 電子發燒友App
電子發燒友App



大數據時代,數據量呈幾何增長,為避免被時代潮流“拍在沙灘上”,就必須了解大數據的核心組成要素。其中,海量日志尤為重要,不管是IT達人還是企業本身,掌握海量日志的分析技術都必不可少。
今天,就讓小愛帶你探秘海量日志分析技術,一起來看吧。
一.為什么海量日志很重要?
在討論海量日志分析技術之前,我們先來討論一下什么是海量日志。
海量日志是大數據的重要組成部分。數據倉庫之父比爾.恩門(Bill Inmon) 在他的2016年的新書《數據架構》中提到,企業中數據的組成部分中,非結構化的數據占比已經達到了 70% 以上。而這些非結構化數據中,占據主導位置的是日志數據,可以說日志數據是“大數據”分析的核心。
這些數據貫穿所有的企業經營活動,用戶的操作行為、服務器的系統日志、網絡設備的日志記錄、應用程序的調試日志等等,會直接影響企業的日常運行,與IT運維人員也是息息相關。
二.海量日志數據有什么特征?
海量的日志數據十分滿足大數據的4V特征:
1. 產生速度快,每秒超過數萬、數十萬的情況已經比比皆是
2. 數據量巨大,速度一快,如果想要分析這數據,勢必會帶來巨大的數據量
3. 數據種類多,日志數據涵蓋IT系統的方方面面
4. 價值密度低,雖然日志數據中能夠分析出大量有價值的信息,往往一條分析結果需要數百萬甚至上億條的數據支撐,而且單條日志的信息量有限

日志樣例
我們可以通過一組數據來感受一下海量日志的威力。假設有一個對外應用服務器集群,產生日志的速度為10000條/s,每條日志的平均大小為200字節,那么這個應用服務器每天、每月、每年的日志增量為:

三.大數據條件下計算方式的變革
從行式存儲到列式存儲,再到流式計算
這么多的數據,我們如何來進行分析呢?一方面我們需要能夠處理更多的數據,另一方面,我們希望查詢結果更加的實時(例如:1秒之內返回結果)。
如果這些數據在關系型數據庫的世界里,數據以行的方式存儲,假設我們需要對數以億計的數據中的某一個數據進行求和計算,那么首先,我們需要將所有這些數據全部讀出來,找到對應的字段,然后進行累加,而我們的計算瓶頸完全取決于磁盤的讀寫能力。
我們可以用分庫或者分表的方式將數據庫進行拆分,增加系統并行計算的能力,但是可能依然需要數百臺設備才能在1s之內返回這些數據。然而我們沒有這么多機器,那么只能慢慢等待分析任務執行完畢。如此一來,既耗時又費力。
后來,大數據技術誕生了。在大數據分析的場景中,列式存儲架構取代了行式存儲。如果要對某一個字段進行統計,只需要讀取相應列的數據,不需要進行整個表的遍歷,這樣一來,需要讀取的數據量變小了,同時,MapReduce 也能夠使得分析應用更好地實現分布式計算。
可即便如此,計算的瓶頸依然在磁盤的讀寫效率上,計算速度并沒有本質的變化,如果需要做實時數據的分析,還是需要大投入大量的存儲和計算資源。

