 視覺信號輔助的自然語言文法學習
視覺信號輔助的自然語言文法學習

長久以來,自然語言的文法學習(Grammar Learning)只考慮純文本輸入數據。我們試圖探究視覺信號(Visual Groundings),比如圖像,對自然語言文法學習是否有幫助。為此,我們提出了視覺信號輔助下的概率文法的通用學習框架。 該框架依賴于概率文法模型(Probabilistic Context-Free Grammars),具有端到端學習、完全可微的優點。其次,針對視覺輔助學習中視覺信號不足的問題。我們提出在語言模型(Language Modeling)上對概率文法模型進行額外優化。我們通過實驗驗證視覺信號以及語言模型的優化目標有助于概率文法學習。 論文一作趙彥鵬:愛丁堡大學語言、認知和計算研究所博士生,導師是Ivan Titov和Mirella Lapata教授。他的研究興趣是結構預測和隱變量模型。現在主要關注語言結構和圖像結構的學習,以及二者之間的聯系。 1
背景
本次分享內容是,用視覺信號來輔助概率文法學習的一個通用學習框架。我們關注的問題是,視覺信號能否幫助我們來推理出自然語言的句法結構? 接下來我將從以下幾個部分展開。 首先介紹視覺信號輔助下的概率文法學習的一些背景知識和現有的一些工作。 然后介紹本文提出的Visually Grounded Compound PCFGs (VC-PCFGs)。 最后實驗驗證VC-PCFGs的有效性。 論文:《Visually Grounded Compound PCFGs》
首先了解問題定義:給定一張圖片以及它的自然語言描述,比如這里有一張鴿子的圖片,它的語言描述是a white pigeon sniffs flowers,我們的目標是通過圖片和文字兩個輸入,得到對應句子的句法結構,也就是右邊的圖。句法結構由不同的詞組嵌套而成,每個詞組可能有不同的類型,它可以是一個名詞詞組或者是一個動詞的組。在學習過程中,這種詞組的類別信息依賴于文法模型的選擇,但是評測的時候一般會忽略。 為什么視覺信號可以幫助文法結構的學習?這依賴于如下觀測:給定一個句子,如果相鄰的兩個詞組,比如white和pigeon,對應/關聯于圖片中一個相同的區域,那么就有理由相信它們更有可能形成一個大的詞組,進而把它們合并起來。接下來的問題是如何表示這種相關性信息?我們的想法是通過相似度來量化相關性。
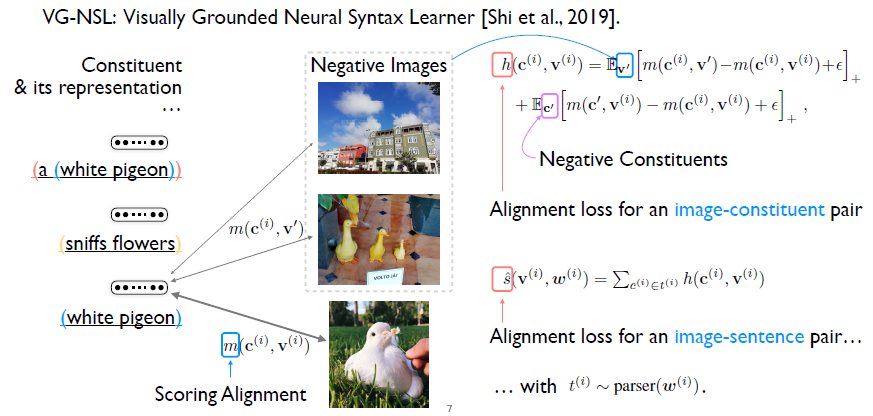
