 使用NVIDIA Jetson AGX Xavier部署新的自主機器
使用NVIDIA Jetson AGX Xavier部署新的自主機器

世界上為人工智能開發者開發的終極嵌入式解決方案, Jetson AGX Xavier ,現在作為獨立的生產模塊從 NVIDIA 發貨。作為自主機器 NVIDIA 的 AGX 系統 的一員, Jetson AGX Xavier 是將先進的人工智能和計算機視覺部署到邊緣的理想選擇,使機器人平臺具有工作站級的性能,并且能夠在不依賴人工干預和云連接的情況下完全自主地運行。由 Jetson AGX Xavier 提供動力的智能機器可以自由地在其環境中進行交互和安全導航,不受復雜地形和動態障礙物的阻礙,完全自主地完成現實世界的任務。這包括包裝交付和工業檢驗,需要先進的實時感知和推理能力。作為世界上第一臺專門為機器人和邊緣計算而設計的計算機, Jetson AGX Xavier 的高性能可以處理視覺里程測量、傳感器融合、定位和映射、障礙物檢測,以及對下一代機器人至關重要的路徑規劃算法。開發人員現在可以開始批量部署新的自主機器。

圖 1 。 Jetson AGX Xavier 帶熱傳遞板( TTP )的嵌入式計算模塊, 100x87mm
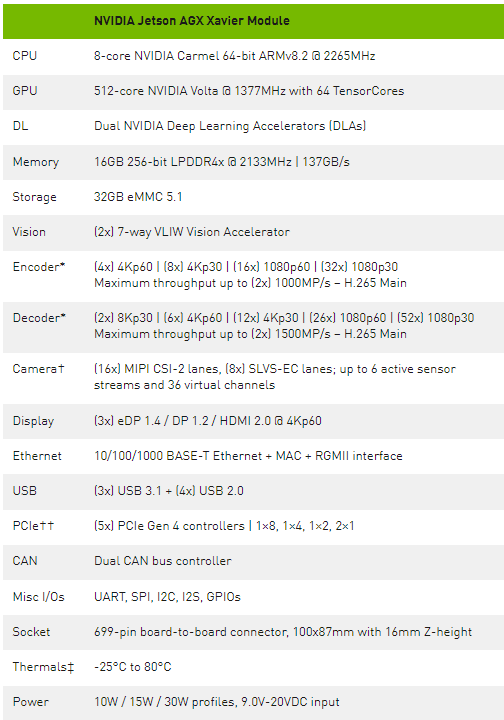
最新一代 NVIDIA 業界領先的嵌入式 Linux 高性能計算機 Jetson AGX 系列, Jetson AGX Xavier 以 100x87mm 的緊湊型外形,提供了 GPU 工作站級的性能和無與倫比的 32 兆兆( TOPS )峰值計算和 750Gbps 的高速 I / O 。用戶可以根據應用需要配置 10W 、 15W 和 30W 的工作模式。 Jetson AGX Xavier 為可部署到邊緣的計算密度、能源效率和人工智能推斷能力設置了新的標準,使具有端到端自主能力的下一級智能機器成為可能。
Jetson 通過深度學習和計算機視覺,為許多世界上最先進的機器人和自動機器提供人工智能,同時專注于性能、效率和可編程性。 Jetson AGX Xavier ,如圖 2 所示,由超過 90 億個晶體管組成,基于有史以來最復雜的片上系統( SoC )。該平臺包括集成的 512 核 NVIDIA Volta GPU ,包括 64 張量核 、 8 核 NVIDIA Carmel ARMv8 。 2 64 位 CPU 、 16GB 256 位 LPDDR4x 、雙 NVIDIA 深度學習加速器 ( DLA )引擎、 NVIDIA 視覺加速器引擎、高清視頻編解碼器、 128Gbps 專用攝像頭攝取和 16 通道 PCIe Gen 4 擴展。 