 使用NVIDIA Grove簡化Kubernetes上的復雜AI推理
使用NVIDIA Grove簡化Kubernetes上的復雜AI推理

過去幾年,AI 推理的部署已經從單一模型、單一 Pod 演變為復雜的多組件系統。如今,一個模型部署可能包含多個不同的組件——預填充 (prefill)、解碼 (decode)、視覺編碼器 (vision encoders)、鍵值 (KV) 路由器等。此外,完整的代理式管道正在興起,其中多個模型實例協同工作,執行推理、檢索或多模態任務。
這種轉變將實例擴展和編排的問題從“運行 N 個 Pod 副本”轉變為“將一整個組件協調為一個邏輯系統”。管理此類系統需要同步擴展和調度合適的 Pod,了解每個組件不同的配置和資源需求,按特定的順序啟動,并根據網絡拓撲結構將它們部署在集群中。最終目標是編排整個系統,并基于組件在整個系統的依賴關系進行擴展,而不是一次擴展一個 Pod。
為了應對這些挑戰,我們宣布推出NVIDIA Grove,一個在 Kubernetes 集群上運行現代機器學習推理工作負載的 Kubernetes API。Grove 現已作為模塊化組件集成至NVIDIA Dynamo,它完全開源,可在ai-dynamo/groveGitHub 庫使用。
NVIDIA Grove如何整體性編排推理負載
Grove 能夠將多節點推理部署從單個副本擴展到數據中心規模,支持數萬個 GPU。Grove 可將 Kubernetes 中的整個推理服務系統(例如預填充、解碼、路由或任何其他組件)描述為單個自定義資源 (Custom Resource, CR)。
根據該單一配置文件,平臺可協調層級化調度、拓撲感知的放置、多級自動擴縮容以及明確的啟動順序。您可以精準控制系統的行為方式,而無需將腳本、YAML 文件或自定義控制器拼接在一起。
Grove 最初是為了解決多節點 PD 分離推理系統的編排問題而開發的,它具有足夠的靈活性,可以自然地映射到任何現實世界的推理架構,從傳統的單節點聚合推理到具有多個模型的代理式管道。Grove 使開發者能夠以簡潔、聲明式且與框架無關的方式定義復雜的 AI 堆棧。
多節點PD分離服務的前提條件詳情如下。
多級自動擴縮容以應對相互依賴的組件
現代推理系統需要在多個層面上進行自動擴縮容:單個組件(應對流量高峰的預填充工作節點)、相關組件組(預填充主節點及其工作節點)以及用于擴展整體容量的整體服務副本。這些層級相互依賴:擴展預填充工作節點可能需要更多的解碼能力,而新的服務副本需要合理的組件比例。傳統的 Pod 級自動擴縮容無法處理這些相互依賴關系。
覆蓋恢復與滾動更新的系統級生命周期管理
恢復和更新必須以完整的服務實例為操作對象,而非單個Kubernetes Pod。當預填充工作節點發生故障并重啟后,需要正確地重新連接到其主節點,而滾動更新必須保持網絡拓撲來維持低延遲。平臺必須將多組件系統視為單一操作單元,同時優化其性能和可用性。
靈活的層級化組調度
AI 工作負載調度器應支持靈活的組調度機制,突破傳統的全有或全無的放置方式。PD 分離服務帶來了新的挑戰:推理系統需要保證關鍵組件組合(例如至少一個預填充和一個解碼工作節點),同時允許每種組件類型獨立擴展。挑戰在于,預填充和解碼組件應根據工作負載模式按照不同的比例進行擴展。傳統的組調度將所有組件強制綁定到必須同步擴展的組中,阻礙了這種獨立擴展。系統需要制定策略,確保強制執行最小可行組件組合的同時,實現靈活的擴展。
拓撲感知調度
組件的布局會影響性能。在如NVIDIA 高性能計算平臺這樣的系統上,將相關的預填充 Pod 和解碼 Pod 調度至同一NVIDIA NVLink域內,可優化 KV 緩存的傳輸延遲。調度器需要理解物理網絡拓撲,在將相關組件就近放置的同時,通過分散副本以提高系統的可用性。
角色感知的編排和明確的啟動順序
組件具有不同的職責、配置和啟動要求。例如,預填充和解碼主節點需要執行獨立的啟動邏輯,且工作節點在主節點準備就緒之前無法啟動。為實現可靠的系統初始化,平臺需要針對角色進行特定配置和依賴關系管理。
綜上所述,整體情況可概括為:推理團隊需要一種簡單且聲明式的方法,來描述系統的實際運行狀態(多角色、多節點、明確的多級依賴關系),并使系統能夠根據該描述進行調度、擴展、恢復和更新。
Grove原語
