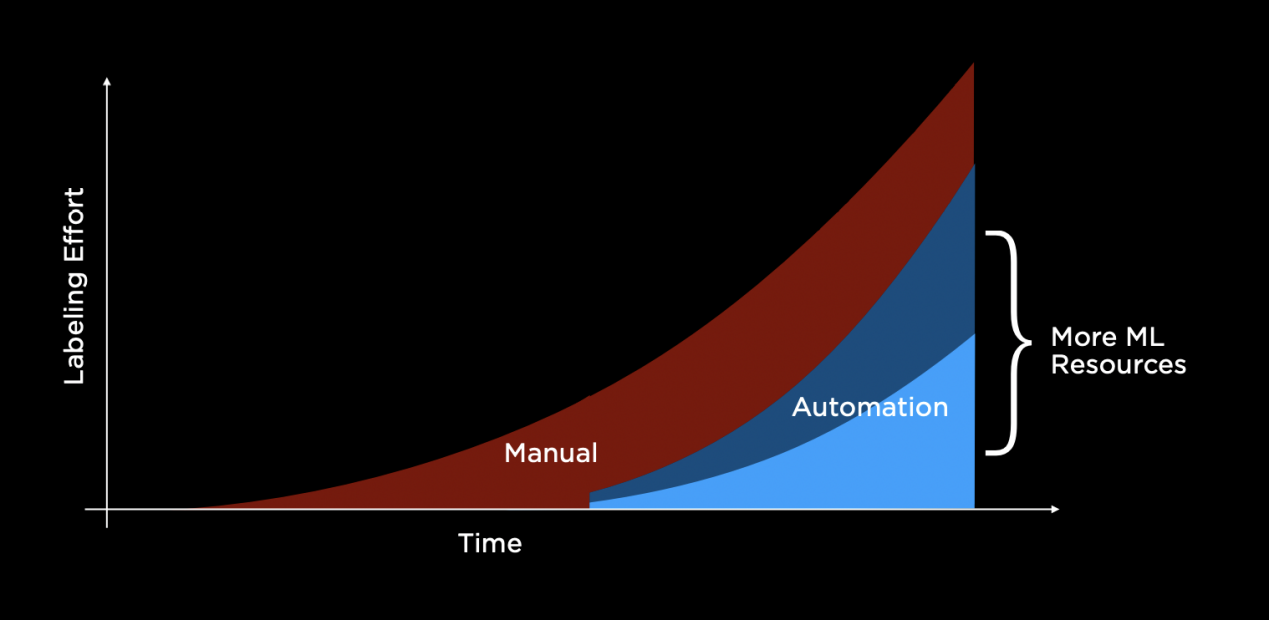
人工標注與自動標注的占比變化 / 特斯拉
這也就是特斯拉引入DOJO超算的原因,雖然標注的工作量在不斷提升,但隨著機器學習硬件資源的增多,手動標注的占比越來越低,而自動標注開始占據主導,這或許才是為何特斯拉標注團隊開始裁員的真相。
仍在繼續擴大規模的GPU超算
DOJO作為一個純CPU的超算系統,能做到以上已經相當厲害了,然而我們也不能忘記了特斯拉的另外兩臺GPU超算。早在2021年,特斯拉最新的一臺GPU超算規模就已經達到了720個節點,每個節點包含8塊英偉達A100 80GB GPU,整個系統的總GPU數達到了驚人的5760塊。
根據英偉達給出的數據,每個A100的算力有312TFLOPS,這也就意味著這臺最新GPU超算的算力已經超越了E級,達到了可怕的1.8EFLOPS。不過這里的E級和我們平常說的E級超算還是有區別的,TOP500的那些超算跑分用的是LINPACK HPL,用到的是64位雙精度的格式,得出的實際應用性能。而英偉達的A100的312TFLOPS是基于16位半精度來算的,而且是峰值性能。

特斯拉GPU超算 / 特斯拉
可即便如此,這臺超算的實力也能在TOP500上名列前茅,根據特斯拉前AI主管Andrej Karpathy的說法,單論算力(峰值)的話,特斯拉這臺GPU超算確實能在去年六月的超算榜上名列第五。
而近期,特斯拉負責AI基礎設施和AI平臺團隊的工程經理Tim Zaman宣布,特斯拉已經將這臺超算的規模再度升級,A100 80GB GPU的數量再度提升28%,達到了可怕的7360個。這價格十萬左右的GPU一下就添置近2000個,不得不承認特斯拉確實愿意下血本。Tim Zaman表示哪怕單論GPU數量,這臺超算也能排名世界第七了。
至于峰值算力,這臺超算目前大概還是在第五的位置,這是因為今年的前五席多出了兩位新晉選手,第一名的Frontier和第三名的LUMI都比這臺超算要強。而且特斯拉也并沒有提交LINPACK HPL的跑分結果,畢竟這套系統已經投入使用,特斯拉作為商業公司,也沒必要去停止手頭的訓練負載而追求跑分。DOJO的話,特斯拉并沒有公開升級其規模,上文中的1.1EFLOPS的峰值算力也是基于BF16的,所以也不適合拿來直接對比。
寫在最后
電動車時代的來臨給不少造車新勢力降低了門檻,然而自動駕駛技術的存在又將整個門檻拉高了一大截。從目前頭部企業的動向來看,搭建智算中心,拿高密度的計算資源去跑訓練或許是唯一的自研路線,這樣法規完善后,才能讓自動駕駛汽車在全國范圍內鋪開,自動駕駛也不會局限于試點技術。
但是否摸清楚了技術路線,是否愿意砸這個錢,以及回報率高低才是他們邁出這一步關鍵,畢竟要讓一個車企去組建團隊搞芯片設計,這個要求還是有些過分了,但僅僅是與云服務廠商合作打造這樣一個智算中心,同樣也得付出不小的成本。
對于自動駕駛的開發來說,模型訓練至關重要,尋常的服務器CPU基本無法滿足這個負載需求,所以不少車企都在借助英偉達的GPU開展訓練,特斯拉也不例外。正巧今年的Hot Chips大會上安排了三場特斯拉的分享,都與特斯拉的AI與DOJO平臺有關,特斯拉的幾位自動駕駛與AI部門負責人也都透露了他們在軟硬件上的一些進展,就當是作為下個月底特斯拉AI日的前瞻了。
