") 在小芯片CPU嘗到甜頭,AMD向Chiplet GPU進(jìn)發(fā)!
在小芯片CPU嘗到甜頭,AMD向Chiplet GPU進(jìn)發(fā)!

電子發(fā)燒友報(bào)道(文/周凱揚(yáng))在HPC應(yīng)用上,對突破性能的追求是從未停歇的,尤其是在人工智能、機(jī)器學(xué)習(xí)和大數(shù)據(jù)分析等新興應(yīng)用提出更高的性能要求后。但制程突破的速度已經(jīng)逐漸放緩,每個(gè)工藝節(jié)點(diǎn)帶來的頻率紅利也在慢慢變小。而為了減少生產(chǎn)和開發(fā)成本,提高良率,不少CPU制造商都開始看向小芯片。
2020年的最后一天,AMD公布了自己在小芯片GPU上的專利,引起了不少熱議。大家都在猜測,小芯片是否能成為后摩爾時(shí)代芯片設(shè)計(jì)創(chuàng)新的利器呢?
AMD:從小芯片CPU走向小芯片GPU
AMD從很早開始就在小芯片上發(fā)力了,不管是EPYC服務(wù)器CPU還是線程撕裂者桌面CPU,都大量運(yùn)用了小芯片設(shè)計(jì)。在AMD看來,傳統(tǒng)的單片處理器將一個(gè)或多個(gè)CPU核心放置在單個(gè)裸片上,以此加速時(shí)鐘頻率和緩存讀取,雖然這種策略對于需要重度CPU使用的工作來說非常合理,但仍有其限制。而小芯片設(shè)計(jì)可以帶來更快的架構(gòu)創(chuàng)新,尤其是在數(shù)據(jù)中心等應(yīng)用上。
在去年的ISSCC 2020上,AMD重點(diǎn)提到了小芯片在第二代EPYC服務(wù)器CPU上帶來的優(yōu)勢。運(yùn)用Zen 2架構(gòu)的EPYC服務(wù)器CPU上,AMD在CPU核心上運(yùn)用了臺積電代工的7nm小芯片,IOD仍然采用Global Foundries的14nm制程。AMD提到這種設(shè)計(jì)實(shí)現(xiàn)了更高的核心數(shù)和更高的性能,而且顯著降低了成本。
而AMD近期公布的小芯片GPU專利同樣掀起了不小的浪花,該專利展示了一種使用高帶寬交聯(lián)的小芯片GPU設(shè)計(jì)方案。
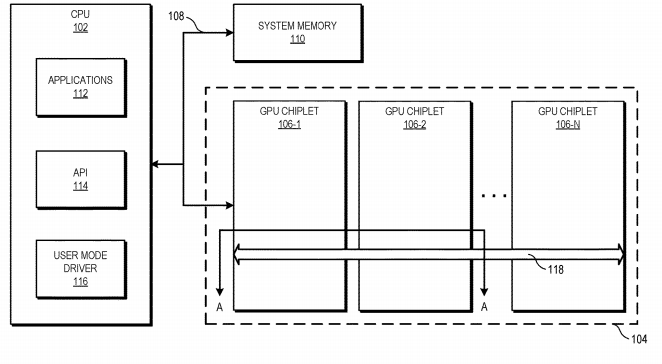
小芯片GPU / AMD
在該專利中,AMD提到,由于多數(shù)應(yīng)用是以單個(gè)GPU為前提寫就的,所以為了保留現(xiàn)有的應(yīng)用編程模型,將小芯片設(shè)計(jì)實(shí)現(xiàn)在GPU上向來都是一大挑戰(zhàn)。而該專利利用一根總線將第一個(gè)GPU小芯片與CPU相連,余下的GPU用被動交聯(lián)連接。
如今許多架構(gòu)至少擁有一級緩存連貫分布在整個(gè)GPU裸片上,比如L3或其他最后一級緩存(LLC)。而這種設(shè)計(jì)中,這些物理資源被放置在不同的裸片上,并提供通信連接以保證其緩存連貫性。在工作過程中,內(nèi)存地址請求從CPU發(fā)往一個(gè)GPU小芯片,后者與高帶寬被動交聯(lián)溝通以定位所需數(shù)據(jù),因此從CPU的角度來看,仍然是在一個(gè)單獨(dú)的GPU上尋址。
Intel:以小芯片打造客戶2.0的芯片
芯片方案演化 / Intel
Intel在去年的架構(gòu)日上給出了他們在IP/SOC上的策略改變,在過去整合的單片SOC中,開發(fā)周期長達(dá)3到4年,而且在投入使用后,制造商和用戶會在芯片上發(fā)現(xiàn)上百個(gè)Bug。而演化至多裸片的基本小芯片結(jié)構(gòu)后,將GPU、CPU和IO放置在不同的裸片上,開發(fā)周期縮減至2-3年,Bug數(shù)目縮減至十?dāng)?shù)個(gè),不僅如此,小芯片設(shè)計(jì)還可以重復(fù)使用。最后則是Intel對未來小芯片結(jié)構(gòu)的展望,將不同的IP放在最優(yōu)制程的小芯片上,比如內(nèi)存、I/O或圖形等,從IP或小芯片層面上來做驗(yàn)證,因此Bug數(shù)目不足十個(gè),開發(fā)周期僅需1年。