256 位接口上的內存帶寬為 137GB / s ,而 DLA 引擎減輕了深度神經網絡( DNNs )的推理任務。 NVIDIA 的 jetpacksdk4 。 1 。 1 適用于 Jetson AGX Xavier 的 jetpacksdk4 。 1 。 1 包括 CUDA 10 。 0 、 cuDNN 7 。 3 和 TensorRT 5 。 0 ,提供了完整的 AI 軟件棧。
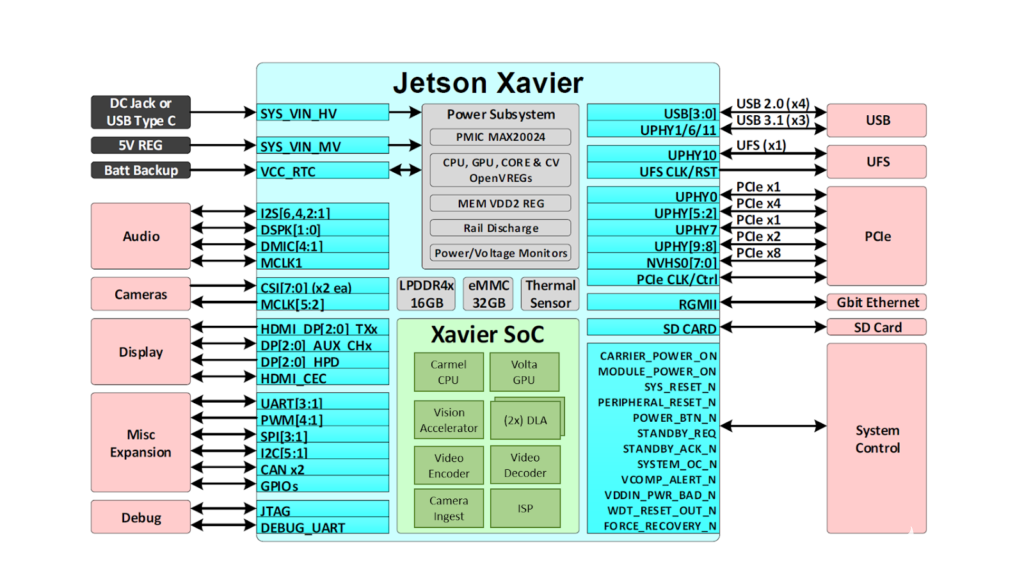
圖 2 。 Jetson AGX Xavier 提供了豐富的高速 I / O
這使得開發者能夠在機器人、智能視頻分析、醫療儀器、嵌入式物聯網邊緣設備等應用中部署加速人工智能。和它的前輩 Jetson TX1 和 TX2 一樣, Jetson AGX Xavier 使用的是模塊上系統( SoM )范式。所有的處理都包含在計算模塊上,高速 I / O 通過高密度板對板連接器提供的分接載體或外殼上。以這種方式將功能封裝在模塊上,使開發人員能夠輕松地將 Jetson Xavier 集成到他們自己的設計中。 NVIDIA 發布了全面的 文檔 和參考設計文件,可供嵌入式設計師使用 Jetson AGX Xavier 創建自己的設備和平臺。請務必參考 Jetson AGX Xavier 模塊數據表 和 Jetson AGX Xavier OEM 產品設計指南 了解表 1 中列出的全部產品功能,此外還有 eleCTR 機械規范、模塊引腳輸出、電源順序和信號布線指南。
Jetson AGX Xavier 包括超過 750Gbps 的高速 I / O ,為流式傳感器和高速外圍設備提供了超常的帶寬。它是最早支持 PCIe Gen 4 的嵌入式設備之一,在五個 PCIe Gen 4 控制器上提供 16 個通道,其中三個控制器可以在根端口或端點模式下運行。 16 個 MIPI CSI-2 通道可連接到 4 個 4 通道攝像頭、 6 個 2 通道攝像頭、 6 個 1 通道攝像頭,或這些配置的組合(最多 6 個攝像頭), 36 個虛擬通道允許使用流聚合同時連接更多攝像頭。其他高速 I / O 包括三個 USB 3 。 1 端口、 SLVS-EC 、 UFS 和用于千兆以太網的 RGMII 。開發者現在可以訪問 NVIDIA 的 JetPack 4 。 1 。 1 開發者預覽 軟件,用于 Jetson AGX Xavier ,如表 2 所示。開發者預覽版包括 Linux For Tegra ( L4T ) R31 。 1 Board Support Package ( BSP ),目標系統支持 Linux 內核 4 。 9 和 Ubuntu18 。 04 。在主機端, Jetpack4 。 1 。 1 支持 Ubuntu16 。 04 和 Ubuntu18 。 04 。
