 電子發燒友App
電子發燒友App



真正的革命并不在于分析數據的機器,而在于數據本身和我們如何運用數據。
——《大數據時代》維克托·邁爾 - 舍恩伯格
二十年,是一個什么概念?
對于大數據領域來說,過去二十年經歷了從新興到炒作巔峰再到實質生產高峰期的過程,并開啟了一次重大的時代轉型。被業界廣泛認可的“大數據”定義由著名咨詢公司 Gartner 的高級分析師道格拉斯·蘭尼 (Douglas Laney)在 2001 年提出;大數據經典框架 Hadoop 則誕生于 2006 年;如今,大數據技術已經從 Hadoop 推動的第一代向更智能、更實時、面向交互的技術方向轉變。
而數據挖掘的歷史比大數據要長得多,在數據量還遠遠沒有今天如此龐大的時候,人們就已經想方設法從中挖掘價值。對索信達首席科學家張磊博士來說,過去二十年是見證數據挖掘和分析技術與應用高速發展的二十年。
張磊從讀研開始進入數據挖掘和分析領域,博士畢業后一直在提供企業級大數據解決方案的知名廠商工作,從 Teradata 到 IBM、SAS,他參與了橫跨運營商到金融行業的數十個項目,有著豐富的從業經歷。今年年初,張磊選擇加入專注金融數字化服務的索信達,擔任首席科學家,希望推動國內金融大數據行業朝著“擁抱開源、自主可控、信息融合、智能化”的方向前行。經過大量項目實踐的磨練,他對于 To B 大數據業務和技術方案有哪些經驗和獨到的思考?他怎樣看待金融大數據的過去和未來?做企業級大數據面臨哪些難點和挑戰?大數據人才團隊該如何搭建?帶著這些問題,InfoQ 對張磊博士進行了獨家專訪,一探這位 20 年資深數據人對 To B 大數據的思考。
數據分析的變與不變
翻看張磊的履歷,可以看到他接近一半的人生都在跟數據打交道。唯有一段,本科畢業后在中科院等離子體物理研究所擔任研究實習員的經歷看似與數據無關。其實,正是這段經歷讓張磊有了跟數據挖掘的“第一次親密接觸”,這比他接觸到數據挖掘這個專業術語還早了四年。
1993 年大學畢業后,張磊去了中國科學院等離子體物理研究所,在理論室工作,工作內容是數值計算,也就是協助理論室的老師們完成計算機上的各種數值分析和模擬工作。當時研究室的朱思錚老師找到他,希望能用神經網絡來建模分析托卡馬克裝置中等離子體的位置和形狀,于是張磊就一頭扎進了 BP 神經網絡算法之中。他清晰地記得,當時在圖書館里唯一能找到的一本教科書是焦李成老師編寫的《神經網絡系統理論》,在這本書的幫助下,他理解了 BPNN 算法,實現了 C 語言編寫的程序,還嘗試解決了 BPNN 算法中的一些問題(陷入局部最優、隱層神經元數量等),最終和朱思錚老師一起把研究結果寫了篇文章發表在 1996 年的《計算物理》雜志上。
1997 年讀研的時候,張磊選擇了數據挖掘方向,后來又在中科院計算技術研究所攻讀數據挖掘與信息檢索方向的工學博士,師從國內數據庫權威王珊教授和杜小勇教授。
從初次“觸電”到現在,二十多年過去了,幸運的是,對張磊而言數據挖掘一直是件很有意思的事情。其中 1999~2002 年的讀博時期和之后在外企工作的十多年對他尤為重要:前者讓他更體系化、更有針對性地博覽數據挖掘領域的科研成果,后者則讓他在大量項目實踐中不斷去驗證和思考什么才是真正合理有效的挖掘方式。
數據挖掘的本質即從數據里找規律,張磊認為這個本質從未改變,改變的是找規律的方法。
回顧數據分析的發展史,從十九世紀下半葉高爾頓、皮爾森開創描述統計學,到 1956 年人工智能和機器學習的誕生與發展,再到 2006 年深度學習的異軍突起,人們一直在嘗試各種方法努力從數據中發現隱藏的規律。而近些年計算能力的飛速提升和大數據的崛起,推動數據挖掘方法和分析算法不斷進化。
