") 自動駕駛數(shù)據(jù)標注主要是標注什么?
自動駕駛數(shù)據(jù)標注主要是標注什么?

[首發(fā)于智駕最前沿微信公眾號]在自動駕駛系統(tǒng)的研發(fā)過程中,數(shù)據(jù)標注是實現(xiàn)高性能感知模型的基礎(chǔ)環(huán)節(jié),其核心目標是將車輛從環(huán)境中采集到的原始感知數(shù)據(jù)(主要包括圖像、點云、視頻序列等)轉(zhuǎn)化為具有語義信息的結(jié)構(gòu)化標簽。這些標簽不僅構(gòu)成了模型訓練與評估的數(shù)據(jù)基礎(chǔ),也直接影響系統(tǒng)在實際道路環(huán)境中的識別、理解和決策能力。準確、系統(tǒng)的數(shù)據(jù)標注能夠有效提升感知算法的魯棒性與泛化能力,因此數(shù)據(jù)標注在整個自動駕駛技術(shù)體系中具有不可替代的重要性。之前就和大家聊過自動駕駛數(shù)據(jù)標注的含義及流程,今天就和大家聊聊自動駕駛數(shù)據(jù)標注主要標注些啥!
以圖像數(shù)據(jù)為例,自動駕駛車輛搭載的前視、側(cè)視及后視攝像頭在不同時序中連續(xù)采集道路場景,標注工作首先聚焦于場景中關(guān)鍵目標的識別與定位,其中包括行駛車輛、非機動車、行人、交通標志、紅綠燈、車道線、人行橫道、減速帶等目標對象。標注形式主要采用二維邊界框(2D bounding box)、實例分割(instance segmentation)或語義分割(semantic segmentation)等方式,語義分割通過對圖像中每個像素賦予明確的類別標簽,實現(xiàn)高精度目標識別;實例分割則進一步區(qū)分同類物體之間的個體邊界,便于系統(tǒng)對目標狀態(tài)和行為進行獨立建模。如多個并行行駛的車輛不僅要被識別為“車輛”類,還需要區(qū)分成“車輛A”、“車輛B”等,以供后續(xù)的軌跡預測與風險評估模塊調(diào)用。
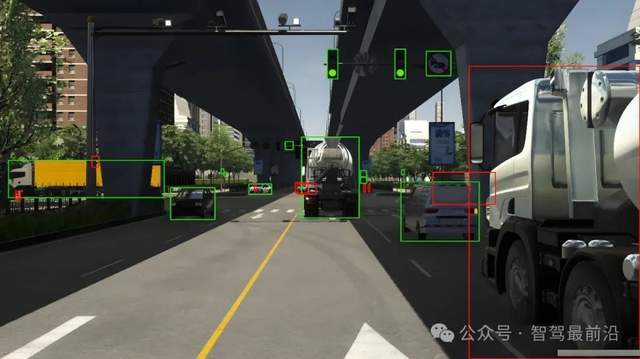
在三維空間建模中,激光雷達點云數(shù)據(jù)的標注則具有更高的空間復雜性。由于點云反映的是物體的空間分布結(jié)構(gòu),標注過程一般采用三維包圍框(3D bounding box)的方式,記錄目標物體在X、Y、Z坐標軸上的尺寸、中心點、朝向角和類別屬性。一輛前方車輛的點云標簽不僅包括其空間范圍,還要精確到是否靜止、緩行或變道等動態(tài)狀態(tài)。在序列點云數(shù)據(jù)中,還需為每個目標在連續(xù)幀中賦予一致的標識符(object ID),構(gòu)建目標在時間維度上的軌跡。這種“時間一致性標注”有助于算法學習目標的運動規(guī)律,為高精度預測模型提供時序特征輸入。

