") 其實機器學(xué)習(xí)中圖神經(jīng)網(wǎng)絡(luò)沒那么重要?
其實機器學(xué)習(xí)中圖神經(jīng)網(wǎng)絡(luò)沒那么重要?

圖神經(jīng)網(wǎng)絡(luò)(GNN)是機器學(xué)習(xí)中最熱門的領(lǐng)域之一,在過去短短數(shù)月內(nèi)就有多篇優(yōu)秀的綜述論文。但數(shù)據(jù)科學(xué)家 Matt Ranger 對 GNN 卻并不感冒。他認為這方面的研究會取得進展,但其他研究方向或許更重要。
機器之心對這篇博客進行了編譯整理,以下是博客內(nèi)容。
模型的關(guān)鍵是壓縮
圖經(jīng)常被認為是一種「非歐幾里得」數(shù)據(jù)類型,但實際上并不是。正則圖(regular graph)只是研究鄰接矩陣的另一種方式:
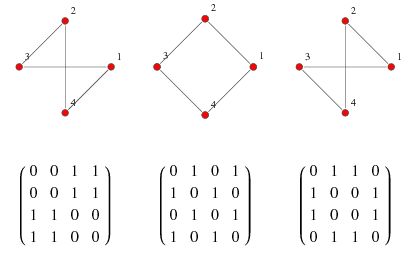
如上圖所示,充滿實數(shù)的矩陣卻被稱為「非歐幾里得」,這很奇怪。
其實這是出于實際原因。大多數(shù)圖都相當稀疏,因此矩陣中會包含很多 0。從這個角度看,非零數(shù)值非常重要,這讓問題接近于(計算上很難的)離散數(shù)學(xué),而不是(容易的)連續(xù)、梯度友好的數(shù)學(xué)。
有了全矩陣,情況會變得容易
如果不考慮物理領(lǐng)域的內(nèi)容,并假設(shè)存在全鄰接矩陣,那么很多問題就會迎刃而解。
首先,網(wǎng)絡(luò)節(jié)點嵌入不再是問題。一個節(jié)點就是矩陣中的一行,因此它本身已經(jīng)是數(shù)字向量。
其次,所有網(wǎng)絡(luò)預(yù)測問題也都被解決。一個足夠強大且經(jīng)過良好調(diào)整的模型將只提取網(wǎng)絡(luò)與附加到節(jié)點上的目標變量之間的全部信息。
NLP 也只是一種花哨的矩陣壓縮
讓我們把目光從圖轉(zhuǎn)移到自然語言處理(NLP)領(lǐng)域。大多數(shù) NLP 問題都可以看成圖問題,所以這并不是題外話。
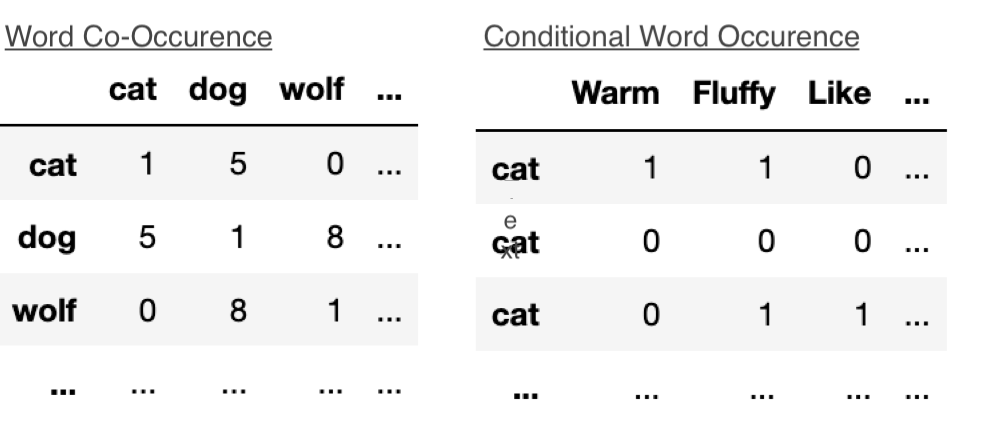
首先,像 Word2Vec、GloVe 這類經(jīng)典詞嵌入模型只進行了矩陣分解。
GloVe 算法基于詞袋(bag of words)矩陣的一種變體運行。它會遍歷句子,并創(chuàng)建一個(隱式)共現(xiàn)圖,圖的節(jié)點是詞,邊的權(quán)重取決于這些單詞在句子中一同出現(xiàn)的頻率。之后,Glove 對共現(xiàn)圖的矩陣表示進行矩陣分解,Word2Vec 在數(shù)學(xué)方面是等效的。
語言模型也只是矩陣壓縮
NLP 中許多 SOTA 方法都離不開語言模型。以 BERT 為例,BERT 基于語境來預(yù)測單詞:
這就使我們正在分解的矩陣從詞對共現(xiàn)發(fā)展為基于句子語境的共現(xiàn):
我們正在培養(yǎng)待分解的「理想矩陣」。正如 Hanh & Futrell 所說:
人類語言和語言建模具有無限的統(tǒng)計復(fù)雜度,但可以在較低層次上得到很好地近似。這一觀察結(jié)果有兩層含義:
我們可以使用相對較小的模型獲得不錯的結(jié)果;擴大模型具備很大潛力。
語言模型解決了很大的問題空間,以至于從柯氏復(fù)雜性(Kolmogorov Complexity)角度來看,它們可能近似壓縮了整個語言。龐大的語言模型可能記住了很多信息,而不是壓縮信息。
我們能像語言模型一樣對任意圖執(zhí)行上采樣嗎?
