") Aux-Think打破視覺語言導(dǎo)航任務(wù)的常規(guī)推理范式
Aux-Think打破視覺語言導(dǎo)航任務(wù)的常規(guī)推理范式

Aux-Think,把推理當(dāng)作訓(xùn)練時的助力,而非測試時的負擔(dān),打破視覺語言導(dǎo)航任務(wù)的常規(guī)推理范式
視覺語言導(dǎo)航(VLN)任務(wù)的核心挑戰(zhàn),是讓機器人在復(fù)雜環(huán)境中聽懂指令、看懂世界,并果斷行動。我們系統(tǒng)性地引入推理任務(wù),探索其在導(dǎo)航策略學(xué)習(xí)中的作用,并首次揭示了VLN中的“推理崩塌”現(xiàn)象。研究發(fā)現(xiàn):無論是行動前推理(Pre-Think),還是行動后推理(Post-Think),一旦在測試階段顯式生成推理鏈,反而更容易讓機器人迷失方向。
Aux-Think提出一種更實用的路徑:在訓(xùn)練階段引入推理任務(wù)作為輔助監(jiān)督,引導(dǎo)模型習(xí)得更清晰的決策邏輯;而在測試階段,則徹底省去推理生成,直接進行動作預(yù)測。把推理用在該用的地方,模型在任務(wù)中反而更穩(wěn)、更準、更省。Aux-Think不僅有效避免了測試階段的推理幻覺,也為“推理應(yīng)在何時、如何使用”提供了清晰答案,進一步拓展了數(shù)據(jù)高效導(dǎo)航模型的能力邊界。
? 論文題目:
Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
? 論文鏈接:
https://arxiv.org/abs/2505.11886
?項目主頁:
https://horizonrobotics.github.io/robot_lab/aux-think/
