 小白學大模型:大模型加速的秘密 FlashAttention 1/2/3
小白學大模型:大模型加速的秘密 FlashAttention 1/2/3

本文轉自:Coggle數據科學
在 Transformer 架構中,注意力機制的計算復雜度與序列長度(即文本長度)呈平方關系()。這意味著,當模型需要處理更長的文本時(比如從幾千個詞到幾萬個詞),計算時間和所需的內存會急劇增加。最開始的標準注意力機制存在兩個主要問題:
- 內存占用高:模型需要生成一個巨大的注意力矩陣 (N×N)。這個矩陣需要被保存在高帶寬內存 (HBM)中。對于長序列,這很快就會超出 GPU 的內存容量。
- 計算效率低:標準實現會將注意力計算分解成多個獨立的步驟(矩陣乘法、softmax 等)。每一步都需要將數據從速度較慢的 HBM 中讀取,計算后又寫回 HBM。這種頻繁的數據移動(內存讀寫)成為了性能瓶頸,導致 GPU 的計算單元(如 Tensor Cores)利用率低下。
什么是 FlashAttention?
FlashAttention 使得處理長達數萬甚至數十萬個 token 的超長文本成為可能。這解鎖了新的應用場景,例如分析法律文檔、總結長篇小說或處理整個代碼庫。
FlashAttention 使得模型的訓練和推理速度更快,尤其是在長序列場景下。例如,FlashAttention-2 在長序列上比標準實現快 10 倍,使得訓練成本更低,用戶體驗更好。
最新的 FlashAttention-3 利用了新硬件(如 NVIDIA H100)的 FP8 精度,進一步提升了性能,同時通過特殊的算法保持了計算的準確性,讓模型訓練更加高效。
FlashAttention v1
許多研究提出了近似注意力方法,試圖通過減少計算量(FLOPs)來提高效率。然而,這些方法通常忽略了GPU不同層級內存(如高速的片上SRAM和相對較慢的高帶寬HBM)之間的I/O開銷,導致它們在實際運行時并沒有帶來顯著的加速。
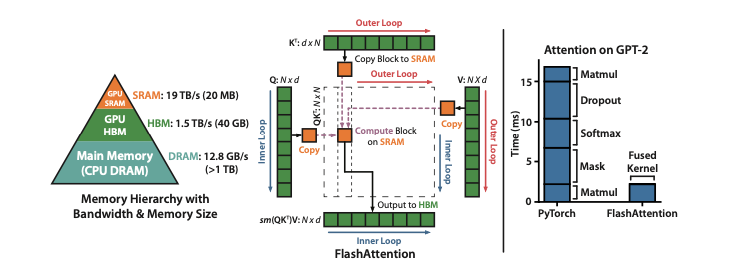
FlashAttention的核心思想是I/O感知,即在設計算法時,將數據在不同層級內存之間的讀寫開銷考慮在內。論文指出,在現代GPU上,計算速度已經遠超內存訪問速度,因此大多數操作都受限于內存訪問。FlashAttention通過以下兩個關鍵技術來解決這一問題:
- Tiling (平鋪):將輸入數據(Q、K、V矩陣)分割成小塊,并在GPU的片上SRAM中進行計算。這樣可以避免將龐大的 N×N 注意力矩陣完整地寫入到速度較慢的HBM中。
- 內存優化:在反向傳播時,FlashAttention 不存儲巨大的中間注意力矩陣,而是只保存前向傳播中計算出的Softmax歸一化因子。這樣,反向傳播時可以利用這些因子在SRAM中快速地重新計算注意力矩陣,從而避免了從HBM讀取大矩陣的開銷。
GPU內存層級
- HBM (高帶寬內存):容量大(如A100 GPU的40-80 GB),但速度相對較慢(帶寬1.5-2.0 TB/s)。