高性能推理框架使用 Grove 層級化 API 來表達角色特定的邏輯和多級擴展,從而在跨多種集群環境中實現一致且優化的部署。Grove 通過在其 Workload API 中使用三種層次化的自定義資源編排多組件 AI 工作負載,來實現這一點。
在圖 1 中,PodClique A 代表前端組件,B 和 C 代表預填充主節點和預填充工作節點,D 和 E 代表解碼主節點和解碼工作節點。
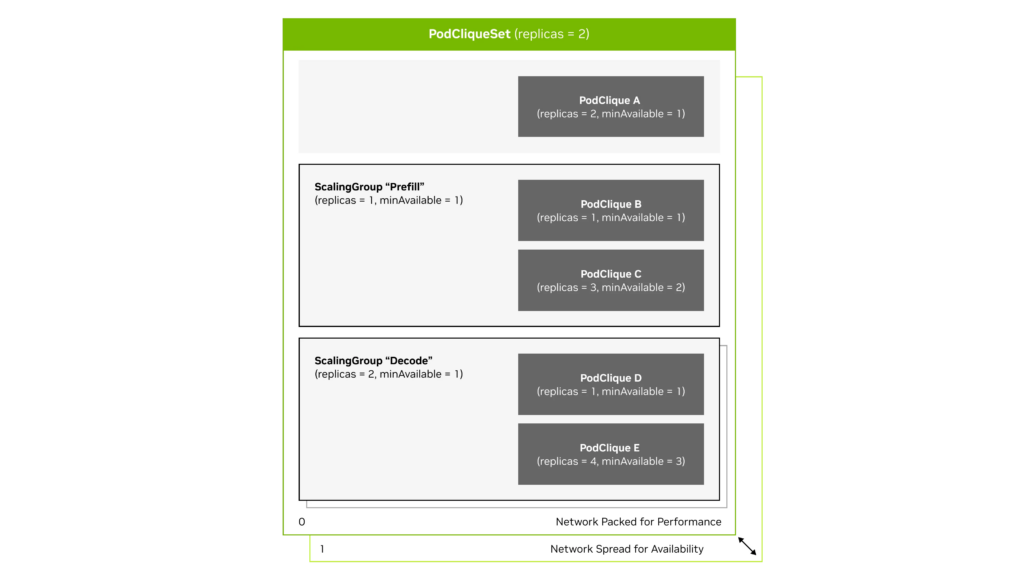
圖 1. NVIDIA Grove 的關鍵組件包括PodClique、 ScalingGroup和 PodCliqueSet,以及它們如何協同工作
PodCliques代表具有特定角色的Kubernetes Pod組,例如預填充主節點或工作節點、解碼主節點或工作節點,以及前端服務,每個組都有獨立的配置和擴展邏輯。
PodCliqueScalingGroups將必須協同擴展的緊密耦合的 PodCliques 進行打包,例如,預填充主節點和預填充工作節點一起代表一個模型實例。
PodCliqueSets定義完整的多組件工作負載,指定啟動順序、擴展策略及組調度約束,以確保所有組件或者一起啟動,或者共同失敗。當需要擴展以增加容量時,Grove 會創建整個 PodGangSet 的完整副本,并定義分布約束,將這些副本分布在集群中以實現高可用性,同時保持每個副本的組件在網絡拓撲上緊密封裝,以優化性能。
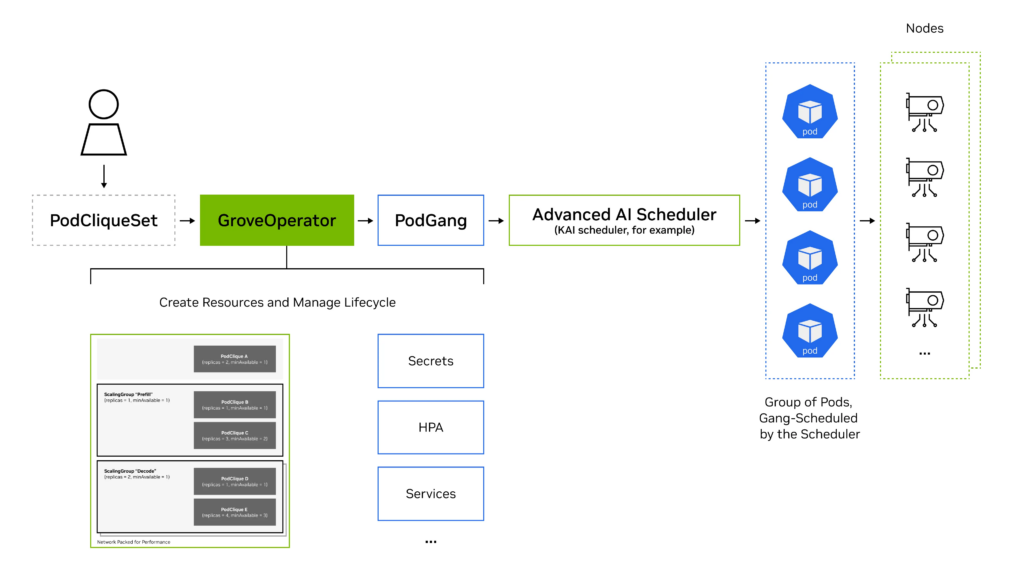
圖 2. Grove 工作流
支持 Grove 的 Kubernetes 集群將整合兩個關鍵組件:Grove 操作器和能夠識別 PodGang 資源的調度器,例如KAI Scheduler,這是NVIDIA Run:ai 平臺的一個開源子組件。
當創建 PodCliqueSet 資源時,Grove operator 會驗證配置清單,并自動生成實現所需的底層 Kubernetes 對象。這包括組成的 PodCliques、PodCliqueScalingGroups,以及相關的 Pod、服務 (Services)、密鑰 (Secrets) 和自動擴縮容策略。在此過程中,Grove 還會創建 PodGang 資源,這是 Scheduler API 的一部分,將工作負載定義轉換為集群調度器的具體調度約束。
每個 PodGang 封裝了其工作負載的詳細要求,包括最低副本保證、優化組件間帶寬的網絡拓撲偏好,以及保持可用性的擴散約束。這些共同確保了拓撲感知的放置和集群中資源的高效利用。
Scheduler 持續監測 PodGang 資源,并應用組調度邏輯,確保所有必要組件在資源可用前共同調度或暫緩調度。調度決策基于GPU 拓撲感知和集群局部性優化生成。
最終結果是多組件 AI 系統的協調部署,其中預填充服務、解碼工作節點和路由組件按正確順序啟動,緊密放置在網絡拓撲上以提高性能,并作為一個整體共同自愈。這防止了資源碎片化,避免了部分部署,并能夠大規模穩定高效地運行復雜的模型服務管道。
如何使用Dynamo快速上手Grove
本節將分享如何使用 Dynamo 和 Grove 通過 KV 路由部署組件部署 PD 分離服務架構。該設置使用Qwen3 0.6B模型,并演示了 Grove 通過獨立的預填充和解碼工作節點管理分布式推理工作負載的能力。
注意:這是一個基礎示例,旨在幫助您理解核心概念。有關更復雜的部署,請參考ai-dynamo/groveGitHub 庫。
先決條件
首先,確保您的 Kubernetes 集群中準備好以下組件:
支持 GPU 的 Kubernetes 集群
已配置 kubectl 以訪問您的集群
安裝 Helm CLI
Hugging Face token密鑰(稱為hf-token-secret),可以使用以下命令創建:
kubectl create secret generic hf-token-secret \ --from-literal=HF_TOKEN=
注意:在代碼中,將
步驟1:創建命名空間
kubectl create namespace vllm-v1-disagg-router
步驟2:使用Grove安裝Dynamo CRD和Dynamo Operator