如何去學習相似度?之前的模型應用對比學習的方式(Contrastive Learning)。首先給定一張圖片以及句子,然后通過文法模型,得到句子的句法結構的表示。剛才已經提到句法結構對應的就是一些嵌套的詞組,我們可以把這些詞組提取出來,和相應的圖片組成詞組圖片對,稱之為正樣本。 然后固定一個詞組,從數據集里面隨機采樣一些圖片。并將采樣得到的圖片和當前固定的詞組同樣組成新的詞組圖片對,作為負樣本。對比學習的優化目標就是使正樣本的得分比負樣本的得分高。類似的,我們也可以固定圖片,從其他句子里面隨機的采樣一些詞組,和當前圖片組合構成負樣本。這樣就完整定義了一個詞組圖片對的損失函數。 因為一個句子可以包含多個不同的詞組,那么在所有的詞組圖片對上加和,就可以得到一個句子圖片對的損失函數。需要注意的是這里提到的這些詞組是來自于一個句法結構,這個句法結構是從一個文法模型里面采樣得到的。 我們已經能夠表示和學習這種相似度,接下來如何從相似度學習文法模型?
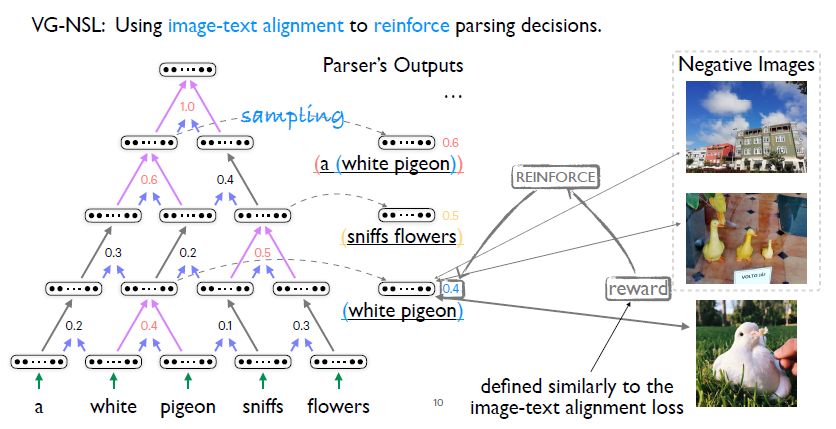
首先了解一下之前的工作,其選擇了一個貪心文法模型。所謂貪心就是每次它只會選擇最有可能合并到一起的兩個詞組,進行合并。其次,貪心意味著它只能去采樣,不能夠在有限時間內枚舉所有可能的句法結構,所以它學習就依賴于強化學習的方法。直觀理解是,如果當前合并起來的兩個詞組和給定的圖像相似度很高,那么有理由相信它們更有可能被合并。我們應用之前定義的詞組圖片對之間的相似度,作為一個reward,強化合并操作。 雖然這樣一個模型比較直觀,但是還有下列這些缺陷,首先強化學習依賴于采樣,所以在優化過程中,即評估梯度的時候會有很大的噪聲。
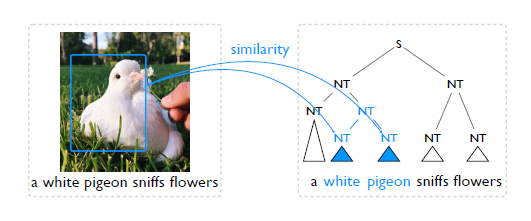
其次對于視覺信號輔助下的自然語言文法學習,有一個本質的問題,即有些句法結構的信息在相應的圖片里面是找不到支撐信息的。比如這里稍微改變一下這個句子, a white pigeon is sitting in the grass peacefully。我們很難去找到sitting這樣一個動詞以及peacefully這樣一個副詞在這個圖片里面所對應的視覺信號是什么。觀察之前的文章作者匯報的一些結果,我們發現他們的模型在名詞詞組,即NPs,相對于在動詞VPs上的結果要好很多。為了緩解這個問題,他們不得不借助于語言特定的先驗信息。 2
我們的模型:VC-PCFGs
那么我們是如何解決這些問題的呢?首先,對于強化學習帶來的梯度評估中的噪聲問題。我們提出把貪心文法模型替換為概率文法模型,即PCFGs。替換之后我們可以將采樣操作去掉,同時優化過程是完全可微的。我們稱之為,Visually Grounded Compound PCFGs。至于compound這個名詞的解釋稍后會提到。 其次是視覺信號不充分的問題。對于一個概率文法模型,只給定純文本,而沒有視覺信號的情況下,我們可以通過優化語言模型的目標函數來學習概率文法模型,所以我們提出在語言模型目標函數上對概率文法模型進行優化。 也就是說我們的模型包含兩部分,首先是引入視覺信號的概率文法模型的學習,其次在語言模型目標上來優化概率文法模型。值得注意的是,這兩個過程都是完全可微的。接下來我們詳述這兩部分。