除了單模態(tài)標注,自動駕駛系統(tǒng)中的多傳感器融合也要求跨模態(tài)的數(shù)據(jù)標注。在圖像與激光雷達融合的場景下,同一目標需要在不同模態(tài)下標注對應關(guān)系,這一過程依賴高精度的傳感器外參標定。這就需要先在圖像中完成二維目標標注,然后通過坐標轉(zhuǎn)換映射至點云中定位目標在三維空間中的位置,再繪制三維包圍框,實現(xiàn)圖像與點云的同步語義對齊。這種融合標注不僅提高了模型在復雜場景下的識別準確性,也為后續(xù)的目標關(guān)聯(lián)、多模態(tài)特征提取與時空建模提供了基礎(chǔ)數(shù)據(jù)支撐。
在高精地圖數(shù)據(jù)的構(gòu)建過程中,標注則承擔了對道路空間幾何結(jié)構(gòu)和語義要素的抽象與提取任務。標注內(nèi)容包括車道中心線、車道邊界、車道類型、交通標志位置信息、信號燈安裝結(jié)構(gòu)、道路坡度、曲率變化、限速信息等靜態(tài)元素。這些信息通常以圖層形式疊加在全球?qū)Ш絽⒖甲鴺讼担ㄈ鏦GS-84)中,并與實時定位系統(tǒng)相匹配,使自動駕駛車輛能夠在厘米級精度范圍內(nèi)感知自身相對位置,從而完成路徑規(guī)劃、變道判斷及信號燈決策等關(guān)鍵操作。地圖數(shù)據(jù)的標注不僅要求高空間精度,還必須與感知標注保持語義一致性,確保感知-地圖聯(lián)動模型的穩(wěn)定性。
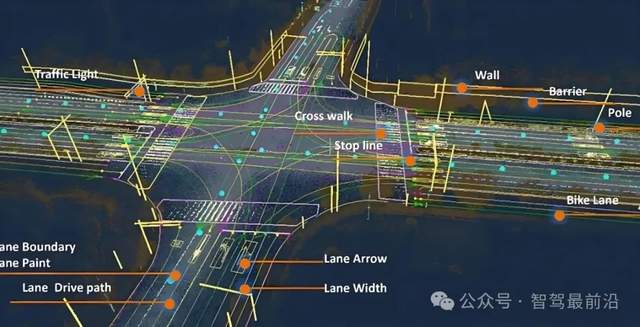
除了對于交通信息的標注外,標注還包括對整體環(huán)境狀態(tài)的描述,如當前道路類型(城市道路、快速路、高速公路)、天氣條件(晴、雨、霧、雪)、光照環(huán)境(白天、黃昏、夜間)及交通密度(稀疏、適中、擁堵)等。這些非結(jié)構(gòu)化信息通常作為附加標簽與主干感知數(shù)據(jù)一并存儲,在模型訓練過程中作為輔助輸入,有助于提升模型在多樣化場景下的適應能力,減少對極端天氣或少見道路狀態(tài)的誤判風險。
行為層面的標注則更加聚焦于動態(tài)交通參與者的運動特征與意圖識別。在連續(xù)圖像或點云序列中,標注時需記錄車輛、行人、自行車等目標的運動軌跡,并附加如加速、減速、轉(zhuǎn)向、停止、橫穿、等待等動態(tài)屬性信息。這類標簽不僅可以用于訓練軌跡預測模型,也可用于建構(gòu)高階行為識別模型,使系統(tǒng)能夠判斷目標是否存在潛在風險或突發(fā)變動,從而及時調(diào)整駕駛策略。為了提升行為識別的細粒度表達,在某些項目中,還會對人類目標進行關(guān)鍵點標注(如頭部、軀干、四肢關(guān)節(jié))或動作標簽(如揮手、回頭、奔跑),為復雜交互環(huán)境下的意圖推理提供先驗數(shù)據(jù)。