DOJO超算
特斯拉的DOJO是他們自研自用的機器學習超級計算機,采用了高度可擴展而且完全分布式的系統,對神經網絡訓練負載進行了專門的優化,支持靈活適應新的算法和應用。根據特斯拉Autopilot硬件工程師Emil Talpes的說法,DOJO從設計之初就是為了大型系統設計的,而不是基于目前已有的商用小系統,再把規模做大。
DOJO的基礎組成部分,就是它的D1裸片。D1基于臺積電7nm工藝,單個裸片面積占645mm2。大家都知道蘋果M1 Ultra的die size相當大,可哪怕是M1 Ultra的單個裸片大小也只有432mm2。D1采用了極度模塊化的設計,每個D1上共有354個DOJO處理單元,而且以2D陣列的形式物理和邏輯排布,單個D1在2GHz下的算力可達362TFLOPS。
DOJO訓練模塊 / 特斯拉
由5x5排布的25個合格D1芯片(KGD)組成了一個DOJO訓練模塊,整個模塊從電、熱、機械結構上都是完全集成在一起的,模塊水平層面負責不同模塊之間的通信,而垂直層面則解決15kW的供電和散熱問題。
整個DOJO系統就是由DOJO訓練模塊按2D網格結構排列而成,網格邊緣配置了DOJO接口處理器(DIP)來提供共享內存支持。而本屆Hot Chips上,特斯拉終于放出了這一處理器的詳細情報。
DOJO接口處理器 / 特斯拉
表面看上去,DIP像是一張PCIe卡,而它實際上使用的也確實是32GB/s的PCIe 4.0接口,配有32GB的HBM內核,提供800GB/s的總內存帶寬。但這PCIe 4.0的接口只是用于連接主機,真正發揮其性能的是特斯拉自研的TTP協議接口,提供900GB/s的超大帶寬給訓練模塊。
訓練模塊的邊緣配置了5個DIP卡,如此一來每邊都提供了160GB的共享DRAM,并通過這5張卡實現4.5TB/s的最大帶寬。要想擴展網絡通信的話,比如SmartNIC或交換機,DIP也原生硬件支持標準以太網上的TTP通信,當然了選擇這種通信方式的話帶寬也會降低至50GB/s,延遲也會增加。
整個系統即一個ExaPOD,由10個機柜,超過100萬片D1 CPU組成,算力可達1.1EFLOPS。而這樣的算力為特斯拉帶來了前所未有的訓練性能,尤其是在自動標注上。
被機器取代的人工標注員
雖然是特斯拉本身的商用車走的純視覺方案,但特斯拉路測車隊并不局限于提供視頻片段,畢竟去年就有人發現特斯拉的路測車輛頂著激光雷達在收集數據。在特斯拉路測車隊提交的片段中,除了視頻數據以外,還有IMU、GPS和測距儀等傳感器給出的數據。
這些數據經過離線神經網絡后,根據汽車行駛軌跡進行靜態世界重構,同時根據移動物體和動力學對物體進行自動標注。特斯拉可以自行選擇需要進行標注的片段,比如查詢可視條件不佳下的最近車輛,系統會自動返回這些片段然后進行自動標注。再加上特斯拉的4D標注,也就是在標注一次后,同時標注所有相機中的多幀畫面,極大地加快了標注速度。根據特斯拉的說法,他們可以在一周之內收集并自動標注1萬個片段。
人工標注與自動標注的占比變化 / 特斯拉