# 1. Set environment
export NAMESPACE=vllm-v1-disagg-router export RELEASE_VERSION=0.5.1
# 2. Install CRDs
helm fetchhttps://helm.ngc.nvidia.com/nvidia/ai-dynamo/charts/dynamo-crds-${RELEASE_VERSION}.tgz
helm install dynamo-crds dynamo-crds-${RELEASE_VERSION}.tgz --namespace default
# 3. Install Dynamo Operator + Grove
helm fetchhttps://helm.ngc.nvidia.com/nvidia/ai-dynamo/charts/dynamo-platform-${RELEASE_VERSION}.tgz
helm install dynamo-platform dynamo-platform-${RELEASE_VERSION}.tgz --namespace ${NAMESPACE} --create-namespace --set "grove.enabled=true"
步驟3:驗證Grove安裝
kubectl get crd | grep grove
預期輸出:
podcliques.grove.io podcliquescalinggroups.grove.io podcliquesets.grove.io podgangs.scheduler.grove.io podgangsets.grove.io
步驟4:創建DynamoGraphDeployment配置
創建一個DynamoGraphDeployment清單,定義PD分離服務架構,包含一個前端、兩個解碼工作節點和一個預填充工作節點:
apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeployment metadata: name: dynamo-grove spec: services: Frontend: dynamoNamespace: vllm-v1-disagg-router componentType: frontend replicas: 1 extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.5.1 envs: - name: DYN_ROUTER_MODE value: kv VllmDecodeWorker: dynamoNamespace: vllm-v1-disagg-router envFromSecret: hf-token-secret componentType: worker replicas: 2 resources: limits: gpu: "1" extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.5.1 workingDir: /workspace/components/backends/vllm command: - python3 - -m - dynamo.vllm args: - --model - Qwen/Qwen3-0.6B VllmPrefillWorker: dynamoNamespace: vllm-v1-disagg-router envFromSecret: hf-token-secret componentType: worker replicas: 1 resources: limits: gpu: "1" extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.5.1 workingDir: /workspace/components/backends/vllm command: - python3 - -m - dynamo.vllm args: - --model - Qwen/Qwen3-0.6B - --is-prefill-worker
步驟5:部署配置