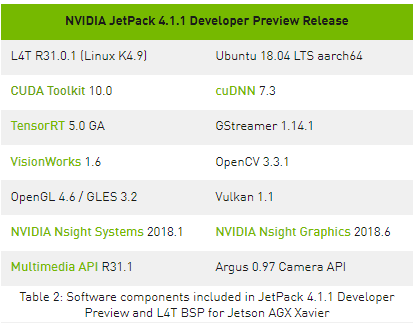
Jetpack4 。 1 。 1 開發者預覽版允許開發者立即使用 Jetson AGX Xavier 開始產品和應用程序的原型制作,為生產部署做準備。 NVIDIA 將繼續對 JetPack 進行改進,并提供額外的功能增強和性能優化。請閱讀 發行說明 了解本版本的亮點和軟件狀態。
Volta GPU
如圖 3 所示, Jetson AGX Xavier 集成 Volta GPU 提供 512 個 CUDA 核和 64 個張量核心,可用于高達 11 TFLOPS FP16 或 22 個 INT8 compute 頂部,最大時鐘頻率為 1 。 37GHz 。它支持計算能力為 sm _的 CUDA 10 , GPU 包括 8 個 Volta 流式多處理器( sm ),每個 Volta sm 有 64 個 CUDA 核和 8 個張量核。每個 Volta SM 都包括一個 128KB 的 L1 緩存,比前幾代大 8 倍。 SMs 共享一個 512KB 的二級緩存,訪問速度比前幾代快 4 倍。

圖 3 。 Jetson AGX Xavier 電壓 GPU 方框圖
每個 SM 由 4 個獨立的處理塊組成,稱為 SMPs (流式多處理器分區),每個處理塊包括自己的 L0 指令緩存、 warp 調度器、調度單元和寄存器文件,以及 CUDA 內核和 Tensor 內核。每個 SM 的 smp 數量是 Pascal 的兩倍, Volta SM 的特點是改進了并發性,并且支持更多的線程、扭曲和線程塊。
張量核
NVIDIA 張量核心是可編程的融合矩陣乘法和累加單元,它們與 CUDA 核心并行執行。張量核實現了新的浮點 HMMA (半精度矩陣乘法和累加)和 IMMA (整數矩陣乘法和累加)指令,用于加速密集線性代數計算、信號處理和深度學習推理。
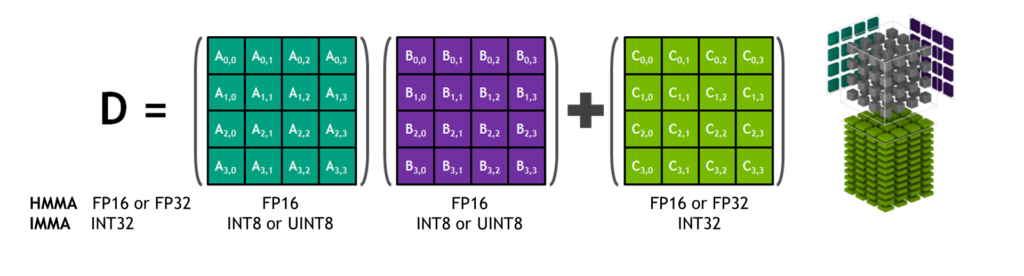
圖 4 。張量核 HMMA / IMMA 4x4x4 矩陣乘法和累加
矩陣乘法輸入 A 和 B 是 HMMA 指令的 FP16 矩陣,而累加矩陣 C 和 D 可以是 FP16 或 FP32 矩陣。對于 IMMA ,矩陣乘法輸入 A 是有符號或無符號的 INT8 或 INT16 矩陣, B 是有符號或無符號的 INT8 矩陣, C 和 D 累加器矩陣都是有符號 INT32 。因此,精度和計算范圍足以避免內部積累期間的溢出和下溢情況。