首先回顧視覺信號輔助的文法模型學習中的一個重要的損失函數,在之前的工作中,給定一個文法模型,即parser,采樣得到一個句法結構,通過枚舉這個句法結構所定義的所有詞組,之后在詞組圖片對上把它們的loss加和,得到一個句子圖片對上的loss。我們的目標是把這樣一個采樣過程去掉,也就意味著必須想辦法計算句法結構分布下的損失函數的期望值。

期望可以寫成加和的形式。給定一個句子的話,這個句法結構空間是指數級別的,我們不可能枚舉所有句法結構。但是我們可以把這個式子中的兩個加法操作交換順序。第一個加法操作是枚舉所有的句法結構,第二個加法是要枚舉句法結構中所有的詞組。交換順序之后做一些簡單的推導,就可以得到最右邊的等式。這個等式意味著只需要枚舉給定句子的所有的詞組,這是很容易做到的,因為其所有的詞組數目也就N平方級別。 接下來問題轉換成如何來評估條件概率?即給定一個句子,其中一個詞組的條件概率是什么?這就是通常所說的后驗評估的問題。其次,還需要得到這個詞組Span c的表示。我們需要用它和圖像做一個相似度的計算。最終的問題可以劃分成兩個部分:后驗評估和Span的表示。
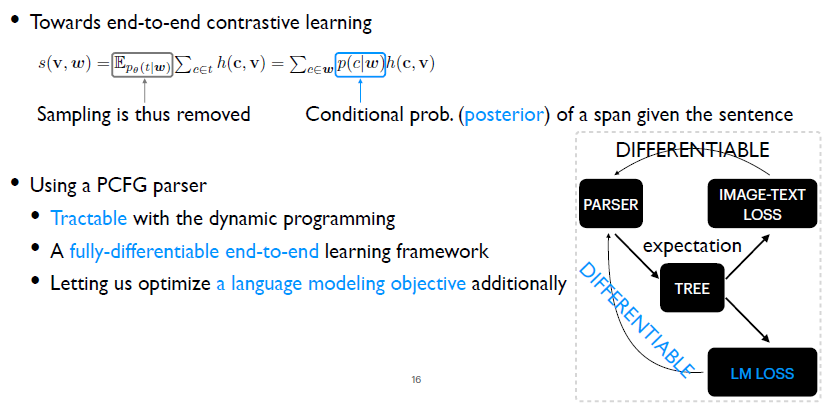
首先第一個部分,后驗評估。我們選擇了一個概率文法模型,PCFG parser。因為用這樣一個概率文法模型的話,可以通過動態規劃的方法方便地計算后驗概率。然后通過計算句法樹分布下的損失函數期望值,得到去除采樣過程的損失函數。同時它的優化是完全可微的。其次,因為概率文法模型的優化本身可以不依賴于視覺信號,所以我們可以直接去優化它的語言模型上的目標函數,這個過程同樣是完全可微的,同時緩解了視覺信號不充分的問題。 對于概率文法模型,我們選擇了當前最好的一個概論文法模型,即Compound PCFGs。需要指出的就是Compound PCFGs只是PCFGs的一個擴展,所以之前提到的關于PCFGs的所有的優點它都是具備的。這樣便得到我們的完整模型,即Visually Grounded Compound PCFGs。