仍在繼續擴大規模的GPU超算
DOJO作為一個純CPU的超算系統,能做到以上已經相當厲害了,然而我們也不能忘記了特斯拉的另外兩臺GPU超算。早在2021年,特斯拉最新的一臺GPU超算規模就已經達到了720個節點,每個節點包含8塊英偉達A100 80GB GPU,整個系統的總GPU數達到了驚人的5760塊。
根據英偉達給出的數據,每個A100的算力有312TFLOPS,這也就意味著這臺最新GPU超算的算力已經超越了E級,達到了可怕的1.8EFLOPS。不過這里的E級和我們平常說的E級超算還是有區別的,TOP500的那些超算跑分用的是LINPACK HPL,用到的是64位雙精度的格式,得出的實際應用性能。而英偉達的A100的312TFLOPS是基于16位半精度來算的,而且是峰值性能。
特斯拉GPU超算 / 特斯拉
可即便如此,這臺超算的實力也能在TOP500上名列前茅,根據特斯拉前AI主管Andrej Karpathy的說法,單論算力(峰值)的話,特斯拉這臺GPU超算確實能在去年六月的超算榜上名列第五。
而近期,特斯拉負責AI基礎設施和AI平臺團隊的工程經理Tim Zaman宣布,特斯拉已經將這臺超算的規模再度升級,A100 80GB GPU的數量再度提升28%,達到了可怕的7360個。這價格十萬左右的GPU一下就添置近2000個,不得不承認特斯拉確實愿意下血本。Tim Zaman表示哪怕單論GPU數量,這臺超算也能排名世界第七了。
至于峰值算力,這臺超算目前大概還是在第五的位置,這是因為今年的前五席多出了兩位新晉選手,第一名的Frontier和第三名的LUMI都比這臺超算要強。而且特斯拉也并沒有提交LINPACK HPL的跑分結果,畢竟這套系統已經投入使用,特斯拉作為商業公司,也沒必要去停止手頭的訓練負載而追求跑分。DOJO的話,特斯拉并沒有公開升級其規模,上文中的1.1EFLOPS的峰值算力也是基于BF16的,所以也不適合拿來直接對比。
寫在最后
電動車時代的來臨給不少造車新勢力降低了門檻,然而自動駕駛技術的存在又將整個門檻拉高了一大截。從目前頭部企業的動向來看,搭建智算中心,拿高密度的計算資源去跑訓練或許是唯一的自研路線,這樣法規完善后,才能讓自動駕駛汽車在全國范圍內鋪開,自動駕駛也不會局限于試點技術。
但是否摸清楚了技術路線,是否愿意砸這個錢,以及回報率高低才是他們邁出這一步關鍵,畢竟要讓一個車企去組建團隊搞芯片設計,這個要求還是有些過分了,但僅僅是與云服務廠商合作打造這樣一個智算中心,同樣也得付出不小的成本。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
特斯拉
+關注
關注
66文章
6413瀏覽量
131367 -
自動駕駛
+關注
關注
793文章
14883瀏覽量
179889
發布評論請先 登錄
相關推薦
熱點推薦
大模型時代自動駕駛標注有什么特殊要求?
在自動駕駛的發展歷程中,數據標注一直被視為算法進化的基石。然而,隨著大模型時代的到來,這一領域正經歷著重構。 過去,標注員的任務是簡單地在二維照片上畫框,標記出車輛和行人的位置。但現在


算力越高,自動駕駛汽車就會越聰明?