- 片上SRAM (靜態隨機存取存儲器):容量小(每個流式多處理器有192 KB),但速度極快(帶寬估計達19 TB/s),比HBM快一個數量級以上。
由于GPU的計算速度增長快于內存速度,許多操作的性能瓶頸在于內存訪問,而不是計算本身。因此,如何高效利用快速的SRAM變得至關重要。
運算類型
根據算術強度(每字節內存訪問的算術運算次數),操作可分為兩類:
- 計算密集型 (Compute-bound):運算時間由算術操作數量決定,內存訪問時間相對較小。例如,大規模矩陣乘法。
- 內存密集型 (Memory-bound):運算時間由內存訪問次數決定,計算時間相對較小。例如,大多數元素級操作(如激活函數、Dropout)和歸約操作(如Softmax、LayerNorm)。
注意力實現改進

給定查詢 Q、鍵 K 和值 V 矩陣,注意力的計算分三步:
- 相似度計算:
- Softmax歸一化:
- 加權求和:
標準實現(如“Algorithm 0”所示)將每一步都作為一個獨立的GPU核函數,并物化(materialize)中間矩陣 S 和 P 到HBM中。
這種實現方式導致了兩個主要問題:
- 巨大的內存占用:中間矩陣 S 和 P 的大小為 N×N,其內存占用與序列長度 N 的平方成正比。
- 大量的HBM訪問:由于每個步驟都需要讀寫HBM,導致I/O開銷巨大。論文指出,這種方法對HBM的訪問次數是 O(N2) 級別的,這在長序列(通常 N?d)時會成為主要的性能瓶頸,導致運行時間慢。
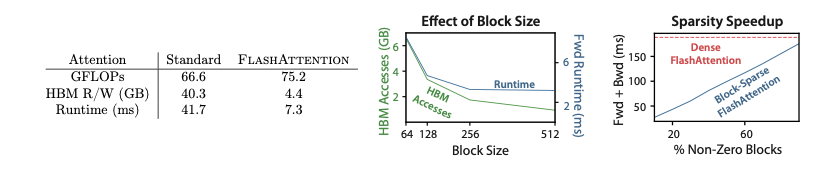
FlashAttention旨在減少對GPU高帶寬內存(HBM)的讀寫,實現對確切注意力(exact attention)的快速、內存高效的計算。為此,它采用了兩種關鍵技術:
- Tiling(分塊):將輸入的 Q,K,V 矩陣分成若干小塊。然后,在計算過程中,每次只將一小塊數據從慢速的HBM加載到快速的片上SRAM進行計算,而不是一次性加載整個大矩陣。
- Recomputation(重計算):為了避免在反向傳播時存儲 O(N2) 的中間注意力矩陣 S 和 P,FlashAttention只存儲 Softmax 的歸一化統計量(即 m 和 ?)。在反向傳播時,它會利用這些統計量,按需在SRAM中重新計算必要的注意力矩陣塊。
通過Tiling和Recomputation,FlashAttention能夠將所有計算步驟(矩陣乘法、Softmax、可選的遮蔽和Dropout)融合成一個單一的CUDA核函數。這避免了在每個步驟之間反復地將數據寫入HBM。
實現效果
lashAttention在BERT-large模型上的訓練速度超過了MLPerf 1.1的記錄保持者。與Nvidia的實現相比,FlashAttention的訓練時間縮短了15%,這證明了其在標準長序列任務上的卓越性能。

