") 谷歌大腦CMU聯(lián)手推出XLNet,20項任務(wù)全面超越BERT
谷歌大腦CMU聯(lián)手推出XLNet,20項任務(wù)全面超越BERT

谷歌大腦和CMU聯(lián)合團隊提出面向NLP預(yù)訓(xùn)練新方法XLNet,性能全面超越此前NLP領(lǐng)域的黃金標桿BERT,在20個任務(wù)上實現(xiàn)了性能的大幅提升,刷新了18個任務(wù)上的SOTA結(jié)果,可謂全面屠榜!
近日,谷歌大腦主任科學(xué)家Quoc V. Le在Twitter上放出一篇重磅論文,立即引發(fā)熱議:
這篇論文提出一種新的NLP模型預(yù)訓(xùn)練方法XLNet,在20項任務(wù)上(如SQuAD、GLUE、RACE) 的性能大幅超越了此前NLP黃金標桿BERT。
XLNet:克服BERT固有局限,20項任務(wù)性能強于BERT
本文提出的XLNet是一種廣義自回歸預(yù)訓(xùn)練方法,具有兩大特點:(1)通過最大化分解階的所有排列的預(yù)期可能性來學(xué)習(xí)雙向語境,(2)由于其自回歸的性質(zhì),克服了BERT的局限性。
此外,XLNet將最先進的自回歸模型Transformer-XL的創(chuàng)意整合到預(yù)訓(xùn)練過程中。實驗顯示,XLNet在20個任務(wù)上的表現(xiàn)優(yōu)于BERT,而且大都實現(xiàn)了大幅度性能提升,并在18個任務(wù)上達到了SOTA結(jié)果,這些任務(wù)包括問答、自然語言推理、情感分析和文檔排名等。
與現(xiàn)有語言預(yù)訓(xùn)練目標相比,本文提出了一種廣義的自回歸方法,同時利用了AR語言建模和AE的優(yōu)點,同時避免了二者的局限性。首先是不再像傳統(tǒng)的AR模型那樣,使用固定的前向或后向分解順序,而是最大化序列的預(yù)期對數(shù)似然性分解順序的所有可能排列。每個位置的上下文可以包含來自該位置前后的令牌,實現(xiàn)捕獲雙向語境的目標。
作為通用AR語言模型,XLNet不依賴于數(shù)據(jù)損壞。因此,XLNet不會受到BERT受到的預(yù)訓(xùn)練和微調(diào)后的模型之間差異的影響。同時以自然的方式使用乘積規(guī)則,分解預(yù)測的令牌的聯(lián)合概率,從而消除了在BERT中做出的獨立性假設(shè)。
除了新的預(yù)訓(xùn)練目標外,XLNet還改進了預(yù)訓(xùn)練的架構(gòu)設(shè)計。 XLNet將Transformer-XL的分段重復(fù)機制和相對編碼方案集成到預(yù)訓(xùn)練中,從而憑經(jīng)驗改進了性能,對于涉及較長文本序列的任務(wù)效果尤其明顯。
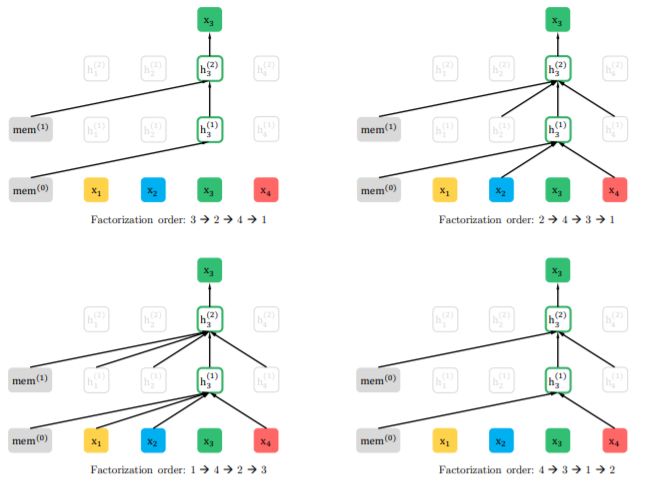
圖1:在給定相同輸入序列x,但分解順序不同的情況下,對置換語言建模目標的預(yù)測結(jié)果