實際上,我們已經(jīng)在做了。
我們將圖的「一階」嵌入稱為通過直接分解圖的鄰接矩陣或拉普拉斯矩陣(Laplacian matrix)來運行的方法。只要使用拉普拉斯特征映射(Laplacian Eigenmap)或采用拉普拉斯的主要組成部分進行圖嵌入,那它就是一階方法。類似地,GloVe 是詞共現(xiàn)圖上的一階方法。我最喜歡的圖一階方法之一是 ProNE,它和大多數(shù)方法一樣有效,但速度快了一個數(shù)量級。
高階方法嵌入了原始矩陣和鄰居的鄰居連接(第二階)以及更深的 k 步連接。GraRep 表明,通過擴展圖矩陣可以基于一階方法生成高階表示。
高階方法是在圖上執(zhí)行的上采樣。基于大型鄰域采樣的 GNN 和 node2vec 等隨機游走方法執(zhí)行的是高階嵌入。
性能增益在哪兒?
過去 5 年中,大多數(shù) GNN 論文的實驗數(shù)據(jù)對從業(yè)者選擇要使用的模型都是無用的。
正如論文《Open Graph Benchmark: Datasets for Machine Learning on Graphs》中所寫的那樣,許多 GNN 論文基于一些節(jié)點數(shù)為 2000-20,000 的小型圖數(shù)據(jù)集進行實驗(如 Cora、CiteSeer、PubMed)。這些數(shù)據(jù)集無法真正地區(qū)分不同 GNN 方法之間的區(qū)別。
近期的一些研究開始直接解決這一問題,但是為什么研究者這么長時間一直在小型、無用的數(shù)據(jù)集上做實驗?zāi)兀窟@個問題值得討論。
性能和任務(wù)有關(guān)
一個令人震驚的事實是,盡管語言模型在大量 NLP 任務(wù)中達到最優(yōu)性能,但如果你只是把句子嵌入用于下游模型,那么從語言模型嵌入中獲得的性能增益并不比累加 Word2Vec 詞嵌入這類簡單方法要多。
類似地,我發(fā)現(xiàn)對于很多圖而言,簡單的一階方法在圖聚類和節(jié)點標簽預(yù)測任務(wù)中的性能和高階嵌入方法差不多。事實上,高階方法還消耗了大量算力,造成了浪費。
此類一階方法包括 ProNE 和 GGVec(一階)。
高階方法通常在鏈接預(yù)測任務(wù)上有更好的表現(xiàn)。
有趣的是,鏈接預(yù)測任務(wù)中的性能差距對于人工創(chuàng)建的圖而言是不存在的。這表明,高階方法的確能夠?qū)W習(xí)到現(xiàn)實圖的某種內(nèi)在結(jié)構(gòu)。
就可視化而言,一階方法表現(xiàn)更好。高階方法的可視化圖可能會出現(xiàn)偽影,例如 Node2Vec 可視化會有長絲狀的結(jié)構(gòu),它們來自較長單鏈隨機游走的嵌入。高階方法和一階方法的可視化對比情況參見下圖:
最后,有時候簡單的方法能夠打敗高階方法。問題在于我們不知道什么時候一類方法優(yōu)于另一類方法,當然也不知道其原因。
不同類型的圖在被不同方法表示時反應(yīng)有好有壞,這背后當然是有原因的。但這目前仍是個開放性問題。
這其中的一大因素是研究空間充斥了無用的新算法。原因如下:
學(xué)術(shù)動機阻礙進步
憤世嫉俗者認為機器學(xué)習(xí)論文是通過以下方式炮制的:
使用已有的算法;
添加新的層 / 超參數(shù),用數(shù)學(xué)形式描述其重要性;
對超參數(shù)執(zhí)行網(wǎng)格搜索,直到該新方法打敗被模仿的那個基線方法;
絕不對在「實驗結(jié)果」部分中進行對比的方法執(zhí)行網(wǎng)格搜索;
給新方法起個不錯的縮寫名稱,不公布 Python 2 代碼。
