") 科普主流的神經(jīng)網(wǎng)絡(luò)模型及應(yīng)用場(chǎng)景
科普主流的神經(jīng)網(wǎng)絡(luò)模型及應(yīng)用場(chǎng)景

深度學(xué)習(xí)大熱以后各種模型層出不窮,很多朋友都在問(wèn)到底什么是DNN、CNN和RNN,這么多個(gè)網(wǎng)絡(luò)到底有什么不同,作用各是什么?
在本文我也想介紹一下主流的神經(jīng)網(wǎng)絡(luò)模型。因?yàn)楦袷絾?wèn)題和傳播原因,我把原回答內(nèi)容在這篇文章中再次向大家介紹。
大部分神經(jīng)網(wǎng)絡(luò)都可以用深度(depth)和連接結(jié)構(gòu)(connection)來(lái)定義,下面會(huì)具體情況具體分析。
籠統(tǒng)的說(shuō),神經(jīng)網(wǎng)絡(luò)也可以分為有監(jiān)督的神經(jīng)網(wǎng)絡(luò)和無(wú)/半監(jiān)督學(xué)習(xí),但其實(shí)往往是你中有我我中有你,不必死摳字眼。
有鑒于篇幅,只能粗略的科普一下這些非常相似的網(wǎng)絡(luò)以及應(yīng)用場(chǎng)景,具體的細(xì)節(jié)無(wú)法展開(kāi)詳談,有機(jī)會(huì)在以后深入解析。
文章中介紹的網(wǎng)絡(luò)包括:
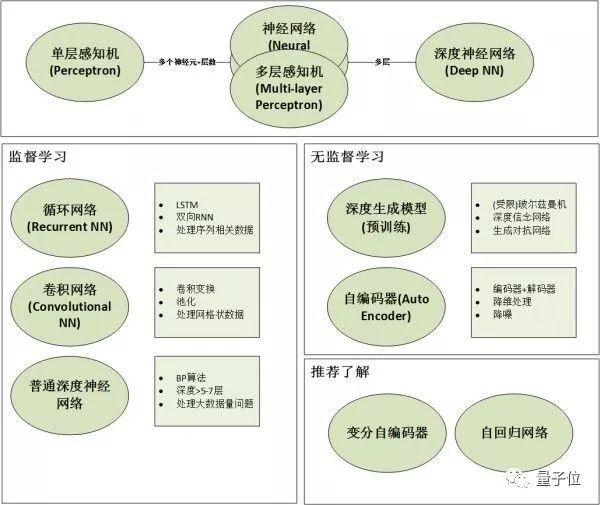
1. 有監(jiān)督的神經(jīng)網(wǎng)絡(luò)(Supervised Neural Networks) 1.1. 神經(jīng)網(wǎng)絡(luò)(Artificial Neural Networks)和深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks)
追根溯源的話(huà),神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)模型是感知機(jī)(Perceptron),因此神經(jīng)網(wǎng)絡(luò)也可以叫做多層感知機(jī)(Multi-layer Perceptron),簡(jiǎn)稱(chēng)MLP。單層感知機(jī)叫做感知機(jī),多層感知機(jī)(MLP)≈人工神經(jīng)網(wǎng)絡(luò)(ANN)。
那么多層到底是幾層?一般來(lái)說(shuō)有1-2個(gè)隱藏層的神經(jīng)網(wǎng)絡(luò)就可以叫做多層,準(zhǔn)確的說(shuō)是(淺層)神經(jīng)網(wǎng)絡(luò)(Shallow Neural Networks)。隨著隱藏層的增多,更深的神經(jīng)網(wǎng)絡(luò)(一般來(lái)說(shuō)超過(guò)5層)就都叫做深度學(xué)習(xí)(DNN)。
然而,“深度”只是一個(gè)商業(yè)概念,很多時(shí)候工業(yè)界把3層隱藏層也叫做“深度學(xué)習(xí)”,所以不要在層數(shù)上太較真。在機(jī)器學(xué)習(xí)領(lǐng)域的約定俗成是,名字中有深度(Deep)的網(wǎng)絡(luò)僅代表其有超過(guò)5-7層的隱藏層。
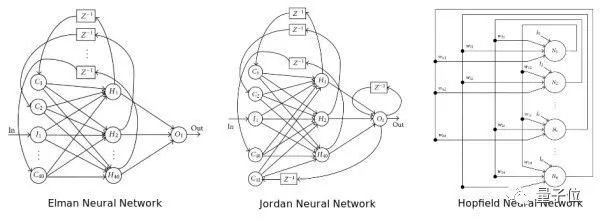
神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)指的是“神經(jīng)元”之間如何連接,它可以是任意深度。以下圖的3種不同結(jié)構(gòu)為例,我們可以看到連接結(jié)構(gòu)是非常靈活多樣的。
需要特別指出的是,卷積網(wǎng)絡(luò)(CNN)和循環(huán)網(wǎng)絡(luò)(RNN)一般不加Deep在名字中的原因是:它們的結(jié)構(gòu)一般都較深,因此不需要特別指明深度。想對(duì)比的,自編碼器(Auto Encoder)可以是很淺的網(wǎng)絡(luò),也可以很深。所以你會(huì)看到人們用Deep Auto Encoder來(lái)特別指明其深度。
應(yīng)用場(chǎng)景:全連接的前饋深度神經(jīng)網(wǎng)絡(luò)(Fully Connected Feed Forward Neural Networks),也就是DNN適用于大部分分類(lèi)(Classification)任務(wù),比如數(shù)字識(shí)別等。但一般的現(xiàn)實(shí)場(chǎng)景中我們很少有那么大的數(shù)據(jù)量來(lái)支持DNN,所以純粹的全連接網(wǎng)絡(luò)應(yīng)用性并不是很強(qiáng)。