接下來來看第二個模塊。第二個模塊是給定一個句子如何來表示它的詞組。我們這里選擇了雙向的LSTM模型。對于一個句子中所有不同長度的詞組,我們在詞組級別上做編碼,得到詞組的向量化表示。這樣一個模型能夠保證當前詞組的表示,不會用到詞組之外的信息。通過一些代碼實現上的技巧,我們可以在線性時間復雜度內得到所有詞組的表示。 3
結論驗證
最后是實驗部分。

實驗部分使用了MSCOCO數據集,每個圖片對應有一個自然語言的描述。由于數據集中的自然語言描述沒有真實的句法結構標注,為了評測,我們使用了當前最好的一個有監督的文法模型,得到自然語言描述的句法結構。對于圖像的編碼,我們沿用之前工作的方法,對每個模型用預練好的,ResNet-101,把每個圖片編碼成一個向量的表示。
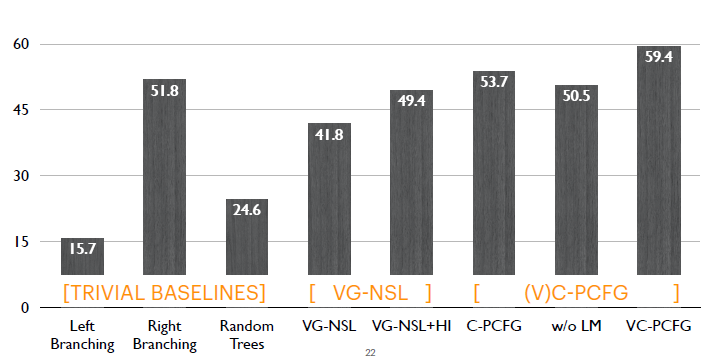
評測中,我們在每一種設置下重復運行模型4次并取平均,每次使用了不同的隨機數種子。評測指標使用句子級別的F1評測。模型之間的對比,這里主要有三組模型: 1.第一組是很簡單的對比模型,比如Left Branching, Right Branching, Random Trees。 2.第二組是之前模型,即VG-NSL,我們對比它在使用和不使用語言特定先驗下的結果。 3.第三組是我們的模型,因為這里主要評測兩個模塊: a)僅應用語言模型的目標函數,對應Compound PCFGs(C-PCFGs)。 b)只應用視覺信號,也就第二個without language mode objective(w/o LM)。 最后是我們完整的模型VC-PCFG,既用語言模型的目標函數,又用視覺信號信息。
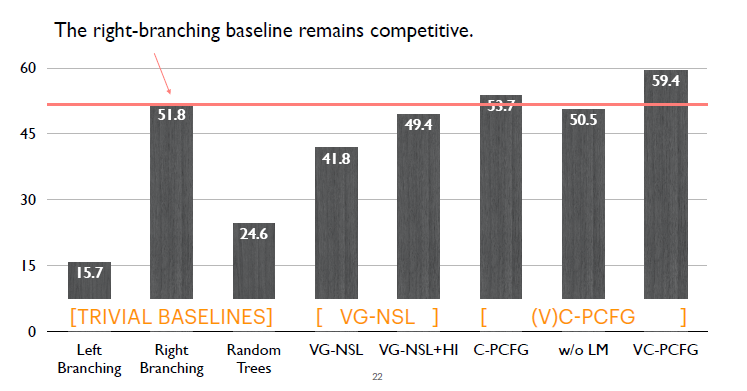