客戶2.0方案 / Intel
這樣的設(shè)計(jì)也讓Intel對芯片定位有了更多的自由,比如游戲玩家需要更多的圖形性能,而開發(fā)者則更渴求高算力的和強(qiáng)大的AI性能等。這也就是Intel設(shè)想的客戶2.0愿景,通過智能感知帶給消費(fèi)者無縫的高性能體驗(yàn)。
盡管GPU一直是Intel的弱項(xiàng)之一,但這并不代表Intel沒有在顯示領(lǐng)域上發(fā)力。自從Intel從AMD的圖形部門挖走首席架構(gòu)師Raja Koduri以來,Intel就開始在獨(dú)立顯卡上發(fā)力。Intel于2019年末公布了超算級別的GPU,代號名為Ponte Vecchio,該GPU基于7nm工藝和小芯片技術(shù),將于2021年年內(nèi)安裝在Aurora超級計(jì)算機(jī)上作為圖形加速器使用。
小芯片的后盾:新的互聯(lián)與封裝技術(shù)
如果沒有創(chuàng)新的互聯(lián)與封裝技術(shù),小芯片設(shè)計(jì)同樣是無法立足的。在小芯片的封裝上,Intel已經(jīng)規(guī)劃好了詳細(xì)的封裝路線圖。
處理器封裝路線圖 / Intel
在Kaby Lake G處理器和Agilex FPGA上,Intel已經(jīng)實(shí)現(xiàn)了EMIB這種2.5D的封裝方式。而Intel在Lakefield系列處理器上使用的Foveros 3D封裝技術(shù)則是對EMIB的進(jìn)一步補(bǔ)充,該技術(shù)可將凸起高度進(jìn)一步降低至50-25um,并實(shí)現(xiàn)接近1000 IO/mm2的密度。
Infinity架構(gòu) / AMD
但要想分解后的小芯片也能保持聯(lián)通,這就是互聯(lián)技術(shù)派上用場的地方,比如AMD在Zen架構(gòu)CPU中引入的Infinity Fabric。AMD將Infinity Fabric視為連接各大產(chǎn)品線的基石,通過第三代Infinity框架,AMD得以為CPU與GPU之間提供大帶寬和低延遲的連接、統(tǒng)一的內(nèi)存訪問,提升AMD產(chǎn)品的結(jié)合性能并簡化編程。
小結(jié)
去年的全球硬科技創(chuàng)新大會上,芯動科技、紫光存儲等成立了中國Chiplet產(chǎn)業(yè)聯(lián)盟,推動國內(nèi)的小芯片發(fā)展。芯動科技在2020年推出了國產(chǎn)自主Chiplet標(biāo)準(zhǔn)INNOLINK,讓龐大的數(shù)據(jù)在小芯片之間低延遲傳輸。
INNOLINK解決方案 / 芯動科技
至于AMD的小芯片GPU,其實(shí)如此架構(gòu)可能更有可能用于未來的CDNA數(shù)據(jù)中心GPU,而不是下一代RDNA消費(fèi)級GPU。因?yàn)閷τ谙M(fèi)級GPU來說,很大一部分場景是對延遲極度敏感的游戲應(yīng)用,這正是小芯片GPU必須要先突破的限制,如果小芯片GPU有著SLI和CrossFire一樣大的延遲的話,無疑也會淡出人們的視野。
本文由電子發(fā)燒友網(wǎng)原創(chuàng),未經(jīng)授權(quán)禁止轉(zhuǎn)載。如需轉(zhuǎn)載,請?zhí)砑游?a target="_blank">信號elecfans999。
-
amd
+關(guān)注
關(guān)注
25文章
5684瀏覽量
139979 -
cpu
+關(guān)注
關(guān)注
68文章
11279瀏覽量
225016 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135468
發(fā)布評論請先 登錄
AMD獲Meta千億美元芯片大單,AI芯片市場格局生變