我不是唯一一個對當前可復(fù)現(xiàn)研究持此觀點的人。至少近兩年情況好了一點。
所有進展都關(guān)乎實際問題
早在四十多年前,我們就已經(jīng)知道如何訓(xùn)練神經(jīng)網(wǎng)絡(luò)了,但直到 2012 年 AlexNet 出現(xiàn),神經(jīng)網(wǎng)絡(luò)才出現(xiàn)爆炸式發(fā)展。原因在于實現(xiàn)和硬件都發(fā)展到了一個節(jié)點,足以使深度學(xué)習(xí)應(yīng)用于實際問題。
類似地,至少 20 年前,我們就已經(jīng)知道如何將詞共現(xiàn)矩陣轉(zhuǎn)換為詞嵌入。但詞嵌入技術(shù)直到 2013 年 Word2Vec 問世才出現(xiàn)爆發(fā)式發(fā)展。其突破點在于基于 minibatch 的方法允許在商用硬件上訓(xùn)練 Wikipedia 規(guī)模的嵌入模型。
如果只花費數(shù)天或數(shù)周時間在小規(guī)模數(shù)據(jù)上訓(xùn)練模型,那么這個領(lǐng)域的方法很難取得進步。研究者會失去探索新方法的動力。如果你想取得進展,你必須嘗試在商用硬件上以合理時間運行模型。谷歌的初始搜索算法最開始也是在商用硬件上運行的。
效率更重要
深度學(xué)習(xí)研究的爆發(fā)式發(fā)展離不開效率的提升,以及更好的軟件庫和硬件支持。
模型架構(gòu)沒那么重要
今年更加重要的一篇論文是 OpenAI 的《Scaling Laws for Neural Language Models》。這篇文章指出,模型中的原始參數(shù)數(shù)量是對整體性能最具預(yù)測性的特征。最初的 BERT 論文也指出了這一點,并推動了 2020 年大規(guī)模語言模型的迅速增加。
這一現(xiàn)實呼應(yīng)了 Rich Sutton 在《苦澀的教訓(xùn) (https://mp.weixin.qq.com/s/B6rnFLxYe2xe5C5f2fDnmw)》一文中提出的觀點:
利用算力的一般方法最終是最有效的方法。
Transformer 可能也在替代卷積,正如知名 YouTube 博主 Yannic Kilcher 所說,Transformer 正在毀掉一切。它們可以和圖網(wǎng)絡(luò)結(jié)合,這也是最近幾年出現(xiàn)的方法之一,而且在基準測試中表現(xiàn)出色。
研究者似乎在架構(gòu)方面投入了太多精力,但架構(gòu)并沒有那么重要,因為你可以通過堆疊更多層來近似任何東西。
效率的勝利是偉大的,而神經(jīng)網(wǎng)絡(luò)架構(gòu)只是實現(xiàn)這一目標的方式之一。在架構(gòu)方面投入過多的精力,只會使我們錯過其他方面的巨大收益。
當前的圖數(shù)據(jù)結(jié)構(gòu)實現(xiàn)太差勁了
NetworkX 是一個糟糕的庫。我是說,如果你正在處理一些微小的圖,該庫表現(xiàn)還 OK。但如果處理大規(guī)模的圖任務(wù),這個庫會令你抓狂且迫使你重寫所有的東西。
這時,多數(shù)處理大規(guī)模圖任務(wù)的用戶不得不手動滾動一些數(shù)據(jù)結(jié)構(gòu)。這很難,因為你的計算機內(nèi)存是由 1 和 0 組成的一維數(shù)組,并且圖沒有明顯的一維映射。
這種情況在我們更新圖(如添加 / 移除節(jié)點 / 邊緣)時會變得更加困難。以下提供了幾個替代選擇:
分離的指針網(wǎng)絡(luò)