圖2:(a):內(nèi)容流注意力機制,與標準的自注意力機制相同。(b)查詢流注意力,其中不含關(guān)于內(nèi)容xzt的訪問信息。(c):使用雙信息流注意力機制的置換語言建模訓(xùn)練示意圖。
全面屠榜:大幅刷新18項任務(wù)數(shù)據(jù)集SOTA性能
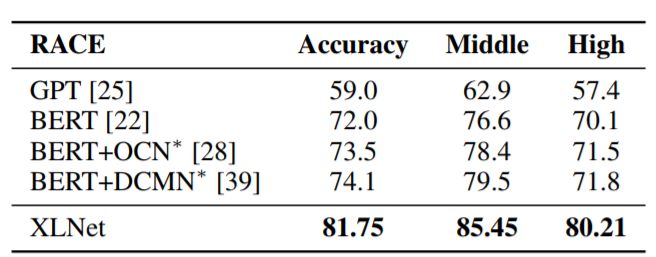
表1:與閱讀理解任務(wù)RACE測試集的最新結(jié)果的比較。 *表示使用聚集模型。 RACE中的“Middle”和“High”是代表初中和高中難度水平的兩個子集。所有BERT和XLNet結(jié)果均采用大小相似的模型(又稱BERT-Large),模型為24層架構(gòu)。我們的XLNet單一模型在精確度方面高出了7.6分
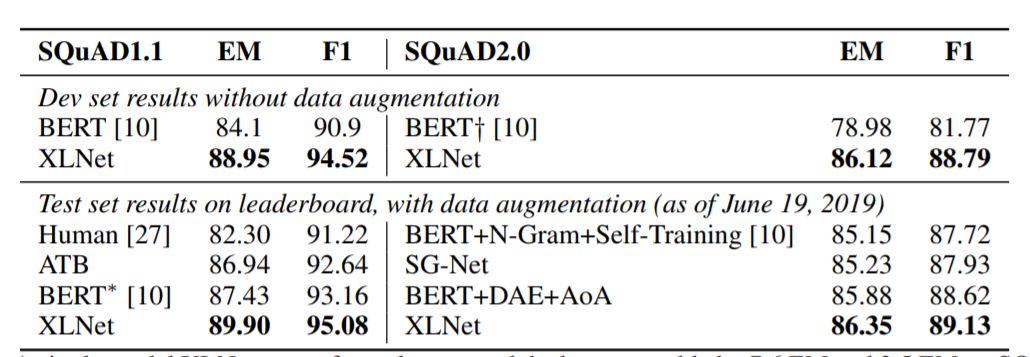
表2:單XLNet模型在SQuAD1.1數(shù)據(jù)集上的性能優(yōu)于分別優(yōu)于真人表現(xiàn)和最佳聚集模型性能達7.6 EM和2.5 EM。
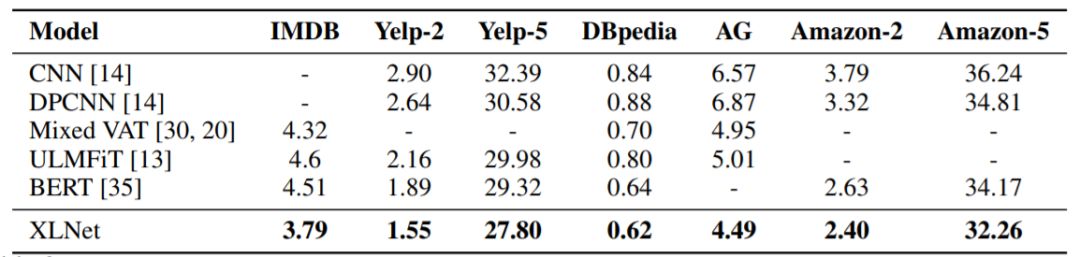
表3:與幾個文本分類數(shù)據(jù)集的測試集上錯誤率SOTA結(jié)果的比較。所有BERT和XLNet結(jié)果均采用具有相似大小的24層模型架構(gòu)(BERT-Large)
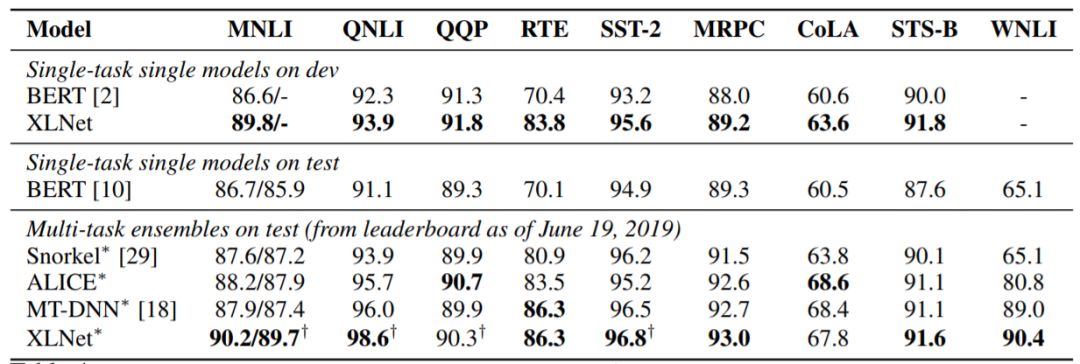
表4:GLUE數(shù)據(jù)集上的結(jié)果。所有結(jié)果都基于具有相似模型尺寸的24層架構(gòu)(也稱BERT-Large)。可以將最上行與BERT和最下行中的結(jié)果直接比較。
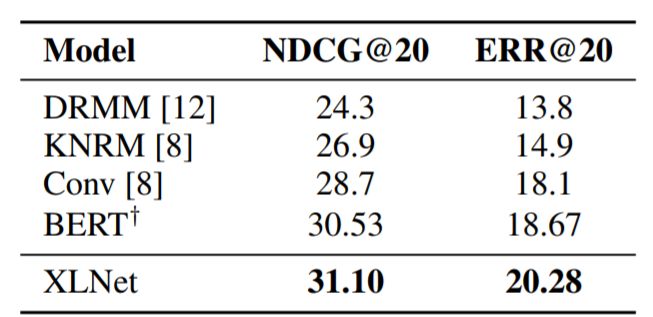
表5:與文檔排名任務(wù)ClueWeb09-B的測試集上的最新結(jié)果的比較。 ?表示XLNet的結(jié)果。
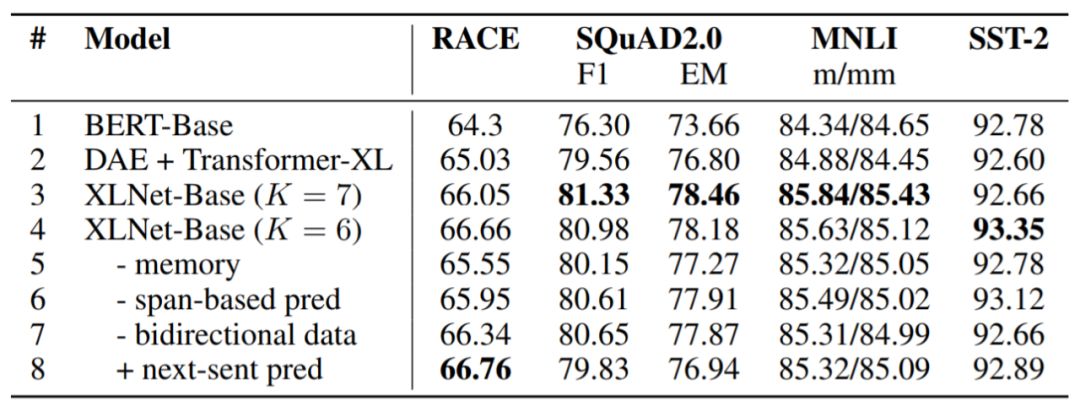
表6:我們使用BERT官方實現(xiàn)方案和XLNet超參數(shù)搜索空間在其他數(shù)據(jù)集上運行BERT,結(jié)果如圖所示,其中K是控制優(yōu)化難度的超參數(shù)。所有模型都在相同的數(shù)據(jù)上進行預(yù)訓(xùn)練。
從實驗結(jié)果可以看出,說XLNet全面超越BERT其實一點都不夸張。
知乎熱議:512TPU訓(xùn)練,家里沒礦真搞不起
有熱心網(wǎng)友一早將這篇“屠榜”論文發(fā)在了知乎上,從網(wǎng)友的評論上看,一方面承認谷歌和CMU此項成果的突破,同時也有人指出,這樣性能強勁的XLNet,還是要背靠谷歌TPU平臺的巨額算力資源,“大力出奇跡”果然還是深度學(xué)習(xí)界的第一真理嗎?
比如,網(wǎng)友“Towser”在對論文核心部分內(nèi)容的簡要回顧中,提到了XLNet的優(yōu)化方法,其中引人注目的一點是其背后的谷歌爸爸的海量算力資源的支持:

