 基于e-CARE的因果推理相關任務
基于e-CARE的因果推理相關任務

論文名稱:e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
論文作者:杜理,丁效,熊凱,劉挺,秦兵原創作者:杜理出處:哈工大SCIR1. 簡介
因果推理是人類的一項核心認知能力。借助因果推理能力,人類得以理解已觀測到的各種現象,并預測將來可能發生的事件。然而,盡管當下的各類因果推理模型已經在現有的因果推理數據集上取得了令人印象深刻的性能,然而,這些模型與人類的因果推理能力相比仍存在顯著差距。
造成這種差距的原因之一在于,當下的因果推理模型往往僅能夠從數據中捕獲到經驗性的因果模式,但是人類則能夠進一步追求于對于因果關系的相對抽象的深入理解。如圖1中例子所示,當觀察到原因事件: 將石頭加入鹽酸造成結果:石頭溶解 之后,人類往往不會停留在經驗性地觀察現象這一層面,而會進一步深入思考,為什么這一現象能夠存在?通過種種手段,最終得到一個概念性的解釋,即酸具有腐蝕性。值得注意的是,這一對于因果現象的概念性解釋是超越具體的現象本身,能夠解釋一系列相關現象的。借助此類解釋信息,模型將可能產生對于因果命題的更加深入的理解。
雖然這種概念性解釋在因果推理過程中具有相當的重要性,迄今的因果推理數據集中尚未具備這一信息以支撐訓練更強的、更接近人類表現的因果推理模型。為此,我們提供了一個人工標注的可解釋因果推理數據集( explainable CAusal REasoning dataset, e-CARE)。e-CARE數據集包含超過2萬個因果推理問題,這使得e-CARE成為目前最大的因果推理數據集。并且對于每個因果推理問題,提供了一個自然語言描述的,有關于因果關系為何能夠成立的解釋。下表提供了一個e-CARE數據集的例子。
依托于e-CARE數據集,在傳統的多項選擇式的因果推理任務之外,我們還進一步提出了一個因果解釋生成任務,即給定一個因果事件對,模型需要為這個因果事件對生成合理的解釋,并提出了一個新指標衡量解釋生成的質量。
| Key | Value |
|---|---|
| Premise | Tom holds a copper block by hand and heats it on fire. |
| Ask-for | Effect |
| Hypothesis 1 | His fingers feel burnt immediately. () |
| Hypothesis 2 | The copper block keeps the same. () |
| Conceptual Explanation | Copper is a good thermal conductor. |
2. 基于e-CARE的因果推理相關任務
基于e-CARE數據集,我們提出了兩個任務以評價模型因果推理能力:
- 因果推理任務
- 解釋生成任務
2.1 因果推理:
這一任務要求模型從給定的兩個候選hypothesis中選出一個,使得其與給定的premise構成一個合理的因果事實。例如,如下例所示,給定premise "Tom holds a copper block by hand and heats it on fire.", hypothesis 1 "His fingers feel burnt immediately."能夠與給定premise構成合理的因果事件對。
{
"index":"train-0",
"premise":"Tomholdsacopperblockbyhandandheatsitonfire.",
"ask-for":"effect",
"hypothesis1":"Hisfingersfeelburntimmediately.",
"hypothesis2":"Thecopperblockkeepsthesame.",
"label":1
}
2.2 解釋生成:
這一任務要求模型為給定的由<原因,結果>構成的因果事件對生成一個合理解釋,以解釋為何該因果事件對能夠存在。例如, 給定因果事件對<原因: Tom holds a copper block by hand and heats it on fire. 結果: His fingers feel burnt immediately.>, 模型需要生成一個合理的解釋,如"Copper is a good thermal conductor."。
{
"index":"train-0",
"cause":"Tomholdsacopperblockbyhandandheatsitonfire.",
"effect":"Hisfingersfeelburntimmediately.",
"conceptual_explanation":"Copperisagoodthermalconductor."
}
3. 數據集統計信息
- 問題類型分布
| Ask-for | Train | Test | Dev | Total |
|---|---|---|---|---|
| Cause | 7,617 | 2,176 | 1,088 | 10881 |
| Effect | 7,311 | 2,088 | 1,044 | 10443 |
| Total | 14,928 | 4,264 | 2,132 | 21324 |
- 解釋信息數量
| Overall | Train | Test | Dev |
|---|---|---|---|
| 13048 | 10491 | 3814 | 2012 |
4. 解釋生成質量評價指標CEQ Score
當用于評價解釋生成的質量時,經典的生成質量自動評價指標,如BLEU,Rough等僅從自動生成的解釋與給定的人工標注的解釋的文本或語義相似度來評判解釋生成的質量。但是,理想的解釋生成質量評價指標需要能夠直接評價自動生成的解釋是否恰當地解釋了給定的因果事實。為此,我們提出了一個新的解釋生成質量評價指標CEQ Score (Causal Explanation Quality Score)。
簡言之,一個合理的解釋,需要能夠幫助預測模型更好理解因果事實,從而更加合理準確地預測給定事實的因果強度。其中因果強度是一個[0,1]之間的數值,衡量給定因果事實的合理性。因此,對于確證合理的因果事實,其因果強度應該等于1.
因此,我們可以通過衡量生成的解釋能夠為因果強度的度量帶來何種程度的增益,來衡量解釋生成的質量。因此,我們將CEQ定義為:
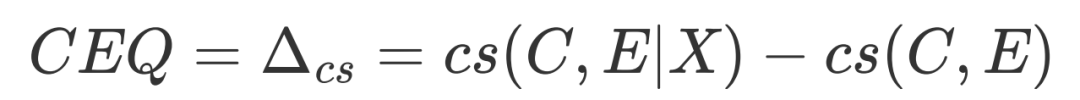
其中,和分別是原因與結果,是因果強度預測模型度量的原始的因果強度,是給定解釋后,因果預測模型給出的因果強度。
值得注意的是,這一指標依賴于具體的因果強度預測方式的選取,以及如何將解釋信息融入因果強度預測過程。在本文中,我們選擇基于統計的、不依賴具體模型的因果強度預測方式CausalNet[5]。CausalNet能夠依賴大語料上的統計信息,得到給定原因與結果間的因果強度。而為將解釋信息融因果強度預測過程以得到,我們定義(其中+為字符串拼接操作):
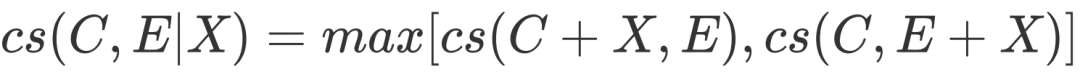
5. 數據集下載與模型性能評價
5.1 數據集下載
模型的訓練與開發集可在以下鏈接下載: https://github.com/Waste-Wood/e-CARE/files/8242580/e-CARE.zip
5.2 模型性能評測
為提升方法結果的可比性,我們提供了leaderboard用以評測模型性能:https://scir-sp.github.io/
6. 實驗結果
6.1 因果推理
表1 因果推理實驗結果
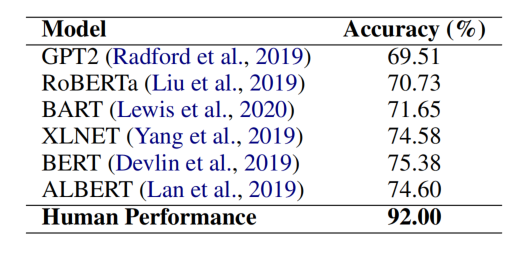
針對多項選擇式的因果推理任務,我們利用一系列預訓練語言模型(均為base-sized版本)進行了實驗。我們使用準確率衡量模型性能。其中,ALBERT取得了最高性能,但是和人類表現(92%)仍有較大差距。這顯示e-CARE所提供的因果推理任務仍為一相對具有挑戰性的任務。
6.2 解釋生成
表2 解釋生成實驗結果