NetworkX 就是最好的示例。每個節(jié)點對象都包含指向其他節(jié)點的指針列表(節(jié)點邊緣),其布局就像鏈表一樣。
鏈表完全違背了現(xiàn)代計算機的設(shè)計方式。它從內(nèi)存中讀取數(shù)據(jù)非常慢,但在內(nèi)存中的運行速度卻很快(快了兩個數(shù)量級)。在這種布局中,無論何時做任何事情,你都需要往返 RAM。這在設(shè)計上就很慢,你可以使用 Ruby、C 或者匯編語言編寫,但還是很慢,這是因為硬件上的內(nèi)存讀取速度就很慢。
這種布局的主要優(yōu)勢在于其添加了新節(jié)點 O(1)。所以如果你在維護一個龐大的圖,并且添加和移除節(jié)點的頻率與從圖中讀取數(shù)據(jù)的頻率相同,則這種布局挺適合的。
另外一個優(yōu)勢是這種布局可以「擴展」。這是因為所有數(shù)據(jù)彼此之間可解耦,所以你可以將這種數(shù)據(jù)結(jié)構(gòu)放置在集群上。但實際上,你正在為自身問題創(chuàng)造一個復(fù)雜的解決方案。
稀疏鄰接矩陣
稀疏鄰接矩陣非常適合只讀(read-only)圖。我在自己的 nodevectors 庫中將它作為后端使用,很多其他的庫編寫者使用 Scipy CSR Matrix。
最流行的布局是 CSR 格式,你可以使用 3 個數(shù)組來保存圖,分別用于邊緣終點、邊緣權(quán)重和「索引指針」,該指針說明邊緣來自哪個節(jié)點。
此外,得益于 CSR 的 3 數(shù)組布局,它可以在單個計算機上進行擴展:CSR 矩陣可以放置在磁盤上,而不用放在內(nèi)存中。你只需要對 3 個數(shù)組執(zhí)行內(nèi)存映射,并在磁盤上使用它們。
隨著現(xiàn)代 NVMe 驅(qū)動器的出現(xiàn),隨機搜索速度不再那么慢了,要比擴展基于鏈表的圖時進行分布式網(wǎng)絡(luò)調(diào)用快得多。但這種表征存在的問題是:添加一個節(jié)點或邊緣意味著重建整個數(shù)據(jù)結(jié)構(gòu)。
Edgelist 表征
這種表征具有 3 個數(shù)組:分別用于邊緣源、邊緣終點和邊緣權(quán)重。DGL 包在其內(nèi)部使用的正是這種表征。其簡單、緊湊的布局非常適合分析使用。
與 CSR 圖相比,該表征的問題在于某些尋軌操作(seek operation)速度較慢。假設(shè)你要找出節(jié)點#4243 的所有邊緣,則如果不維護索引指針數(shù)組,就無法跳轉(zhuǎn)到那里。
因此,你可以保持 sorted order 和二分搜索 (O(log2n)) 或 unsorted order 和線性搜索 (O(n))。
這種數(shù)據(jù)結(jié)構(gòu)也可以在內(nèi)存映射的磁盤陣列上使用,并且在 unsorted 版本上節(jié)點添加速度很快(在 sorted 版本上運行緩慢)。
全局方法是條死胡同
一次性處理整個圖的方法無法利用算力,因為它們達到一定規(guī)模就會把 RAM 耗盡。
因此,任何想要成為新標準的方法都要能對圖的各個部分進行逐個更新。
基于采樣的方法
未來,采樣效率將變得更加重要。
Edgewise 局部方法。我所知道的能做到這一點的算法只有 GloVe 和 GGVec,它們通過一個邊列表,并在每一步上更新嵌入權(quán)重。這種方法的問題在于,它們很難應(yīng)用于更加高階的方法。但其優(yōu)點也很明顯:很容易進行擴展,即使是在一臺計算機上也不例外。此外,逐漸增加新的節(jié)點也很簡單,只需要獲取現(xiàn)有的嵌入,添加一個新節(jié)點,然后在數(shù)據(jù)上執(zhí)行一個新的 epoch。