行式數據庫vs列式數據庫
從邏輯上來說,如果要對海量的數據進行快速的分析,在資源不變的前提下,最好的方法就是減少每次計算所需要讀取的數據量。但是如果減少了數據量的讀取,分析的結果就無法做到更大的覆蓋范圍和更加精準的結果。
基于這個思考,我們可以將計算分層,將最近一段時間產生的數據放在實時要求高的數據存儲中,使用更好的計算資源來進行分析,將更長時間的歷史數據存入離線存儲設備中進行批量計算,這部分計算時間可能長達數十分鐘或者數個小時,但是計算的結果可以用于和實時分析的結果進行合并,使得分析的覆蓋范圍和結果的精準度不受影響。
在大數據分析技術中,還有一項非常重要的技術 —— 流式計算,即數據進入系統時就進行必要的預處理操作,這部分的處理,同樣減少了后續數據分析中所需要讀取的數據量。
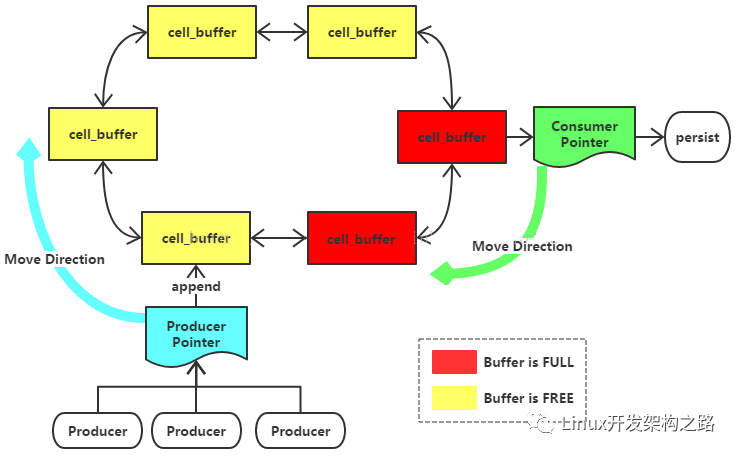
海量日志分析技術數據流程圖
四.海量日志分析技術
愛數 AnyRobot Family 3.0(下面簡稱 AnyRobot) 海量日志分析融入了大數據分析技術,其核心要點在于三個重要方面:海量日志的采集處理、海量日志的存儲、海量日志的分析。下面,我們就以AnyRobot為例剖析海量日志分析技術。
1.海量日志的采集處理方面
有兩個核心點,分別是數據采集的多樣性和實時數據處理的性能。
在采集數據源的多樣性方面,AnyRobot 可以對接文件、TCP二進制數據量、壓縮文件、結構化數據、Syslog、SNMP 等多種數據源,我們還內置了大量的分析模板,支持市面上多種網絡設備、數據庫、應用軟件、中間件等各類應用,可以實現大部分場景數據的“開箱即用”。當然,數據源的接入也可以通過界面配置的方式快速完成。在實時處理方面,AnyRobot 采用了可擴展的消息隊列和流計算引擎,保證了實時處理的性能,能夠自如地應對數萬甚至數十萬每秒的數據流量。
2.海量日志的存儲方面
我們采用存儲分層的策略對數據進行分層,根據我們上文中探討的分析思路,應該盡量減少用戶在實時分析場景下使用的數據量,我們將分析數據的存儲分為三個層次:
第一層:用于實時分析和查詢的數據,這部分數據有兩個來源。第一部分是短期內進入系統中的數據,這部分數據保留的大量的細節信息,可以用戶排錯、細粒度的管理分析、事件分析等場景。第二部分是歷史數據經過離線批量計算產生的分析結果,這部分數據的細節已經被隱藏起來,主要用戶統計分析和報表場景。這一部分的數據由于實時性要求高,也有高可用的要求,因此數據的量多于進入系統的數據量,存儲方式可以采用更高性能的 SSD 存儲。
第二層:用戶存儲離線分析的數據,這部分數據是對第一層數據的長期保存和離線分析,這部分數據可以存儲在成本更低的對象存儲或者云存儲中,能夠滿足小時級別的數據分析和訪問需求,需要進行實時分析和日志追溯時,可以重新導入到實時分析存儲中去。這部分數據可以通過壓縮的方式進行存儲,由于日志文件的特性,壓縮比最高能夠達到原始數據1:5以上。
第三層:歸檔存儲,由于合規性的要求和日志長期保存的需求,可以將更長時間的日志數據通過備份的方式進行歸檔,采用愛數的 AnyBackup 就能夠完成這一工作。這部分數據不需要再實時或者離線分析中進行查看,對它們的歷史分析結果已經合并到和上兩層的分析當中。這部分數據采用 AnyBackup 自帶的壓縮和重復數據刪除功能,能夠獲得 95% 以上重復數據刪除率
數據分層存儲
3.海量日志的分析方面
AnyRobot 實現了一個基于 SPL(搜索處理語言)的搜索引擎,采用分布式計算的方式對數據進行分析和計算,在實時分析方面能夠快速的在數億級別數據量的情況下進行實時分析,同時能夠兼容 Hadoop、Spark 等離線分析引擎,并能連接外部數據源,將實時分析、離線分析結果和外部數據源的查詢結果合并后呈現給最終用戶。
在新版本的 AnyRobot 中也集成了機器學習能力,能夠實現異常檢測、趨勢分析等應用,滿足更多使用場景的覆蓋。
五.結語
日志是大數據的重要組成,為了滿足海量日志分析的需要,我們需要從海量日志處理、存儲和分析三個方面來設計我們的日志分析系統。愛數 AnyRobot Family 3.0 通過加入消息隊列、流式處理、存儲分層、離線分析、機器學習等特性,是的海量日志分析的的效率和用戶體驗都得到了大幅的提升。
















 工商網監
工商網監
評論