以業界常用的一些算法來說,二十年前傳統簡單的 BP 神經網絡似乎已經走到盡頭開始沒落,二十年后 AlexNet、VGG16、Inception、RNN、LSTM、GAN 等深層神經網絡模型層出不窮讓人眼花繚亂;二十年前業界還在為決策樹在行業應用中的簡潔有效而歡欣鼓舞,二十年后隨機森林、GBDT、XGBoost、LightGBM 已經實現了全面超越;二十年前大家還在使用向量空間模型、樸素貝葉斯、SVM 來分析文本,二十年后 BERT、XLNet 已經大行其道。
雖然數據、算力、算法三個因素對于人工智能新一輪浪潮的推動同樣功不可沒,但張磊認為,以深層神經網絡為代表的深度學習算法并未超越傳統神經網絡的基本框架,算法的發展還是落后于數據發展的速度,當然終究還是會水到渠成實現同步。
金融大數據演進的四個階段
每一朵浪花,都有可能變成泡沫,也有可能形成大潮,大數據屬于后者。經過二十年的演進,大數據已經脫離技術炒作巔峰,進入實質生產的高峰期,并進一步成為其他技術(如人工智能)的底層支撐。
據工信部、賽迪網等相關數據,2020 年國內大數據市場總體預計達到萬億元規模,硬件、軟件和服務是其中的三大部分,而對分析人才和分析服務的需求最為迫切。
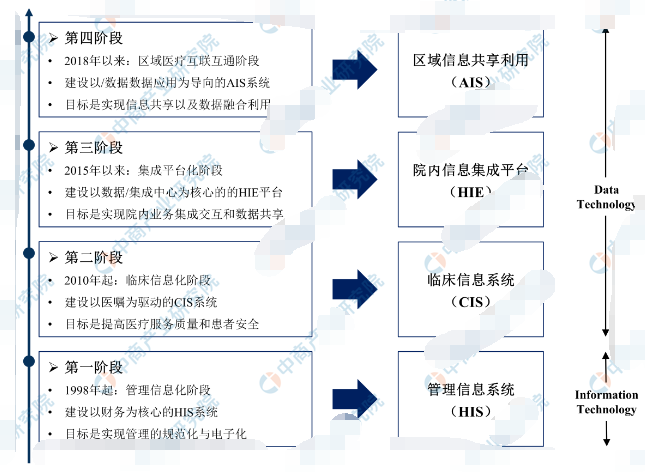
除了互聯網行業,金融業可以說是跟進和采用大數據、人工智能等前沿技術最快的行業。無論是國外還是國內,金融行業的數據分析成熟度都位居前列。從銀行、保險到證券業,大數據平臺已經成為企業越來越倚重的系統,數據中臺的呼聲讓它不斷拉近與核心系統的距離。從數據大集中、數據倉庫、云平臺、數據湖,到商業智能、數據挖掘、人工智能,再到個人金融、公司金融、風險部、客服中心,大數據的架構、技術和應用已經逐步在金融業特別是銀行得到普及。
對于過去十年金融業大數據的發展和演進,張磊認為可以借鑒托馬斯·H·達文波特教授對數據分析成熟度的劃分方式將其劃分為四個階段,他用自己的話對其做了翻譯,分別是星星之火(Localized Analytics)、開始燎原(Analytics Aspirations)、江山一統(Analytic Companies)、傲視群雄(Analytic Competitors)。這四個階段形象地展示了企業或行業在數據分析應用上的發展階段,從早期少量人員開始使用數據分析的星星之火,到部門級搭建一些分析系統,再到整個企業形成全面統一的分析體系,最終的目標是將分析作為核心競爭力的傲視群雄。而目前國內的金融企業大多處于第二階段向第三階段轉變的 2.5 階段。
To B 大數據的經驗和思考
在很多人看來,To B 大數據都是臟活苦活累活,入行以來與眾多金融企業、銀行打過交道的張磊卻有不同看法。
從技術視角出發,張磊覺得 To B 的大數據分析其實比 To C 的好做。首先數據量要小得多,不會因為性能壓力而放棄必要的分析嘗試;另外,數據質量也比較可控,很少會懷疑數據的來源是否可信,這些都讓 To B 的大數據分析相對簡單。在他看來,做 To B 大數據最大的障礙還是在企業文化形成的壁壘上,有些企業多年來已經養成了依賴人的經驗而不相信數據的習慣,部分崗位人浮于事提不出對企業真正有價值的業務問題,這些都會給數據分析項目蒙上陰影。
正處于新時代的轉型中場,金融業數據分析難免遇到新問題,比如引入了更多外部數據不知道怎么利用,看到互聯網企業的業務創新卻不知道如何應對。To B 大數據到底該如何做?基于在大量數據分析項目中的實踐,張磊分享了一些自己的經驗與思考。
數據應用方法論
沒有方法論就像“盲人騎瞎馬,夜半臨深池”,越努力反而結果越差,因為可能走在與目標相反的方向而不自知。
金融業經過最近二十年在數據應用上的豐富實踐,已經形成了很成熟的大數據應用方法論,無論是系統架構、應用框架,還是分析平臺和團隊建設等方面,都有成熟的體系化經驗可供借鑒。張磊將其總結為如下幾條:
堅定的心:時刻堅持業務導向,業務目標永遠是大數據應用的終極方向;