隨機游走采樣。采用這一方法的包括 deepwalk 及相關(guān)的后續(xù)工作,通常用于嵌入而不是 GNN 方法。這在計算上可能非常昂貴,添加新節(jié)點也很困難。但它是可以擴展的,Instagram 就用它來為自己的推薦系統(tǒng)提供信息。
鄰接采樣。這是目前 GNN 中最普遍的一種采樣方法,低階、高階都適用(取決于 neighborhood 的大小)。它的可擴展性也很好,盡管很難高效執(zhí)行。Pinterest 的推薦算法用的就是這種方法。
結(jié)論
這里有幾個有趣的問題:
圖類型和圖方法之間是什么關(guān)系?
統(tǒng)一的基準測試,如 OGB。
我們把隨機的模型扔給隨機的基準,卻不知道為什么或者什么時候它們表現(xiàn)得更好。
更基礎(chǔ)的研究。我很好奇:其他表示類型(如 Poincarre 嵌入)能否有效地編碼定向關(guān)系?
另一方面,我們不應(yīng)該再專注于添加新的層,并在相同的小型數(shù)據(jù)集上進行測試。沒人在乎這個。
原文標題:有人說別太把圖神經(jīng)網(wǎng)絡(luò)當回事兒
文章出處:【微信公眾號:人工智能與大數(shù)據(jù)技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107771 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136951
原文標題:有人說別太把圖神經(jīng)網(wǎng)絡(luò)當回事兒
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數(shù)據(jù)技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
神經(jīng)網(wǎng)絡(luò)的初步認識

自動駕駛中常提的卷積神經(jīng)網(wǎng)絡(luò)是個啥?

CNN卷積神經(jīng)網(wǎng)絡(luò)設(shè)計原理及在MCU200T上仿真測試
NMSIS神經(jīng)網(wǎng)絡(luò)庫使用介紹
構(gòu)建CNN網(wǎng)絡(luò)模型并優(yōu)化的一般化建議
在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗
CICC2033神經(jīng)網(wǎng)絡(luò)部署相關(guān)操作
液態(tài)神經(jīng)網(wǎng)絡(luò)(LNN):時間連續(xù)性與動態(tài)適應(yīng)性的神經(jīng)網(wǎng)絡(luò)
神經(jīng)網(wǎng)絡(luò)的并行計算與加速技術(shù)
如何在機器視覺中部署深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)

無刷電機小波神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)子位置檢測方法的研究
神經(jīng)網(wǎng)絡(luò)專家系統(tǒng)在電機故障診斷中的應(yīng)用
神經(jīng)網(wǎng)絡(luò)RAS在異步電機轉(zhuǎn)速估計中的仿真研究
基于FPGA搭建神經(jīng)網(wǎng)絡(luò)的步驟解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論