NVIDIA 庫包括 cuBLAS 、 cuDNN 和 TensorRT 已被更新,以在內部利用 HMMA 和 IMMA ,使程序員能夠輕松地利用張量核固有的性能增益。用戶還可以通過在 wmma 名稱空間和 CUDA 10 中包含的 mma 。 h 頭文件中公開的新 API ,直接訪問 warp 級別的 Tensor 核心操作。 warp 級別的接口在每個 warp 的所有 32 個線程上映射 16 × 16 、 32 × 8 和 8 × 32 大小的矩陣。
深度學習加速器
Jetson AGX Xavier 具有兩個 NVIDIA 深度學習加速器 ( DLA )引擎,如圖 5 所示,它們減輕了固定函數卷積神經網絡( CNN )的推理。這些引擎提高了能源效率,并釋放了 GPU 來運行更復雜的網絡和用戶執行的動態任務。 NVIDIA DLA 硬件體系結構是開源的,可從 NVDLA 。 org 網站 獲得。每個 DLA 具有高達 5 個 TOP INT8 或 2 。 5 TFLOPS FP16 性能,功耗僅為 0 。 5-1 。 5W 。 DLA 支持加速 CNN 層,如卷積、反褶積、激活函數、最小/最大/平均池、本地響應規范化和完全連接層。
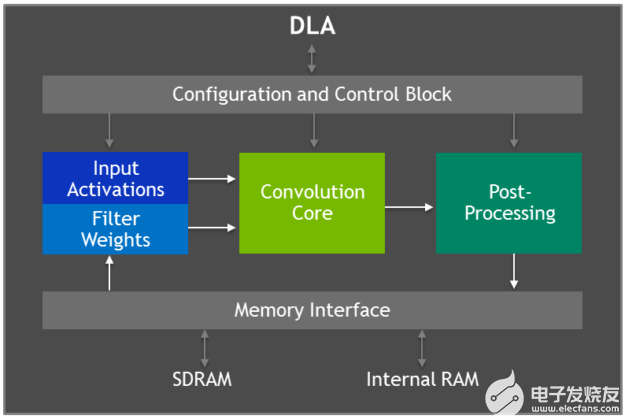
圖 5 。深度學習加速器( DLA )架構框圖
DLA 硬件由以下組件組成:
卷積核心 – 優化的高性能卷積引擎。
單數據處理器 – 激活功能的單點查找引擎。
平面數據處理器 – 用于池的平面平均引擎。
通道數據處理器–用于高級標準化功能的多通道平均引擎。
專用內存和數據整形引擎 – 用于張量整形和復制操作的內存到內存轉換加速。
開發人員使用 TensorRT 5 。 0 編程 DLA 引擎,在網絡上執行推斷,包括對 AlexNet 、 GoogleNet 和 ResNet-50 的支持。對于使用 DLA 不支持的層配置的網絡, TensorRT 為無法在 DLA 上運行的層提供 GPU 回退。 Jetpack4 。 0 開發者預覽版最初將 DLA 的精度限制在 FP16 模式,在未來的 JetPack 版本中, DLA 的 INT8 精度和更高的性能將會出現。
TensorRT 5 。 0 在其 IBuilder 接口中添加了以下 API 以啟用 DLA :
setDeviceType() 和 setDefaultDeviceType() 用于選擇 GPU 、 DLA ? 0 或 DLA ? 1 以執行特定層,或默認情況下用于網絡中的所有層。