為測試模型在給定因果事實后生成合理的解釋的能力,我們利用經典的GRU-Seq2Seq模型以及GPT2進行了解釋生成實驗。其中,我們使用自動評價指標AVG-BLEU、ROUGH-l、PPL,以及人工評價衡量生成質量。由表2可得,雖然相比于GRU-Seq-Seq,GPT2性能有明顯提高,但是和人類生成的解釋質量相比仍存在巨大差距,尤其在人工評價指標上。這顯示,深度理解因果事實,并為此生成合理解釋仍是相當具有挑戰性的任務。而無法深度理解因果事實也可能是阻礙當前的因果推理模型性能進一步提高的主要因素之一。另一方面,這也一定程度顯示所提出的解釋生成質量評價指標CEQ的合理性。
7. 潛在研究方向
7.1 作為因果知識庫
因果知識對于多種NLP任務具有重要意義。因此,e-CARE中包含的因果知識可能能夠提升因果相關任務上的模型性能。為了驗證這一點,我們首先在e-CARE上微調了e-CARE模型,并將微調后的模型(記作BERTE)分別 遷移至因果抽取數據集EventStoryLine[1]、兩個因果推理數據集BECauSE 2.0[2]和COPA[3],和一個常識推理數據集CommonsenseQA[4]上,并觀察模型性能。如下表所示,e-CARE微調后的模型在四個因果相關任務上均表現出了更好性能。這顯示e-CARE能夠提供因果知識以支撐相關任務上的性能。