視覺語言導(dǎo)航 (VLN) 的推理策略
在視覺語言導(dǎo)航 (VLN) 任務(wù)中,機器人需要根據(jù)自然語言指令在復(fù)雜環(huán)境中做出實時決策。雖然推理在許多任務(wù)中已有廣泛應(yīng)用,但在VLN任務(wù)中,推理的作用一直未被充分探討。我們是第一個系統(tǒng)性研究推理策略對VLN任務(wù)影響的團隊,發(fā)現(xiàn)現(xiàn)有的推理策略 (Pre-Think和Post-Think) 在測試階段反而導(dǎo)致了較差的表現(xiàn),讓機器人導(dǎo)航失敗。與此不同的是,我們提出的Aux-Think框架通過創(chuàng)新設(shè)計有效解決了這一問題。
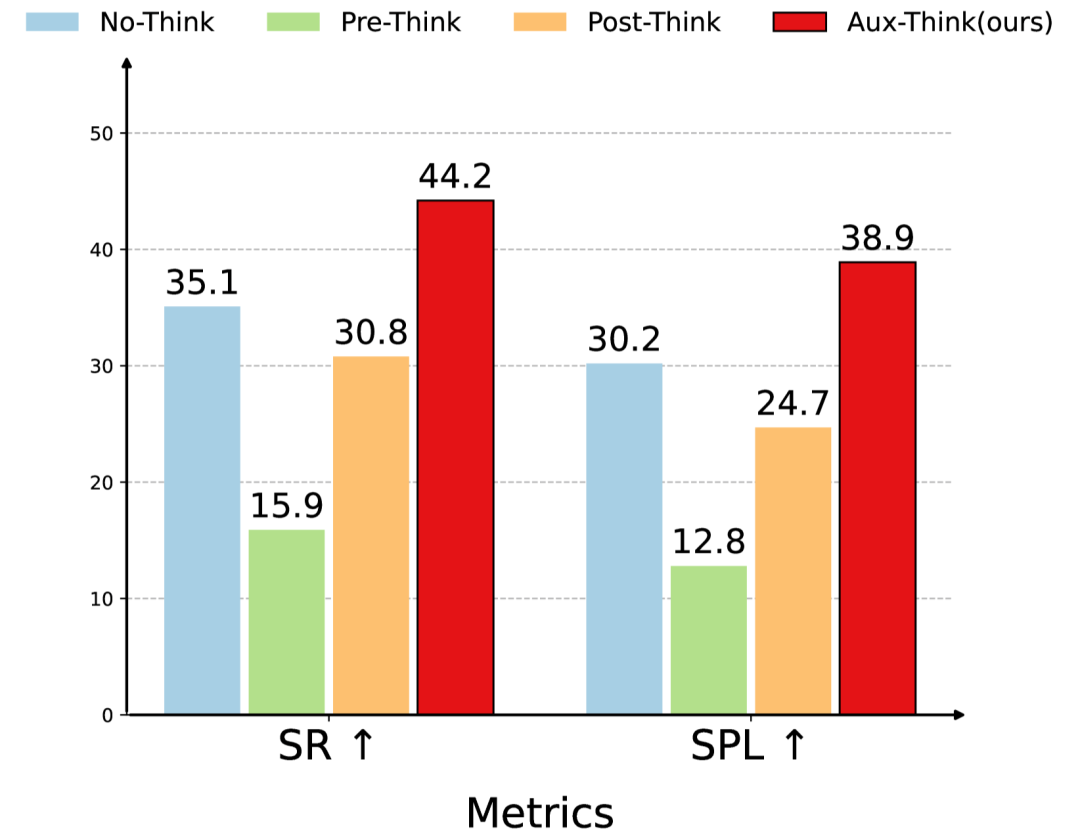
Aux-Think優(yōu)于Pre-Think和Post-Think其它推理策略
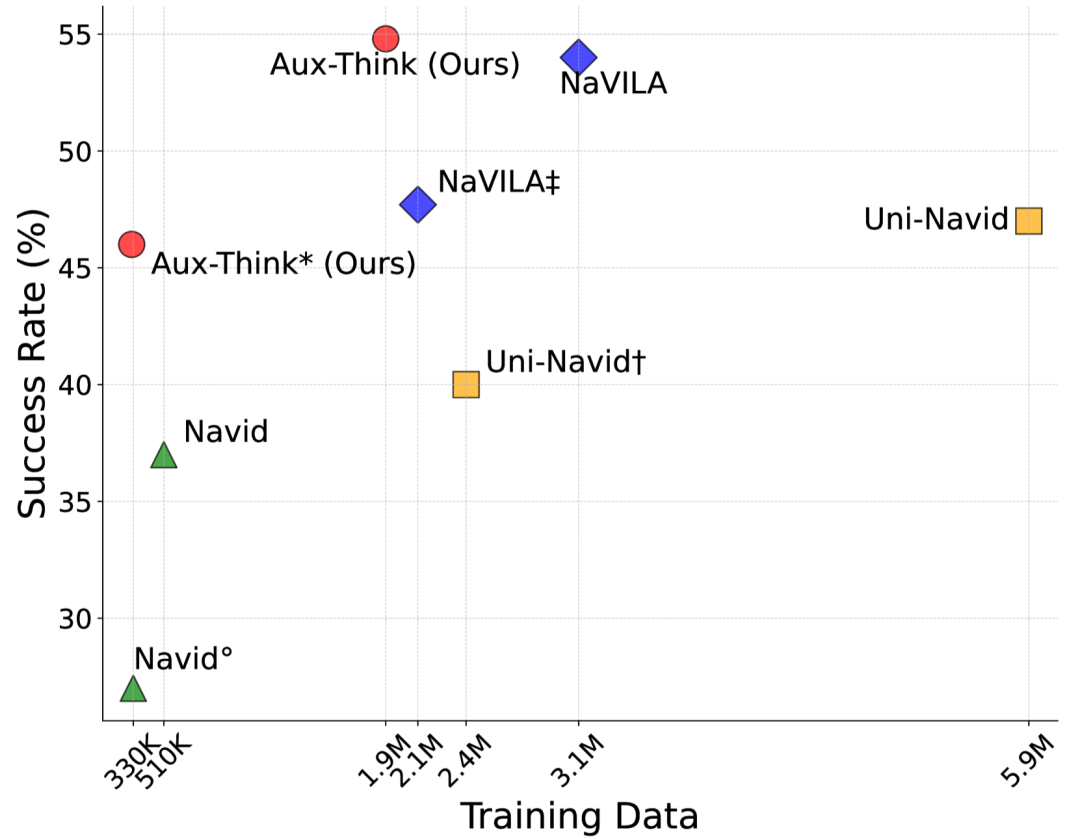
Aux-Think在數(shù)據(jù)效率與成功率之間達到帕累托最優(yōu)
測試階段推理的挑戰(zhàn)
想象一名司機在開車時不斷分析路況,并頻繁回顧交通規(guī)則后才做決策。雖然這有助于理解環(huán)境,但當(dāng)遇到陌生或復(fù)雜情況時,這種“思考過度”的方式反而容易因推理偏差而判斷失誤。
在視覺語言導(dǎo)航任務(wù)中,推理就像回顧交通規(guī)則,決策則對應(yīng)真實的駕駛操作。推理本意是為了幫助機器人理解任務(wù),但一旦進入訓(xùn)練中未見過的狀態(tài),思維鏈便可能產(chǎn)生幻覺。尤其是在不熟悉的環(huán)境中,過度依賴推理不僅無法提升決策,反而干擾行動、累積誤差,最終導(dǎo)致機器人“誤入歧途”。這種“推理崩塌”現(xiàn)象正是Aux-Think希望解決的關(guān)鍵問題。