FlashAttention在訓練GPT-2模型時,相比于流行的HuggingFace和Megatron-LM實現,實現了顯著的端到端加速。
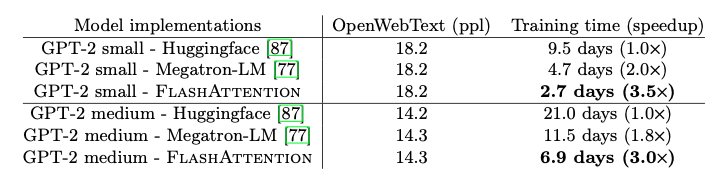
- 與Huggingface相比,速度提升高達3倍。
- 與Megatron-LM相比,速度提升高達1.7倍。
- 重要的是,FlashAttention在不改變模型定義的情況下,實現了與基線模型相同的困惑度(perplexity),證明了其數值穩定性。
在Long-Range Arena基準測試中,FlashAttention相比于標準的Transformer實現,實現了2.4倍的加速。此外,塊稀疏FlashAttention的表現甚至優于所有已測試的近似注意力方法,證明了其在處理超長序列時的優越性。
lashAttention的內存占用與序列長度呈線性關系,而標準實現是平方關系。這使得FlashAttention的內存效率比標準方法高出20倍。
FlashAttention v2
第一代FlashAttention通過利用 GPU 內存層次結構的特性,顯著降低了內存占用(從二次方降為線性)并實現了 2-4 倍的加速,且沒有引入任何近似。
然而,FlashAttention 的效率仍然不如優化的矩陣乘法(GEMM)操作,其浮點運算性能(FLOPs/s)僅能達到理論峰值的 25-40%。這主要是因為 FlashAttention 存在不優化的工作劃分(work partitioning),導致 GPU 線程塊(thread blocks)和線程束(warps)之間的并行度不足、占用率低或產生不必要的共享內存讀寫。
為了解決這些問題,論文提出了FlashAttention-2,通過以下改進實現了更好的工作劃分:
- 減少非矩陣乘法(non-matmul)的浮點運算:雖然這類操作占總 FLOPs 的比例小,但執行起來很慢。
- 在序列長度維度上并行化:即使對于單個注意力頭,也將其計算任務分配給不同的線程塊,以提高 GPU 的占用率。
- 優化線程塊內部的工作分配:在每個線程塊內,重新分配線程束之間的工作,以減少通過共享內存進行的通信。
前向傳播改進
FlashAttention-2對在線 Softmax 技巧進行了兩處微調:
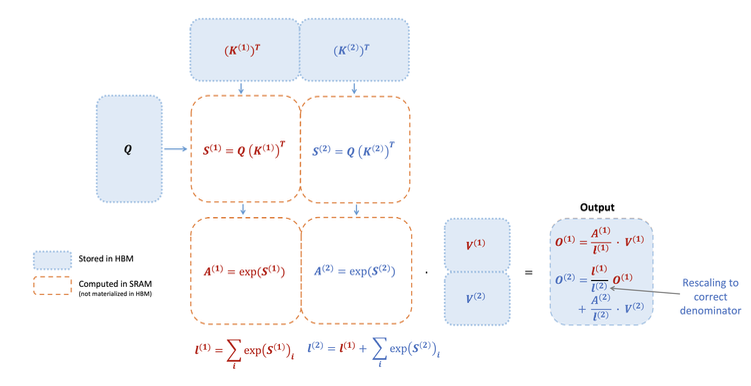
- 延遲歸一化:在每個循環迭代中,不立即對輸出進行歸一化。相反,它維護一個“未縮放”的中間結果,并在整個循環結束時僅進行一次最終的歸一化。這減少了每個塊的縮放操作,從而減少了非 matmul 的 FLOPs。
- 簡化統計量:為反向傳播存儲數據時,只保存logsumexp統計量 L(j)=m(j)+log(?(j)),而不是同時存儲最大值 m(j) 和指數和 ?(j)。
并行化改進