在自動駕駛行業,說起算力,很多人第一反應是“更強就是更好”,更快的芯片、更大的算力池,感覺就可以讓汽車能看得更清楚、做決定更快、更安全。但事實并非如此。對于自動駕駛汽車來說,算力確實重
自動駕駛數據標注是所有信息都要標注嗎?
[首發于智駕最前沿微信公眾號]數據標注對于自動駕駛來說,就像是老師教小朋友知識,數據標注可以讓車輛學習辨別道路交通信息的能力。攝像頭、雷達、激光雷達(LiDAR)拍下來的只是一堆原始信號,這些信號

不同等級的自動駕駛技術要求上有何不同?
談到自動駕駛,不可避免地會涉及到自動駕駛分級,美國汽車工程師學會(SAE)根據自動駕駛系統與人類駕駛員參與駕駛行為程度的不同,將
一文讀懂特斯拉自動駕駛FSD從輔助到端到端的演進
[首發于智駕最前沿微信公眾號]自動駕駛行業發展至今,特斯拉一直被很多企業對標,其FSD系統的每一次更新,都會獲得非常多人的關注。早期自動駕駛是一個分層的、由多模塊組成的系統,感知、定位、預測、規劃
自動駕駛中Transformer大模型會取代深度學習嗎?
持續討論。特別是在自動駕駛領域,部分廠商開始嘗試將多模態大模型(MLLM)引入到感知、規劃與決策系統,引發了“傳統深度學習是否已過時”的激烈爭論。然而,從技術原理、算力成本、安全需求與實際落地路徑等維度來看,Transformer與深度學習并非你死我活的替代

特斯拉Dojo重塑供應鏈,三星和英特爾分別贏得芯片和封裝合同
電子發燒友綜合報道,外媒消息稱,特斯拉 (Tesla) 在發展其自動駕駛 AI 訓練的超級計算機“Dojo”的過程中,正對其供應鏈進行一次全面而重大的調整。 過去 Dojo 芯片的生產
自動駕駛數據標注主要是標注什么?
[首發于智駕最前沿微信公眾號]在自動駕駛系統的研發過程中,數據標注是實現高性能感知模型的基礎環節,其核心目標是將車輛從環境中采集到的原始感知數據(主要包括圖像、點云、視頻序列等)轉化為具有語義信息
什么是自動駕駛數據標注?如何好做數據標注?
[首發于智駕最前沿微信公眾號]在自動駕駛系統的開發過程中,數據標注是一項至關重要的工作。它不僅決定了模型訓練的質量,也直接影響了車輛感知、決策與控制的性能表現。隨著傳感器種類和數據量的劇增,有效
自動駕駛汽車接管邏輯如何設置更為合理?
交通環境并隨時接管的工作。但就是這一簡單需求,車企在自動駕駛系統與人類駕駛員的接管邊界并未給出明確的界定。有很多實際案例表明,在系統無法處理復雜路況時,會突然彈出“請立即接管”的提示,而駕駛員此時可能
端到端數據標注方案在自動駕駛領域的應用優勢
10-20TB,其中需要標注的數據占比超過60%。在這樣的背景下,端到端數據標注方案應運而生,正在重塑自動駕駛的數據生產范式。 端到端數據標注
淺析4D-bev標注技術在自動駕駛領域的重要性
?自動駕駛技術的發展日新月異。從最初簡單的輔助駕駛功能,逐步邁向高度自動化甚至完全自動駕駛的階段。其中,海量且精準的數據是訓練高性能自動駕駛
自動駕駛技術落地前為什么要先測試?
大量的傳感器、復雜的算法和強大的計算平臺來取代人類駕駛員的感知、判斷和操作。在技術落地之前,“測試”便成了自動駕駛從實驗室走向真實道路的“安全閥”和“試金石”。如果沒有充分的測試,無論技術多么先進,都可能在現實環境中
NVIDIA Halos自動駕駛汽車安全系統發布
NVIDIA 整合了從云端到車端的安全自動駕駛開發技術套件,涵蓋車輛架構到 AI 模型,包括芯片、軟件、工具和服務。 物理 AI 正在為自動駕駛和機器人開發技術的交叉領域釋放新的可能性,尤其是加速了



 工商網監
工商網監
評論