表3 知識遷移實驗結果
7.2 支持溯因推理
前期研究將解釋生成過程總結為一個溯因推理過程。并強調了溯因式的解釋生成的重要性,因為它可以與因果推理過程相互作用,促進對因果機制的理解,提高因果推理的效率和可靠性。
例如,如下圖所示,人們可能會觀察到 C1: 將巖石加入鹽酸中 導致 E1: 巖石溶解。通過溯因推理,人們可能會為上述觀察提出一個概念性解釋,即酸具有腐蝕性。之后,可以通過實驗驗證,或者外部資料來確認或糾正解釋。通過這種方式,關于因果關系的知識可以被引入到因果推理過程中。如果解釋得到證實,它可以通過幫助解釋和驗證其他相關的因果事實,來進一步用于支持因果推理過程,例如 C2:將鐵銹加入硫酸可能導致 E2:鐵銹溶解。這顯示了概念解釋在學習和推斷因果關系中的關鍵作用,以及 e-CARE 數據集在提供因果解釋并支持未來對更強大的因果推理系統的研究中可能具有的意義。
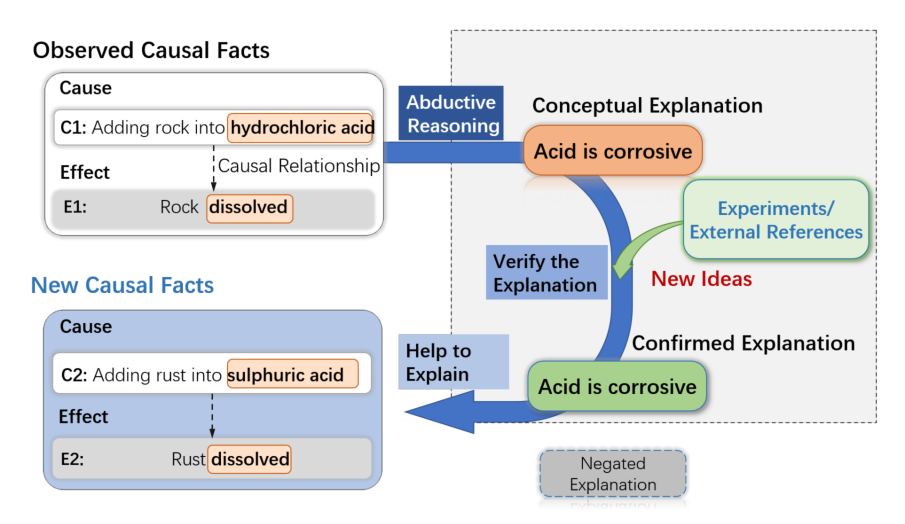
圖1 溯因推理與因果推理關系示意圖
8. 結論
本文關注于因果推理問題中的可解釋性。針對這一點,本文標注了一個可解釋因果推理數據集e-CARE,這一數據集包含21K因果推理問題,并為每個問題提供了一個解釋因果關系為何能夠成立的自然語言形式的解釋。依托于這一數據集,我們進一步提出了一個因果推理和一個因果生成任務。實驗顯示,當前的預訓練語言模型在這兩個任務上仍面臨較大困難。
歡迎大家共同推動因果推理領域的研究進展!
-
推理
+關注
關注
0文章
9瀏覽量
7421 -
數據集
+關注
關注
4文章
1236瀏覽量
26190
原文標題:ACL'22 | e-CARE: 可解釋的因果推理數據集
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
端側推理:FPGA正崛起為“非GPU”陣營的中堅力量

LLM推理模型是如何推理的?

華為數據存儲與「DaoCloud 道客」發布AI推理加速聯合解決方案
使用NVIDIA Grove簡化Kubernetes上的復雜AI推理
今日看點丨華為發布AI推理創新技術UCM;比亞迪汽車出口暴增130%
信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
Aux-Think打破視覺語言導航任務的常規推理范式
大模型推理顯存和計算量估計方法研究
同步任務開發指導
使用MicroPython部署中的ocrrec_image.py推理得到的輸出結果很差,如何解決呢?
詳解 LLM 推理模型的現狀




 工商網監
工商網監
評論