融入血液:形成“從數據中挖掘價值,數據驅動業務”的企業文化,只有從管理層到一線員工形成數據價值的統一認知,才能真正把數據用起來;
鍛煉肌肉:通過培訓競賽知識分享,提升員工的數據分析能力,只有為分析人員賦能之后,才可以利用數據為企業賦能;
數據質量:一方面要強化數據質量管理,好的數據才能分析出有用的結論;另一方面要對企業的數據有信心,有人總擔心自己的數據太差分析不出結果,大量的實踐證明金融業的數據可以開花結果;
穩中有進:金融業缺乏互聯網企業允許試錯的基因,注定了系統架構和業務應用等規劃都要一步一個腳印去走,以成熟技術為基礎來建設,同時適度進行創新;
思辨精神:不盲從于算法的神奇,不拒絕實用的查詢統計,沒有包打天下的終極算法,但是可以找到最適合企業自身的分析套路,注重分析所帶來的效果以及分析思路的合理性;
大道至簡:最準確的模型未必就是最好的模型,它常常是曇花一現的過度擬合,真正能長期穩定有效的模型總是簡單易懂的,堅持奧卡姆剃刀原則,堅持數據分析的極簡主義。
問題和數據比算法更重要
百貨商店之父約翰·沃納梅克(John Wanamaker)曾說過一句在數字化營銷領域赫赫有名的話:“我知道花費在廣告上的投入有一半是無用的,但問題是我不知道是哪一半。”
數據分析包含三個要素:問題、數據、算法。其中,業務問題和業務目標是數據分析的起點和終點,數據是分析的基礎和原料,算法是用于加工這些數據原料的工具。大部分項目的成功,這三個要素缺一不可,而前兩者更是重中之重。在張磊以往參與建設的那些項目實施中,給他留下深刻印象的并非一個個神奇的模型,而是一些大家耳熟能詳的名詞:業務問題、數據加工、模型評估、應用策略。
找到真正對企業有價值的業務問題,制定合理可行的具體目標,及時提供真正可用的高質量數據,加工出更具業務含義的數據特征,這些工作都依賴于業務崗、數據崗和分析崗的緊密合作來完成。
數據團隊角色分工
張磊曾經與咨詢公司一起幫國有大型銀行規劃其分析團隊,國外領先實踐中也把這個團隊稱為“業務分析能力中心”(BACC)。這個團隊的理想組成是分三類崗位:業務崗、數據崗和分析崗,人員配比通常是 2:3:5,而分析建模的工作量占比通常不超過項目總工作量的 10%。業務崗是分析團隊和業務部門溝通的橋梁,通常是從業務部門或分行抽調的業務骨干,他們熟悉業務流程和業務問題,能夠把分析團隊的成果與業務應用結合起來;數據崗是傳統的數據庫管理和 ETL 崗位,要求熟悉數據庫理論與技術、SQL 語言玩得滾瓜爛熟、ETL 腳本穩定高效;分析崗的人力配比最高,但并非每個人都是建模高手,實際上這部分人更像是萬金油的角色,除了熟悉常用的算法,還要同時能承擔業務崗和數據崗的部分工作,換句話說,一旦需要他們就可能變成數據崗或業務崗。
張磊強調,有太多分析建模人員把自己視為高端人才,只愿意做算法建模的工作,不愿意做數據整理這些體力活,不愿意深入了解業務知識,就如同一位廚師既不愿意了解食材的特性,又不愿意了解顧客的口味,怎么能指望他做出一道美味佳肴呢?數據科學家這個頭銜很光鮮,但全棧工程師才是它的本質。因此,從職業發展的角度來說,崗位輪換是一項很好的制度,一方面能讓員工掌握更多更全面的技能,另一方面也有利于團隊的穩定。
開源的挑戰
開源正在吞噬軟件,對金融行業也不例外。聚焦金融數字化轉型這些年,張磊見證了技術的變遷,在他看來,如今企業級大數據解決方案所采用的核心技術和架構,和過去相比已經有很大的不同。其中最為突出的一點是開源的吸引力越來越大,企業在技術選擇上逐漸向開源傾斜。
十年前:金融行業還是數據倉庫的天下,屈指可數的幾家國外知名廠商牢牢占據了這部分市場份額,十大數據主題 /ETL/ 報表查詢和 OLAP 是數據分析平臺建設的核心,以 MPP 架構為主流,分析軟件采用 C/S 架構;
十年后:數據倉庫的地位日趨微弱,Hadoop 集群(Spark、Flink 可視作 Hadoop 生態圈的一部分)成為數據管理平臺的核心,以 Python 為代表的開源軟件引領分析工具的潮流,技術的選擇強調生態圈,分析結果的應用更多基于 Web 服務調用。