canRunOnDLA() 檢查層是否可以按配置在 DLA 上運行。
getMaxDLABatchSize() 用于檢索 DLA 可以支持的最大批處理大小。
allowGPUFallback() 使 GPU 能夠執行 DLA 不支持的層。
請參考 TensorRT 5 。 0 開發人員指南 的第 6 章,了解 TensorRT 中支持的層配置和使用 DLA 的代碼示例的完整列表。
深度學習推斷基準
我們已經為 GPU AGX Xavier 發布了 深度學習推斷基準結果 ,這些 dnn 包括 ResNet 、 GoogleNet 和 VGG 的變體。我們在 Jetson AGX Xavier 的 Jetson 和 DLA 引擎上使用 jetpack4 。 1 。 1 開發者預覽版 TensorRT 5 。 0 為 Jetson AGX Xavier 運行這些基準測試。 GPU 和兩個 dla 分別以 INT8 和 FP16 精度并行運行相同的網絡體系結構,并報告每個配置的總體性能。 GPU 和 dla 可以在現實世界的用例中同時運行不同的網絡或網絡模型,以并行方式或在處理管道中彼此并行地提供獨特的功能。在 TensorRT 中使用 INT8 與全 FP32 精度相比,會導致精度損失 1% 或更少。
首先,讓我們考慮一下 ResNet-18fcn ( Fully-compolutional Network )的結果,它是一個用于語義分割的 2048 × 1024 分辨率的全高清模型。分段為自由空間檢測和占用率映射等任務提供了每像素分類,并代表了由自主機器計算的用于感知、路徑規劃和導航的深度學習工作負載。圖 6 顯示了在 Jetson AGX Xavier 和 Jetson TX2 上運行 ResNet-18 FCN 的測量吞吐量。
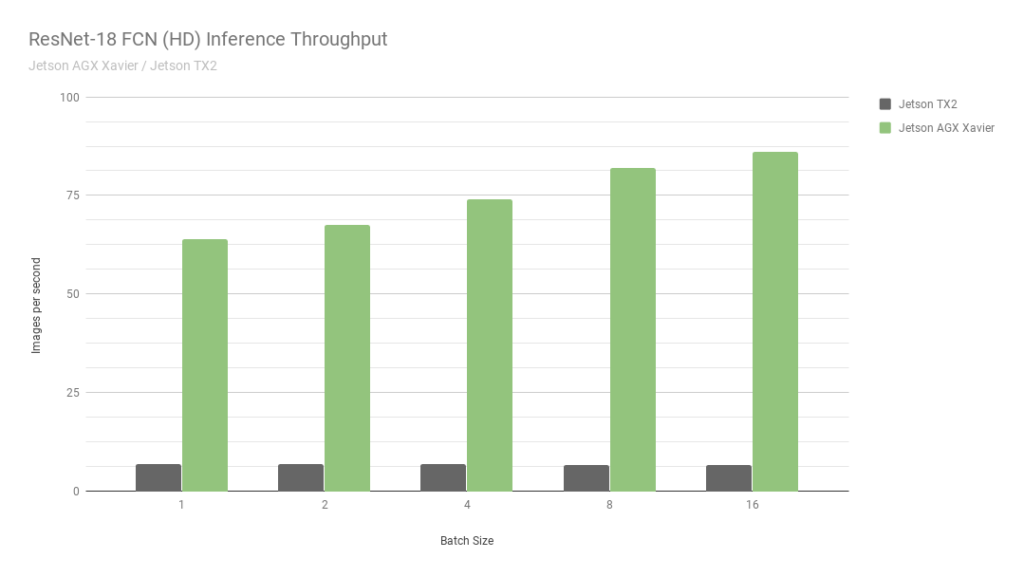
圖 6 。 ResNet-18 FCN 推斷 Jetson AGX Xavier 和 Jetson TX2 的吞吐量
Jetson AGX Xavier 目前在 ResNet-18 FCN 推理中的性能是 Jetson TX2 的 13 倍。 NVIDIA 將繼續在 JetPack 中發布軟件優化和功能增強,隨著時間的推移,將進一步提高性能和功率特性。請注意, 基準結果 的完整列表報告了 Jetson AGX Xavier 的 ResNet-18 FCN 的性能,但在圖 7 中,我們只繪制了批量大小為 16 的 ResNet-18 FCN ,因為 Jetson TX2 能夠運行 ResNet-18 FCN ,最大批量為 16 。