接下來看一下整體結果。首先是Right-branching模型表現強勢,只有Compound PCFG以及VC-PCFG,遠遠的超過了它,其他模型都比這個簡單的模型表現要差。
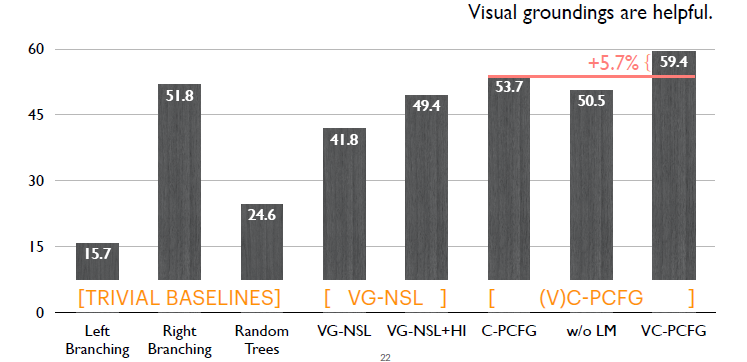
這里對比C-PCFG和VC-PCFG。模型如果額外使用視覺信號的話,可以帶來接近6%的提升。
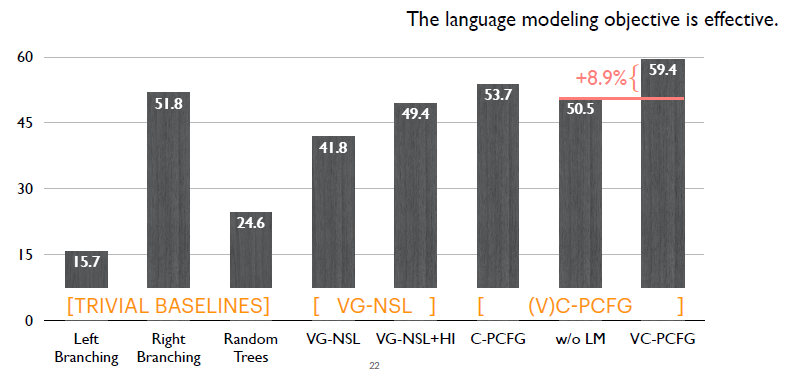
這里對比只使用視覺信號的模型(w/o LM)與加入語言模型目標函數的完整模型(VC-PCFG),我們可以看出語言模型目標函數帶來將近9%的一個提升。
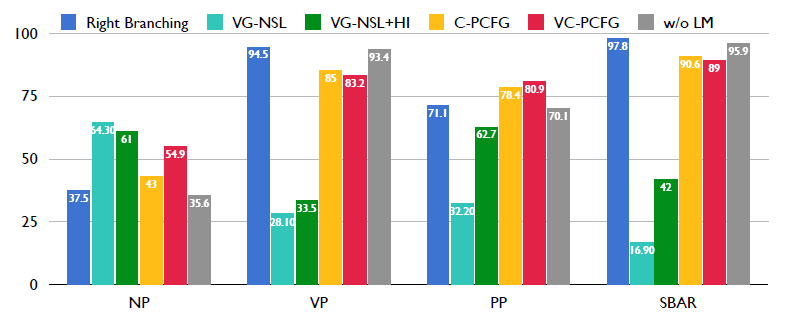
我們想知道這些模型提升主要來自于哪一種類型的詞組?我們這里選擇了測試集里面四個頻率比較高的詞組類型。首先第一個是名詞詞組,然后第二個是動詞詞組,第三個是介詞詞組,第四個是連詞詞組。因為模型在介詞和連詞上的性能和在動詞詞組上的性能比較類似,接下來我們只在名詞詞組和動詞詞組上做比較。
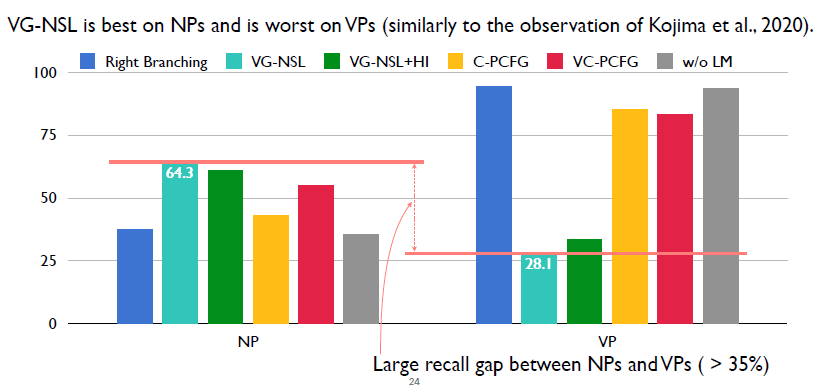
首先先看一下之前的模型VG-NSL,這里重新驗證了作者的實驗結果。VG-NSL在NP上的性能超過VP上的性能大于35%。
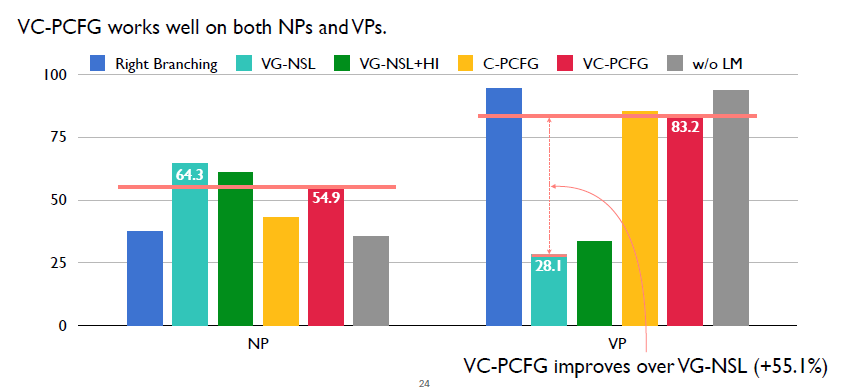
這里顯示的是我們的完整模型,VC-PCFG對應的是紅色柱狀圖。可以看出相對于其他模型,它的效果雖然不是最好的,但是它整體來說是較好的。然后在VP上,相對于之前的VG-NSL,我們的模型比它高出了55%。