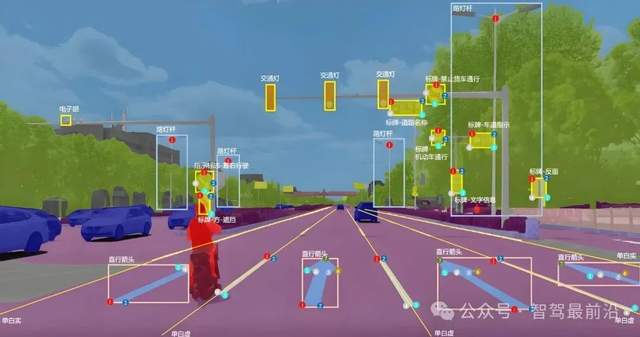
數(shù)據(jù)標注的質(zhì)量直接影響模型訓練的效果與實際部署的安全性。因此,在整個標注流程中,質(zhì)量控制是重中之重。項目團隊會制定標準化的標注規(guī)范文檔,明確目標分類標準、邊界劃定原則、遮擋處理策略、置信度打分機制等技術(shù)細則。標注人員需經(jīng)過專業(yè)培訓,通過考核后方可參與正式標注任務。標注完成后,還需經(jīng)過至少兩輪人工復審和一輪自動化腳本檢測,確保數(shù)據(jù)在語義、空間、時間維度上的一致性。自動化檢測可識別邊框尺寸異常、類別不一致、ID漂移等問題,并輸出修正建議供人工確認,從而保障數(shù)據(jù)集在大規(guī)模使用時具備穩(wěn)定性和可重復性。
主機廠和技術(shù)公司通常基于自研標注平臺,結(jié)合自采數(shù)據(jù)、場景采樣機制和反饋式訓練策略,形成持續(xù)迭代的數(shù)據(jù)閉環(huán)。特斯拉就通過“影子模式”在真實用戶駕駛中采集系統(tǒng)誤判樣本,回流至數(shù)據(jù)標注團隊進行再標注,形成模型優(yōu)化的真實用例補集;Waymo則發(fā)布開放數(shù)據(jù)集,規(guī)范標注格式并設(shè)立數(shù)據(jù)挑戰(zhàn)賽,推動行業(yè)間標注標準與評價體系趨同。百度Apollo、AutoX、Momenta等國內(nèi)企業(yè)則通過在不同城市、不同交通規(guī)則下采集數(shù)據(jù)、定向標注、訓練本地化模型,以提升在本地場景中的部署適應性。
綜上所述,自動駕駛數(shù)據(jù)標注的核心任務是為算法提供準確、全面、時序一致且場景豐富的訓練樣本,涵蓋從二維圖像中的語義信息,到三維點云中的空間建模,再到多模態(tài)數(shù)據(jù)的融合對齊、高精地圖的結(jié)構(gòu)化表達以及動態(tài)行為的時序軌跡。在整個自動駕駛感知鏈條中,標注數(shù)據(jù)的標準化、系統(tǒng)性與質(zhì)量保障是實現(xiàn)“機器理解世界”的根本前提,也是感知、預測、決策、控制四大模塊協(xié)同運作的基礎(chǔ)支撐。隨著自動駕駛系統(tǒng)逐步走向量產(chǎn)應用,數(shù)據(jù)標注工作的科學性與工程能力將持續(xù)成為決定算法性能和系統(tǒng)安全性的關(guān)鍵因素之一。
審核編輯 黃宇
-
自動駕駛
+關(guān)注
關(guān)注
794文章
14938瀏覽量
180782
發(fā)布評論請先 登錄
大模型時代自動駕駛標注有什么特殊要求?