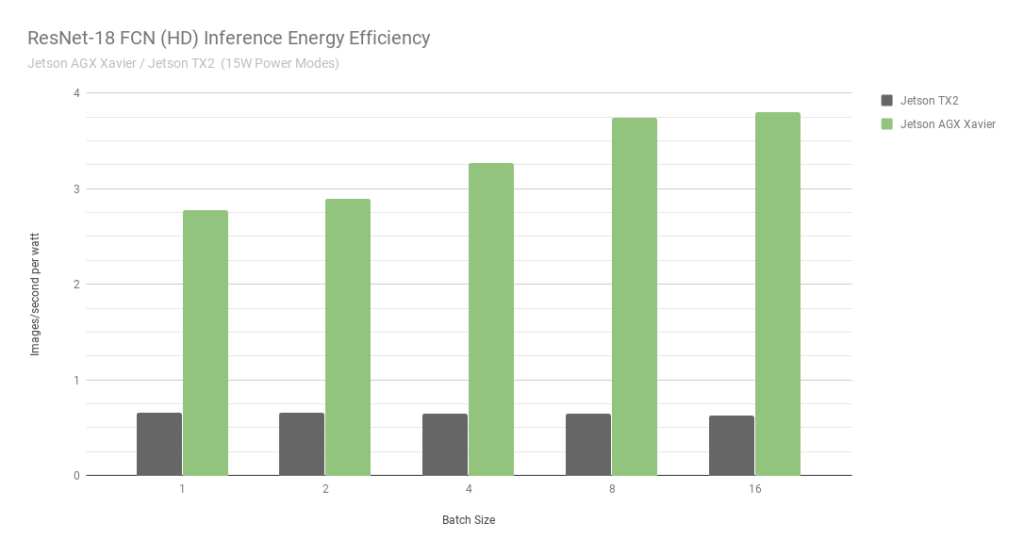
圖 7 。 ResNet-18 FCN 推斷 Jetson AGX Xavier 和 Jetson TX2 的能量效率
當考慮使用每秒處理的每瓦特圖像的能效時, Jetson AGX Xavier 目前比 ResNet-18 FCN 的 Jetson TX2 高 6 倍。我們通過使用板載 INA 電壓和電流監測器測量總模塊功耗來計算效率,包括 CPU 、 GPU 、 DLA 、內存、其他 SoC 功率、 I / O 和所有軌道上的調節器效率損失。兩臺 Jetson 都在 15W 電源模式下運行。 Jetson AGX Xavier 和 JetPack 飛船,具有 10W 、 15W 和 30W 的可配置預設功率配置文件,可在運行時使用 nvpmodel 電源管理工具進行切換。用戶還可以使用不同的時鐘和 DVFS (動態電壓和頻率縮放)調速器設置來定義自己的自定義配置文件,這些設置已經過定制,以實現單個應用的最佳性能。
接下來,讓我們比較一下圖像識別網絡 ResNet-50 和 VGG19 上的 Jetson AGX Xavier 基準測試,這些基準測試的批量大小從 1 到 128 與 Jetson TX2 。這些模型對分辨率為 224 × 224 的圖像塊進行分類,常用作各種目標檢測網絡中的編碼器主干。在較低分辨率下使用 8 或更高的批處理大小可用于近似處理較高分辨率下批大小為 1 的性能和延遲。機器人平臺和自主機器通常包含多個攝像機和傳感器,除了執行感興趣區域( ROI )的檢測,然后分批對 ROI 進行進一步分類,這些攝像頭和傳感器可以批量處理以提高性能。圖 8 還包括對 Jetson AGX Xavier 未來性能的估計,包括軟件增強功能,如 INT8 對 DLA 的支持和 GPU 的其他優化。
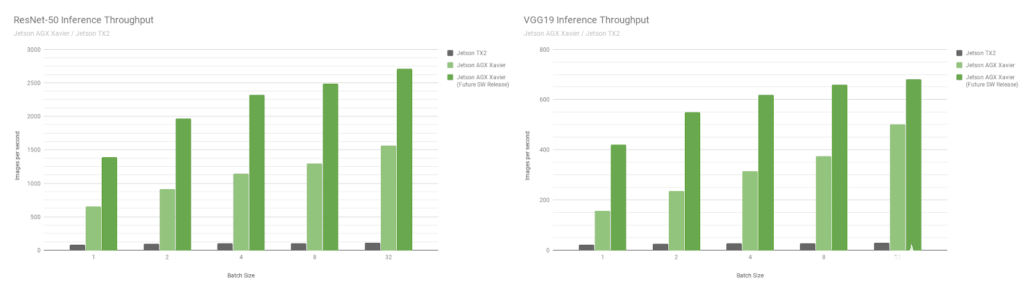
圖 8 。 INT8 支持 DLA 和其他 GPU 優化后的估計性能
Jetson AGX Xavier 目前在 VGG19 上的 Jetson TX2 和 ResNet-50 上的吞吐量分別達到 18 倍和 14 倍,如圖 9 所示。延遲為 65 。 5 秒,或凈大小為 65 。 5 秒/秒。隨著未來軟件的改進, Jetson AGX Xavier 預計將比 Jetson TX2 快 24 倍。請注意,對于遺留比較,我們還提供了完整的 性能列表 中的 GoogleNet 和 AlexNet 的數據。