第一代 FlashAttention 僅在批處理大小和注意力頭數量上進行并行化。當序列長度很長時,批處理大小通常很小,導致 GPU 資源的利用率(occupancy)不高。FlashAttention-2 通過在序列長度維度上增加并行化來解決這個問題。
- 前向傳播:FlashAttention-2 將注意力矩陣的行塊任務分配給不同的線程塊,這些線程塊之間無需通信。通過在行維度上并行,當批次大小和注意力頭數較小時,GPU 的 SM(流式多處理器)能夠被更充分地利用,從而提高整體吞吐量。
- 后向傳播:類似地,后向傳播則在注意力矩陣的列塊上進行并行。由于反向傳播中的某些更新需要跨線程塊通信,作者使用了原子加法(atomic adds)來更新共享的梯度 dK 和 dV,確保了線程安全。
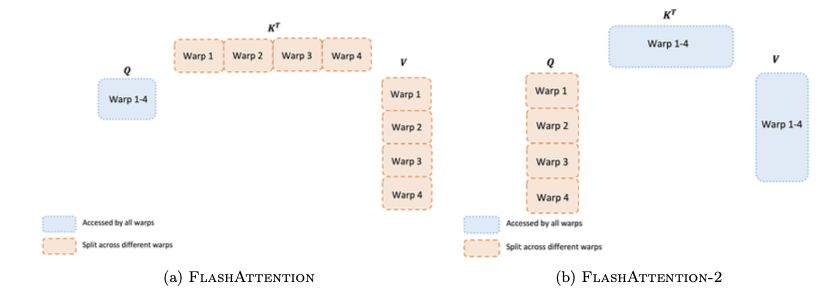
除了線程塊級別的并行,FlashAttention-2 還優化了線程塊內部線程束之間的工作分配,以減少共享內存的讀寫。
- 前向傳播:
- FlashAttention:采用“split-K”方案,將 K 和 V 矩陣的計算任務分配給不同的線程束。這要求所有線程束將中間結果寫入共享內存,再進行同步和求和,導致不必要的共享內存訪問。
- FlashAttention-2:改為將 Q 矩陣的計算任務分配給不同的線程束。每個線程束負責計算 Q 的一個分片與完整的 K 的乘積。這樣,每個線程束可以獨立地完成其部分輸出,而無需與其他線程束進行共享內存通信,從而顯著提高了效率。
- 后向傳播:后向傳播的依賴關系更復雜,但 FlashAttention-2 仍然通過避免“split-K”方案來減少共享內存的讀寫,實現了性能提升。
實現效果
FlashAttention-2 比第一代 FlashAttention 快1.7-3.0 倍,比 Triton 實現的 FlashAttention 快1.3-2.5 倍。
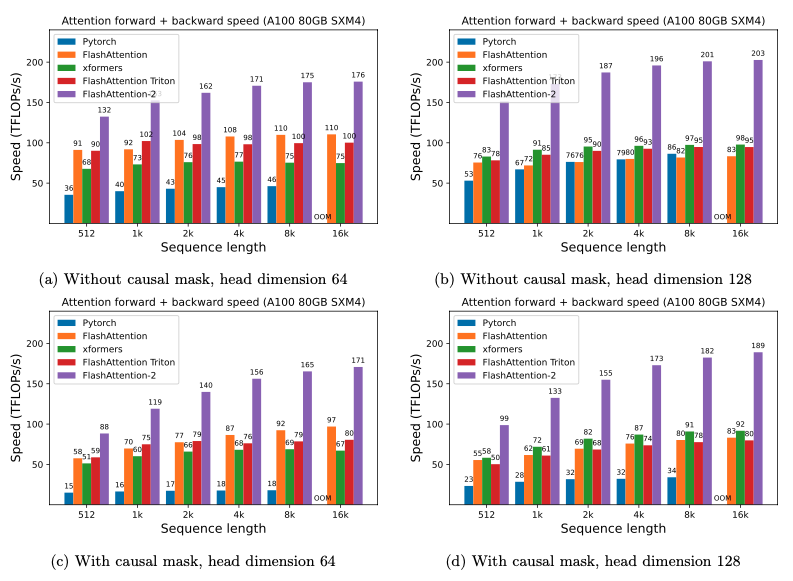
在 A100 GPU 上,FlashAttention-2 在前向傳播中達到了230 TFLOPs/s的峰值,相當于理論最大吞吐量的73%。在后向傳播中,它達到了理論最大吞吐量的 63%。
FlashAttention v3
雖然之前的 FlashAttention 通過減少內存讀寫來加速計算,但它未能充分利用現代硬件(如 Hopper GPU)的新特性。例如,FlashAttention-2 在 H100 GPU 上的利用率僅為 35%。
與 FlashAttention-2 類似,FlashAttention-3 也將任務并行化到不同的線程塊(CTA),但其創新之處在于在單個線程塊內部,將線程束(warps)劃分為不同的角色。
- 生產者(Producer):負責將數據從 HBM(全局內存)異步加載到 SMEM(共享內存)。
- 消費者(Consumer):在數據加載完成后,從 SMEM 讀取數據并執行計算。