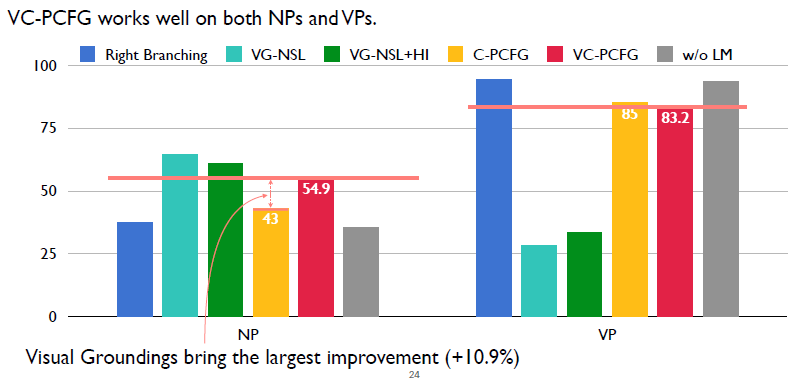
接下來驗證視覺信號的有效性。沒有用視覺信號的是黃色柱狀圖,使用了視覺信號的是紅色柱狀圖。在NP上,使用視覺信號可以帶來將近11%的一個提升,也就是說視覺信號對NP是有幫助的。
這里驗證語言模型的目標函數的有效性。同樣我們發現語言模型目標函數也是在NP上帶來一個很大的提升,提升了大概19%。
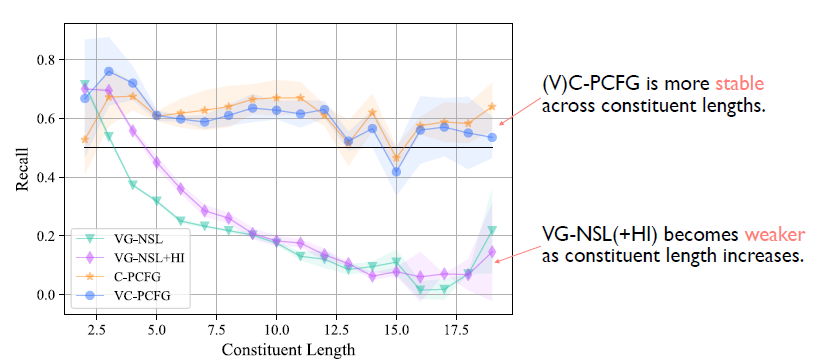
最后我們從另外一個角度來分析模型。即這些模型在不同長度的詞組上的效果如何。這張圖首先可以看有一個明顯的差別:上面兩個對應的是C-PCFG以及VC-PCFG,這兩個模型明顯是要優于之前的VG-NSL。 具體來說的話,當詞組的長度大于4的時候,這兩個模型始終是優于之前的VG-NSL,即便之前的VG-NSL加了一個語言特定的先驗知識。
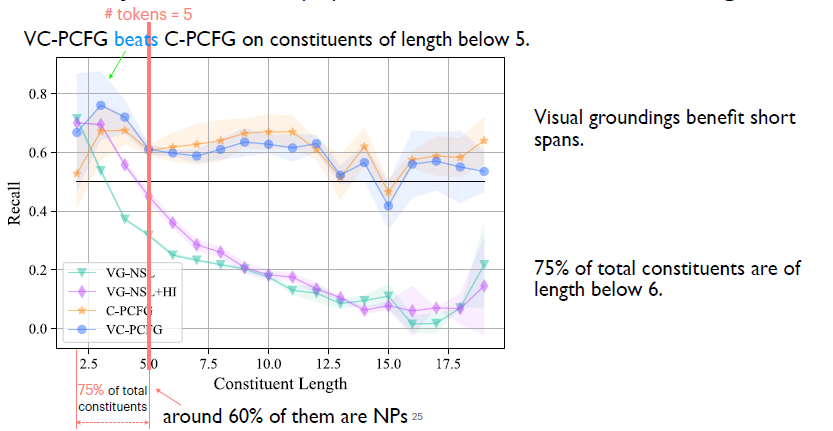
這里對比視覺信號是否有幫助。藍色是是我們完整的模型,橙色的是沒有加入視覺信號的模型。我們發現當詞組的長度小于5的時候,藍色對應的模型,即使用了視覺信號模型是要顯著優于不用視覺信號的模型,所以我們結論是視覺信號對于短的一些詞組是有幫助的。然而我們發現這些短詞組占了整個數據集所有詞組大概75%,而在75%里面又有60%是名詞詞組,所以我們可以說視覺信號對于文法學習的幫助主要體現在名詞詞組上。 4
結論
我們提出了VC-PCFGs。它應用Compound-PCFGs作為文法模型,是一個端到端可微,在視覺信號輔助下的文法學習通用框架。 VC-PCFGs允許我們額外優化一個語言模型的目標函數,進而緩解視覺信號不充分的問題。 我們實驗驗證了視覺信號以及語言模型的優化目標函數對于文法學習都有幫助。