從 2006 年 Doug Cutting 開源大數據經典框架 Hadoop 到現在,大數據領域已經形成了一整套相當活躍的開源生態,有非常多成熟的開源工具。張磊坦言,開源給商用解決方案帶來了很大的挑戰,這種挑戰態勢已經從十多年前的“小荷才露尖尖角”變成了現在的“楚漢相爭”。
十年前張磊與大部分銀行客戶交流,偶爾能碰到一兩個用戶使用開源的 R、MySQL 等工具來做數據分析;最近一兩年在國有大型銀行的分析團隊里,使用 Python、Spark 等開源工具來做數據分析的甚至占到了一半。
張磊認為開源日益強大最主要的原因還是在于“生態圈”。正如喬布斯借助 iPhone 讓蘋果公司再次輝煌一樣,全球億萬用戶成為 iPhone 忠實粉絲的關鍵原因并非手機外形酷炫和性能強大,AppStore 所打造的生態圈才是真正能圈住用戶的那個圈子。如果你想到和沒想到的功能,都有人給你開發出來,而且還有越來越多的人加入開發的行列,就像擁有數百萬人為你提供支持,這是每位用戶夢寐以求的情景。對于數據分析人員來說,開源社區帶來的也是這種效應。當你碰到一個業務問題不知如何下手時,當你遇到一個程序 Bug 不知如何解決時,當程序運行太慢不知道如何提高性能時,當你碰到中文亂碼如讀天書時,當你需要一個新的軟件功能時……你都能很輕松地通過搜索引擎、GitHub、Kaggle 等網站快速得到解答。解決問題變得格外快捷和方便,這是使用商用解決方案無法比擬的。
生態圈一旦打造起來,就會出現強者愈強弱者愈弱的場面,而且通常很難扭轉。眾人拾柴火焰高,好漢架不住群狼,僅靠一兩家商業公司是無法和龐大的開源社區力量抗衡的。
那提供企業級數據解決方案的公司要怎么去應對開源帶來的挑戰呢?人們面對挑戰常常會采取兩種對策:要么打,要么逃。在張磊看來,還有第三條路,就是化敵為友。為什么不可以考慮將商用解決方案與開源平臺相融合呢?接受開源發展的潮流,取長補短,商業公司依然會有自己的容身之地。
張磊目前任職的索信達就一直緊跟開源技術的發展,無論是 MySQL、Hadoop 等開源數據平臺,還是 TensorFlow、PyTorch 等開源分析框架,都融入到其對外提供的一系列解決方案之中,覆蓋精準營銷、規則引擎、場景庫、模型工廠、客戶微細分、可解釋機器學習等多個領域。此外,今年索信達積極投身國產數字化生態,與華為積極展開合作,在華為云 ModelArts 平臺上發布了首個金融營銷模型——客戶微細分,樹立行業標桿并得到了華為和頭部金融客戶的認可。
未來展望
二十年間,大數據已經從星星之火變成燎原之勢,而“新基建”會讓大數據的火越燒越旺。
張磊表示,“新基建”和大數據行業密不可分,要實現信息融合,大數據基礎設施和數據生產必不可少,要實現智能化,也需要基于大數據的深入分析。因此,隨著“新基建”等國家戰略的推行,大數據行業會越來越重要,發展也會越來越快,高速度和高加速度都是可預期的。
他強調道,大數據技術未來還有很大的發展潛力,現在的一些技術過于強調應用層的表現,模型算法變得越來越復雜脆弱,根源在于底層理論體系需要新的突破。“歐幾里得的《幾何原本》在上千年內未有發展,似乎已經足夠成熟,笛卡爾把代數和幾何相結合,立刻為世界打開另一扇窗。底層理論的突破才是真的突破,才能帶來真正革命性的變革。”
對于這些年大數據領域涌現的各種新概念,張磊認為很多只是一種發展趨勢,并不意味著實現了質變。比如這兩年格外火爆的中臺,其實是運營端和分析端發展到一定階段的彼此融合,并不會帶來翻天覆地的變化,也不是包治百病的靈丹妙藥。對于符合發展趨勢的新概念,當然要了解熟悉和探索,但真的要在金融行業變成現實完成華麗的轉身,還有很長的一段路要走。
? ? ? ?責任編輯:pj














 工商網監
工商網監
評論