歷史首次!AMD服務(wù)器CPU市占率達(dá)50%
擁抱Chiplet,大芯片的必經(jīng)之路

解析ISL62776:AMD CPU/GPU核心電源的理想之選
AMD 推出銳龍 AI 嵌入式處理器產(chǎn)品組合,為汽車、工業(yè)和物理 AI 領(lǐng)域提供 AI 驅(qū)動的沉浸式體驗(yàn)

AI硬件全景解析:CPU、GPU、NPU、TPU的差異化之路,一文看懂!?

世界第一!云鎵發(fā)布650V/150A增強(qiáng)型GaN芯片,向汽車電子進(jìn)發(fā)

解構(gòu)Chiplet,區(qū)分炒作與現(xiàn)實(shí)

從 CPU 到 GPU,渲染技術(shù)如何重塑游戲、影視與設(shè)計(jì)?
aicube的n卡gpu索引該如何添加?
重磅!AMD將恢復(fù)向中國出口MI308芯片!
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】+NVlink技術(shù)從應(yīng)用到原理
淺談Chiplet與先進(jìn)封裝
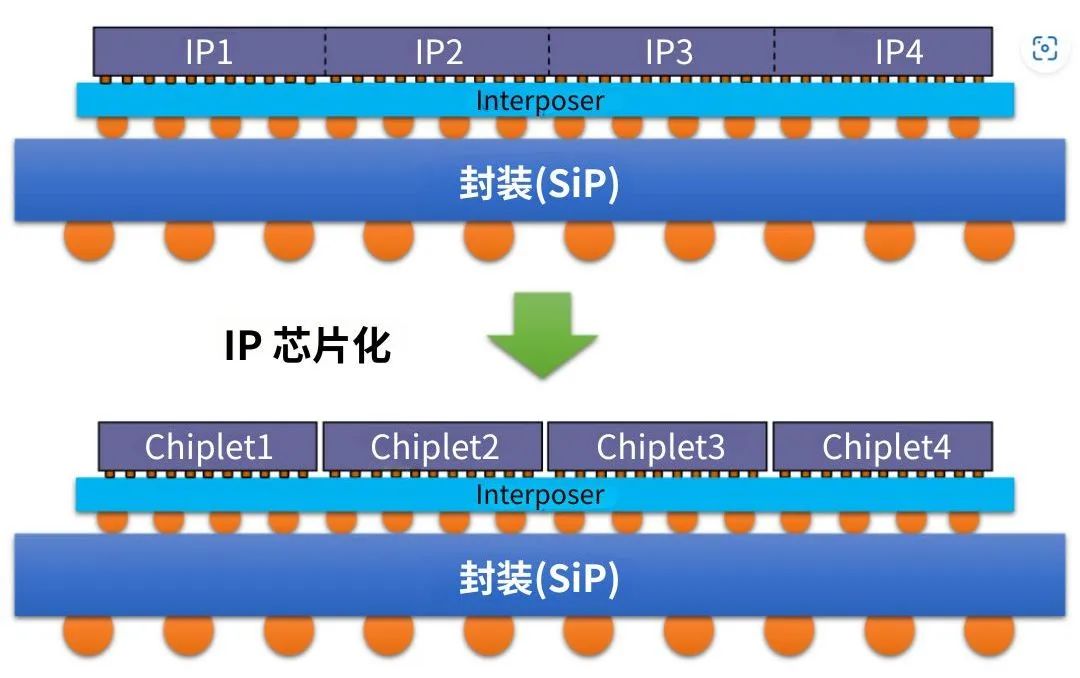
Chiplet技術(shù)的優(yōu)勢和挑戰(zhàn)
Chiplet:芯片良率與可靠性的新保障!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論