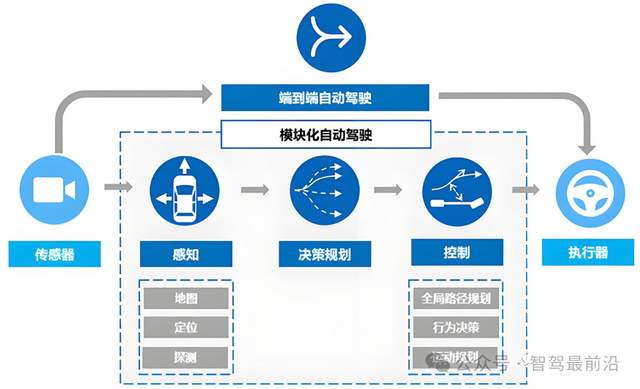
端到端與模塊化自動駕駛的數(shù)據(jù)標注要求有何不同?
全自動化驅(qū)動 ADAS 高精度標注:aiData Auto Annotator 深度解析

自動駕駛數(shù)據(jù)標注是所有信息都要標注嗎?

算法工程師不愿做標注工作,怎么辦?

自動駕駛中常提的“專家數(shù)據(jù)”是個啥?
淺析多模態(tài)標注對大模型應用落地的重要性與標注實例
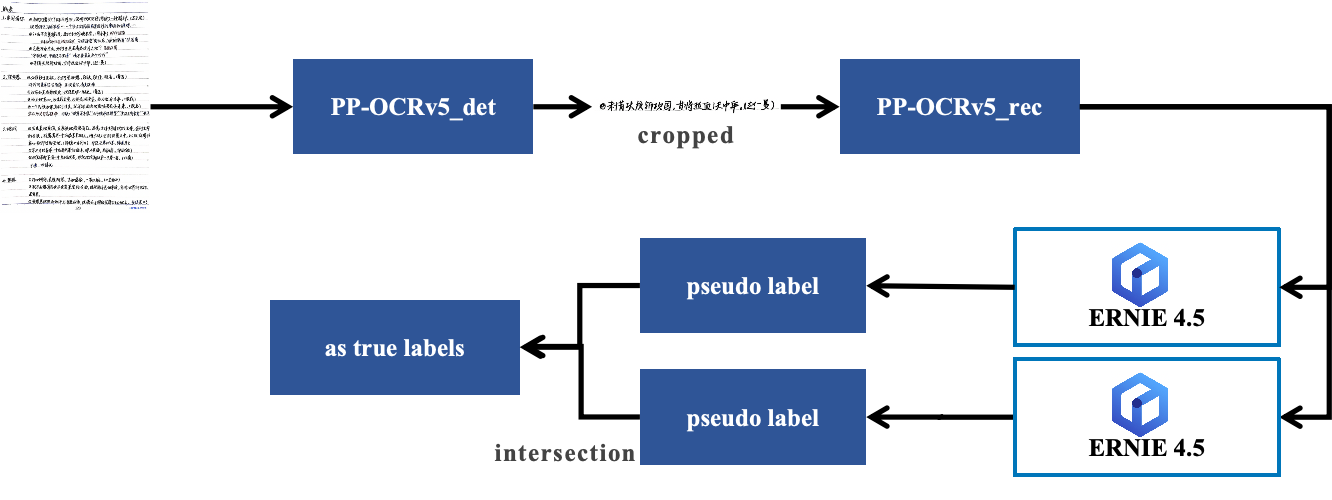
小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰(zhàn)解析
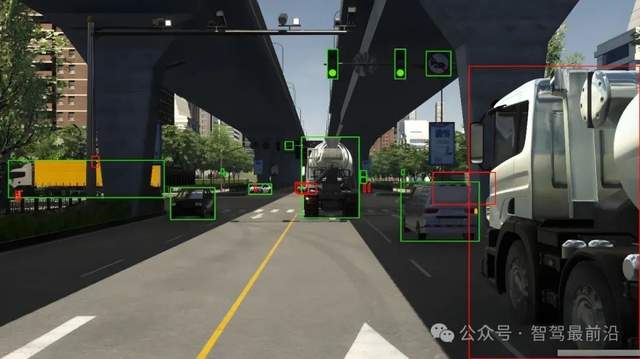
什么是自動駕駛數(shù)據(jù)標注?如何好做數(shù)據(jù)標注?
端到端數(shù)據(jù)標注方案在自動駕駛領(lǐng)域的應用優(yōu)勢
淺析4D-bev標注技術(shù)在自動駕駛領(lǐng)域的重要性
數(shù)據(jù)標注與大模型的雙向賦能:效率與性能的躍升
AI時代 圖像標注不要沒苦硬吃
東軟集團入選國家數(shù)據(jù)局數(shù)據(jù)標注優(yōu)秀案例
標貝科技“4D-BEV上億點云標注系統(tǒng)”入選國家數(shù)據(jù)局首批數(shù)據(jù)標注優(yōu)秀案例




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論