512個TPU訓(xùn)練了2.5天,訓(xùn)練總計算量是BERT的5倍!要知道作為谷歌的親兒子,BERT的訓(xùn)練計算量已經(jīng)讓多數(shù)人望塵莫及了。沒錢,搞什么深度學(xué)習(xí)?
難怪NLP領(lǐng)域的專家、清華大學(xué)劉知遠副教授對XLNet一句評價被毫無懸念地頂?shù)搅酥踝罡哔潱?/p>
目前,XLNet的代碼和預(yù)訓(xùn)練模型也已經(jīng)在GitHub上放出。
-
谷歌
+關(guān)注
關(guān)注
27文章
6254瀏覽量
111365 -
nlp
+關(guān)注
關(guān)注
1文章
491瀏覽量
23280
原文標題:NLP新標桿!谷歌大腦CMU聯(lián)手推出XLNet,20項任務(wù)全面超越BERT
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Renesas E1/E20仿真器:全面解析與應(yīng)用指南

每年10億美元,蘋果與谷歌官宣合作,Gemini大模型注入Siri
谷歌正式推出最新Gemini 3 AI模型

芯原與谷歌聯(lián)合推出開源Coral NPU IP

谷歌云發(fā)布最強自研TPU,性能比前代提升4倍

今日看點:谷歌芯片實現(xiàn)量子計算比經(jīng)典超算快13000倍;NFC 技術(shù)突破:讀取距離從 5 毫米提升至 20 毫米
AI賦能谷歌Chrome與Web工具全面升級
谷歌AI模型點亮開發(fā)無限可能
Task任務(wù):LuatOS實現(xiàn)“任務(wù)級并發(fā)”的核心引擎

揭秘LuatOS Task:多任務(wù)管理的“智能中樞”
首款A(yù)I陪伴玩具出世!樂鑫代理商飛睿科技ESP32芯片讓TA比朋友更懂你

比亞迪 · 超級e平臺 · 技術(shù)方案的全面揭秘 | 第三曲: 30000轉(zhuǎn)驅(qū)動電機 · 12項核心技術(shù)揭秘




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論