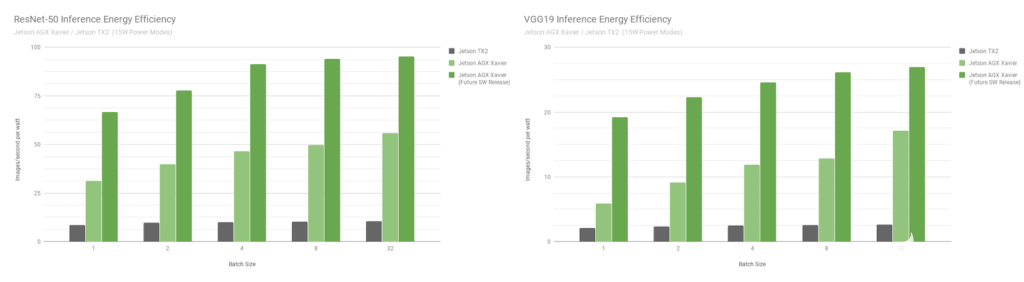
圖 9 。 Jetson Xavier 和 Jetson TX2 的 ResNet-50 和 VGG19 能效
Jetson AGX Xavier 目前在 VGG19 推理方面的效率比 Jetson TX2 高 7 倍多,使用 ResNet-50 的效率高 5 倍,考慮到未來的軟件優化和增強,效率提高了 10 倍。參考完整的 績效結果 來獲取更多的數據和關于推斷基準的細節。我們還將在下一節中對 CPU 的性能進行基準測試。
卡梅爾 CPU 復合體
圖 10 所示的 Jetson AGX Xavier 的 CPU 復合體由四個基于 ARMv8 。 2 的異構雙核 NVIDIA CarmelCPU 簇組成,最大時鐘頻率為 2 。 26GHz 。每個核心包括 128KB 指令和 64KB 數據一級緩存,以及兩個內核之間共享的 2MB 二級緩存。 CPU 集群共享一個 4MB 的 L3 緩存。
關于作者
Dustin Franklin 是 NVIDIA 的 Jetson 團隊的開發人員布道者。 Dustin 擁有機器人和嵌入式系統方面的背景,他樂于在社區中提供幫助,并與 Jetson 一起參與項目。你可以在 NVIDIA Developer Forums 或 Github 上找到他。
審核編輯:郭婷
-
機器人
+關注
關注
213文章
31079瀏覽量
222229 -
cpu
+關注
關注
68文章
11279瀏覽量
224975 -
NVIDIA
+關注
關注
14文章
5594瀏覽量
109729
發布評論請先 登錄
如何在NVIDIA Jetson AGX Thor上部署1200億參數大模型

如何在NVIDIA Jetson平臺上運行最新的開源AI模型
如何在NVIDIA Jetson Thor上提升機器人感知效率
NVIDIA Jetson系列開發者套件助力打造面向未來的智能機器人
如何在NVIDIA Jetson AGX Thor上通過Docker高效部署vLLM推理服務

NVIDIA Jetson AGX Thor Developer Kit開發環境配置指南
ADI借助NVIDIA Jetson Thor平臺加速人形機器人研發進程
NVIDIA Jetson AGX Thor開發者套件重磅發布
NVIDIA三臺計算機解決方案如何協同助力機器人技術
基于 NVIDIA Blackwell 的 Jetson Thor 現已發售,加速通用機器人時代的到來




 工商網監
工商網監
評論