生產者和消費者通過一個循環緩沖區(circular buffer)進行同步。生產者將數據放入緩沖區,消費者從中取出。當緩沖區中的一個“階段”被消費后,生產者就可以繼續向其中加載新數據。
線程內部的 GEMM 和 Softmax 重疊
在標準 FlashAttention 中,GEMM 和 Softmax 存在順序依賴:Softmax 必須在第一個 GEMM 計算完成后才能開始,而第二個 GEMM 必須等待 Softmax 的結果。
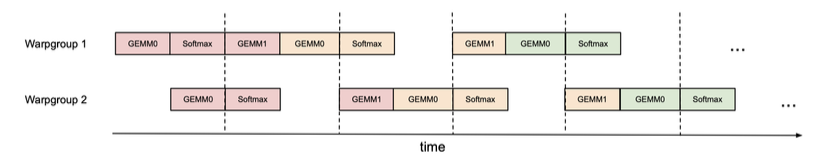
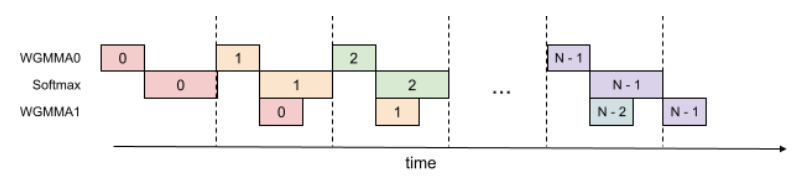
FlashAttention-3 通過在寄存器中使用額外的緩沖區,打破了這種依賴關系。在每次循環中,它異步啟動下一個 GEMM 的計算,而同時執行當前 GEMM 結果的 Softmax 和更新操作。這樣,GEMM 和 Softmax 的執行就可以重疊,提高了效率。
FP8 低精度計算
FP8 的 WGMMA(Warp Group Matrix-Multiply-Accumulate)指令要求輸入矩陣具有特定的k-major 布局,而輸入張量通常是mn-major 布局。

FlashAttention-3 選擇在 GPU 內核中(in-kernel)進行轉置。它利用 LDSM/STSM 指令,這些指令能夠高效地在 SMEM 和 RMEM(寄存器)之間進行數據傳輸,并在傳輸過程中完成布局轉置,避免了代價高昂的 HBM 讀寫。
同于傳統的逐張量(per-tensor)量化,FlashAttention-3 對每個塊進行單獨量化。這使得每個塊可以有自己的縮放因子,從而更有效地處理離群值,減少量化誤差。
實現效果
FlashAttention-3 的前向傳播速度比 FlashAttention-2 快1.5-2.0 倍,后向傳播快1.5-1.75 倍。FP16 版本的 FlashAttention-3 達到了740 TFLOPs/s的峰值,相當于 H100 GPU 理論最大吞吐量的 **75%**。
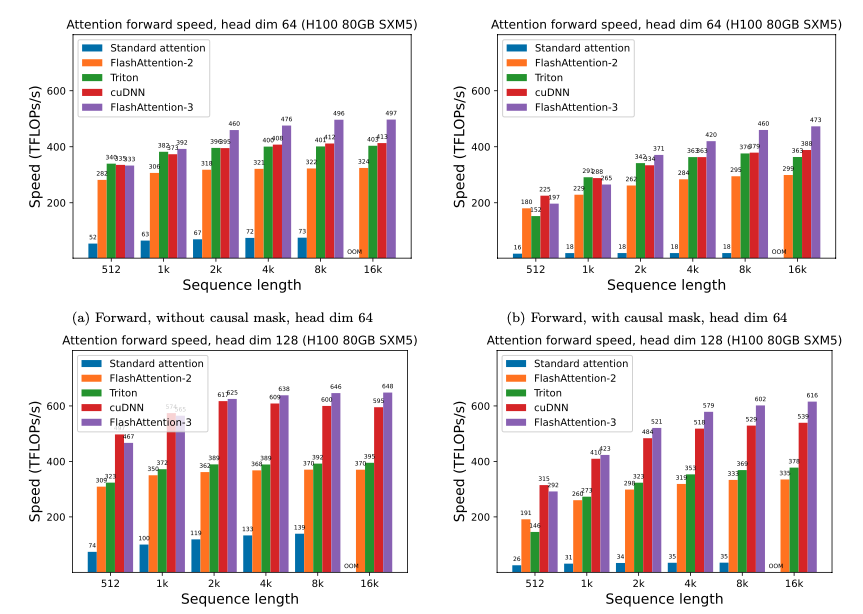
在處理中長序列(1k 及以上)時,FlashAttention-3 的性能甚至超過了 NVIDIA 自家閉源、針對 H100 優化的cuDNN庫。
-
內存
+關注
關注
9文章
3209瀏覽量
76358 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265295 -
大模型
+關注
關注
2文章
3648瀏覽量
5179
發布評論請先 登錄
壓縮模型會加速推理嗎?
3D模型基礎
小白開始學RTOS 1

如何改進和加速擴散模型采樣的方法1
自動駕駛車輛控制(車輛運動學模型)
寫給小白的大模型入門科普

小白學大模型:訓練大語言模型的深度指南
小白學大模型:從零實現 LLM語言模型
小白學大模型:國外主流大模型匯總



 工商網監
工商網監
評論