Aux-Think給出的新答案
為了應(yīng)對上述問題,我們提出了Aux-Think,一種全新的推理訓(xùn)練框架。Aux-Think的核心思想是:在訓(xùn)練階段通過推理指導(dǎo)模型的學(xué)習(xí),而在測試階段,機器人直接依賴訓(xùn)練過程中學(xué)到的知識進行決策,不再進行推理生成。具體來說,Aux-Think將推理和行動分開進行:
訓(xùn)練階段:通過引導(dǎo)模型學(xué)習(xí)推理任務(wù),幫助其內(nèi)化推理模式。
測試階段:直接根據(jù)訓(xùn)練中學(xué)到的決策知識進行行動預(yù)測,不再進行額外的推理生成。
這種設(shè)計有效避免了測試階段推理帶來的錯誤和不穩(wěn)定性,確保機器人能更加專注于執(zhí)行任務(wù),減少了推理過程中可能引入的負面影響。
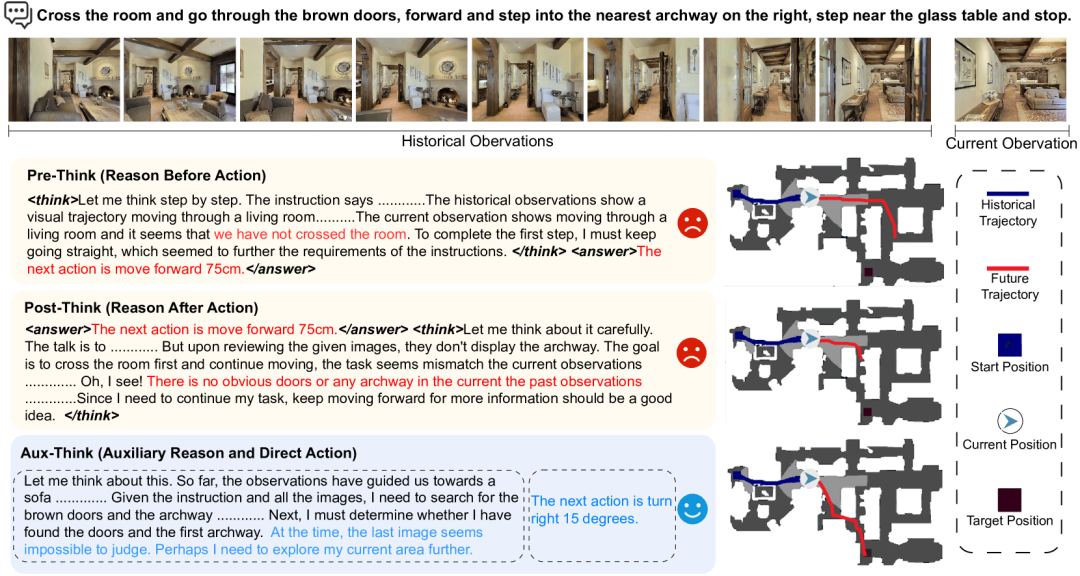
上圖中展示的是一個導(dǎo)航任務(wù):“穿過房間,走到右側(cè)的拱門并停在玻璃桌旁”。三種策略面對相同場景做出了不同反應(yīng):Pre-Think模型在行動前試圖推理整條路徑,認為應(yīng)該“前進75cm”,但忽視了當(dāng)前觀察并未穿過房間,導(dǎo)致偏離目標(biāo);Post-Think模型在執(zhí)行動作后才分析環(huán)境,發(fā)現(xiàn)沒有看到拱門,但錯誤已發(fā)生,只能繼續(xù)試探,繼續(xù)偏航;Aux-Think則在訓(xùn)練時學(xué)習(xí)推理邏輯,測試時直接基于當(dāng)前觀察判斷“右轉(zhuǎn)15度”,準確識別拱門位置,成功完成導(dǎo)航任務(wù)。