原文標題:EMNLP 2020最佳論文榮譽提名:視覺信號輔助的自然語言文法學習
文章出處:【微信公眾號:通信信號處理研究所】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
信號
+關注
關注
12文章
2914瀏覽量
80122 -
自然語言
+關注
關注
1文章
292瀏覽量
13986
原文標題:EMNLP 2020最佳論文榮譽提名:視覺信號輔助的自然語言文法學習
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
面向視覺語言導航的任務驅動式地圖學習框架MapDream介紹

自然語言處理NLP的概念和工作原理

云知聲論文入選自然語言處理頂會EMNLP 2025

HarmonyOSAI編程自然語言代碼生成
【HZ-T536開發板免費體驗】5- 無需死記 Linux 命令!用 CangjieMagic 在 HZ-T536 開發板上搭建 MCP 服務器,自然語言輕松控板
milvus向量數據庫的主要特性和應用場景
DevEco CodeGenie 鴻蒙AI 輔助編程初次使用
思必馳與上海交大聯合實驗室兩篇論文入選ICML 2025
人工智能浪潮下,制造企業如何借力DeepSeek實現數字化轉型?
云知聲四篇論文入選自然語言處理頂會ACL 2025

小白學大模型:從零實現 LLM語言模型

自然語言提示原型在英特爾Vision大會上首次亮相
拒絕“人工智障”!VLM讓RDK X5機器狗真正聽懂“遛彎”和“避障

?VLM(視覺語言模型)?詳細解析

數據采集在AI行業的應用、優勢及未來發展趨勢




 工商網監
工商網監
評論