kubectl apply -f dynamo-grove.yaml
步驟6:驗證部署
驗證operator和Grove Pod已創建:
kubectl get pods -n ${NAMESPACE}
預期輸出:
NAME READY STATUS RESTARTS AGE dynamo-grove-0-frontend-w2xxl 1/1 Running 0 10m dynamo-grove-0-vllmdecodeworker-57ghl 1/1 Running 0 10m dynamo-grove-0-vllmdecodeworker-drgv4 1/1 Running 0 10m dynamo-grove-0-vllmprefillworker-27hhn 1/1 Running 0 10m dynamo-platform-dynamo-operator-controller-manager-7774744kckrr 2/2 Running 0 10m dynamo-platform-etcd-0 1/1 Running 0 10m dynamo-platform-nats-0 2/2 Running 0 10m
步驟7:測試部署
首先,端口轉發前端:
kubectl port-forward svc/dynamo-grove-frontend 8000:8000 -n ${NAMESPACE}
然后測試端點:
curlhttp://localhost:8000/v1/models
或者可以檢查PodClique資源,以查看Grove如何將Pod分組在一起,包括副本計數:
kubectl get podclique dynamo-grove-0-vllmdecodeworker -n vllm-v1-disagg-router -o yaml
準備好了解更多了嗎?
NVIDIA Grove完全開源,可在ai-dynamo/groveGitHub 庫中獲取。我們邀請您在自己的 Kubernetes 環境中使用Dynamo的獨立組件 Grove,或與高性能 AI 推理引擎一起使用。
探索Grove 部署指南并在GitHub或Discord中提問。要了解 Grove 的實際應用,請訪問亞特蘭大KubeCon 2025 上的 NVIDIA 展位。我們歡迎社區提供貢獻、拉取請求并反饋意見。
致謝
感謝所有參與NVIDIA Grove項目開發的開源開發者、測試人員和社區成員的寶貴貢獻,特別感謝SAP (Madhav Bhargava、Saketh Kalaga、Frank Heine)的杰出貢獻和支持。開源因協作而蓬勃發展——感謝您成為Grove的一員。
-
NVIDIA
+關注
關注
14文章
5644瀏覽量
109891 -
AI
+關注
關注
91文章
40198瀏覽量
301797 -
機器學習
+關注
關注
66文章
8558瀏覽量
137060 -
kubernetes
+關注
關注
0文章
267瀏覽量
9501
原文標題:使用 NVIDIA Grove 簡化 Kubernetes 上的復雜 AI 推理
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Kubernetes的Device Plugin設計解讀
NVIDIA 在首個AI推理基準測試中大放異彩
NVIDIA在最新AI推理基準測試中大獲成功
NVIDIA宣布其AI推理平臺的重大更新
使用NVIDIA GPU和SmartNIC的邊緣AI
使用NVIDIA Triton推理服務器簡化邊緣AI模型部署
螞蟻鏈AIoT團隊與NVIDIA合作加速AI推理
TinyAnimal:Grove Vision AI上的動物識別實踐

使用NVIDIA Triton推理服務器來加速AI預測
英偉達推出AI模型推理服務NVIDIA NIM
英偉達推出全新NVIDIA AI Foundry服務和NVIDIA NIM推理微服務
NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案


NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺




 工商網監
工商網監
評論