實驗結(jié)果
大量實驗表明,Aux-Think在數(shù)據(jù)效率與導(dǎo)航表現(xiàn)方面優(yōu)于當(dāng)前領(lǐng)先方法。盡管訓(xùn)練數(shù)據(jù)較少,Aux-Think仍在多個VLN基準上取得了單目 (Monocular) 方法中的最高成功率。通過僅在訓(xùn)練階段內(nèi)化推理能力,Aux-Think有效緩解了測試階段的推理幻覺與錯誤傳播,在動態(tài)、長程導(dǎo)航任務(wù)中展現(xiàn)出更強的泛化能力與穩(wěn)定性。
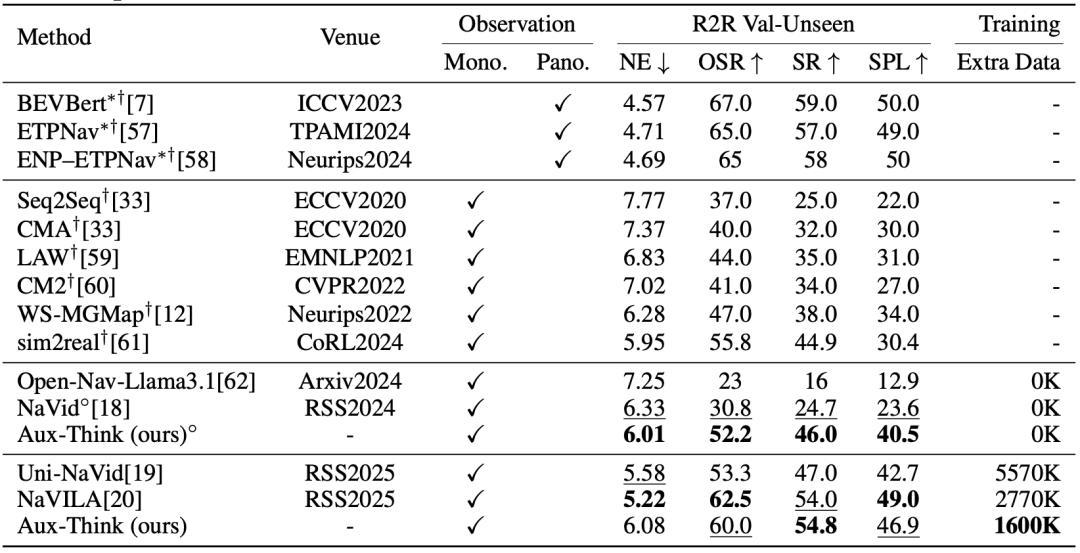
R2R-CE上的指標(biāo):Aux-Think在視覺語言導(dǎo)航任務(wù)的R2R驗證集 (Val-Unseen) 上取得領(lǐng)先的成功率 (SR) ,即使使用的訓(xùn)練數(shù)據(jù)更少,也能超越多種現(xiàn)有方法。
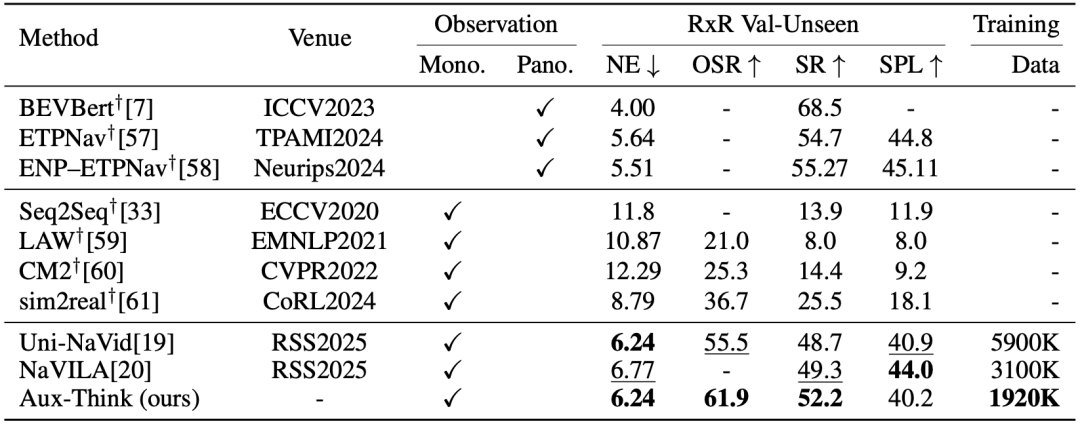
RxR-CE上的指標(biāo):RxR比R2R更大、更復(fù)雜,Aux-Think在RxR驗證集上依然以更少數(shù)據(jù)實現(xiàn)更高成功率 (SR) ,展現(xiàn)出優(yōu)越的泛化能力。
總結(jié)與展望
Aux-Think為解決測試階段推理引發(fā)的導(dǎo)航問題提供了新的思路。通過在訓(xùn)練階段引入推理指導(dǎo),在測試階段去除推理負擔(dān),Aux-Think能夠讓機器人更加專注于任務(wù)執(zhí)行,從而提高其導(dǎo)航穩(wěn)定性和準確性。這一突破性進展將為機器人在實際應(yīng)用中的表現(xiàn)奠定更為堅實的基礎(chǔ),也為具身推理策略提供了重要啟示。
.
-
機器人
+關(guān)注
關(guān)注
213文章
31240瀏覽量
223083 -
導(dǎo)航
+關(guān)注
關(guān)注
7文章
578瀏覽量
44004
原文標(biāo)題:開發(fā)者說|Aux-Think:為什么測試時推理反而讓機器人「誤入歧途」?
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大型語言模型的邏輯推理能力探究
一種在視覺語言導(dǎo)航任務(wù)中提出的新方法,來探索未知環(huán)境
各位高手,我想在汽車導(dǎo)航電路板上加一個aux輸出接口
基于計算機視覺和NLP的跨媒體問答與推理

視覺問答與對話任務(wù)研究綜述

用于語言和視覺處理的高效 Transformer能在多種語言和視覺任務(wù)中帶來優(yōu)異效果
視覺語言導(dǎo)航領(lǐng)域任務(wù)、方法和未來方向的綜述
多維度剖析視覺-語言訓(xùn)練的技術(shù)路線
深度探討VLMs距離視覺演繹推理還有多遠?

基于視覺語言模型的導(dǎo)航框架VLMnav
think-cell:與PowerPoint交換文件
新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺

Progress-Think框架賦能機器人首次實現(xiàn)語義進展推理

面向視覺語言導(dǎo)航的任務(wù)驅(qū)動式地圖學(xué)習(xí)框架MapDream介紹




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論