1. 2. 循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks)和遞歸神經(jīng)網(wǎng)絡(luò)(Recursive Neural Networks)
雖然很多時(shí)候我們把這兩種網(wǎng)絡(luò)都叫做RNN,但事實(shí)上這兩種網(wǎng)路的結(jié)構(gòu)事實(shí)上是不同的。而我們常常把兩個(gè)網(wǎng)絡(luò)放在一起的原因是:它們都可以處理有序列的問(wèn)題,比如時(shí)間序列等。
舉個(gè)最簡(jiǎn)單的例子,我們預(yù)測(cè)股票走勢(shì)用RNN就比普通的DNN效果要好,原因是股票走勢(shì)和時(shí)間相關(guān),今天的價(jià)格和昨天、上周、上個(gè)月都有關(guān)系。而RNN有“記憶”能力,可以“模擬”數(shù)據(jù)間的依賴(lài)關(guān)系(Dependency)。
為了加強(qiáng)這種“記憶能力”,人們開(kāi)發(fā)各種各樣的變形體,如非常著名的Long Short-term Memory(LSTM),用于解決“長(zhǎng)期及遠(yuǎn)距離的依賴(lài)關(guān)系”。如下圖所示,左邊的小圖是最簡(jiǎn)單版本的循環(huán)網(wǎng)絡(luò),而右邊是人們?yōu)榱嗽鰪?qiáng)記憶能力而開(kāi)發(fā)的LSTM。
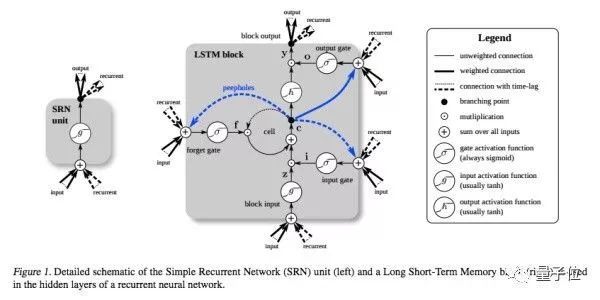
同理,另一個(gè)循環(huán)網(wǎng)絡(luò)的變種 - 雙向循環(huán)網(wǎng)絡(luò)(Bi-directional RNN)也是現(xiàn)階段自然語(yǔ)言處理和語(yǔ)音分析中的重要模型。開(kāi)發(fā)雙向循環(huán)網(wǎng)絡(luò)的原因是語(yǔ)言/語(yǔ)音的構(gòu)成取決于上下文,即“現(xiàn)在”依托于“過(guò)去”和“未來(lái)”。單向的循環(huán)網(wǎng)絡(luò)僅著重于從“過(guò)去”推出“現(xiàn)在”,而無(wú)法對(duì)“未來(lái)”的依賴(lài)性有效的建模。
遞歸神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)不同,它的計(jì)算圖結(jié)構(gòu)是樹(shù)狀結(jié)構(gòu)而不是網(wǎng)狀結(jié)構(gòu)。遞歸循環(huán)網(wǎng)絡(luò)的目標(biāo)和循環(huán)網(wǎng)絡(luò)相似,也是希望解決數(shù)據(jù)之間的長(zhǎng)期依賴(lài)問(wèn)題。而且其比較好的特點(diǎn)是用樹(shù)狀可以降低序列的長(zhǎng)度,從O(n)降低到O(log(n)),熟悉數(shù)據(jù)結(jié)構(gòu)的朋友都不陌生。但和其他樹(shù)狀數(shù)據(jù)結(jié)構(gòu)一樣,如何構(gòu)造最佳的樹(shù)狀結(jié)構(gòu)如平衡樹(shù)/平衡二叉樹(shù)并不容易。
應(yīng)用場(chǎng)景:語(yǔ)音分析,文字分析,時(shí)間序列分析。主要的重點(diǎn)就是數(shù)據(jù)之間存在前后依賴(lài)關(guān)系,有序列關(guān)系。一般首選LSTM,如果預(yù)測(cè)對(duì)象同時(shí)取決于過(guò)去和未來(lái),可以選擇雙向結(jié)構(gòu),如雙向LSTM。
1.3. 卷積網(wǎng)絡(luò)(Convolutional Neural Networks)
卷積網(wǎng)絡(luò)早已大名鼎鼎,從某種意義上也是為深度學(xué)習(xí)打下良好口碑的功臣。不僅如此,卷積網(wǎng)絡(luò)也是一個(gè)很好的計(jì)算機(jī)科學(xué)借鑒神經(jīng)科學(xué)的例子。卷積網(wǎng)絡(luò)的精髓其實(shí)就是在多個(gè)空間位置上共享參數(shù),據(jù)說(shuō)我們的視覺(jué)系統(tǒng)也有相類(lèi)似的模式。
首先簡(jiǎn)單說(shuō)什么是卷積。卷積運(yùn)算是一種數(shù)學(xué)計(jì)算,和矩陣相乘不同,卷積運(yùn)算可以實(shí)現(xiàn)稀疏相乘和參數(shù)共享,可以壓縮輸入端的維度。和普通DNN不同,CNN并不需要為每一個(gè)神經(jīng)元所對(duì)應(yīng)的每一個(gè)輸入數(shù)據(jù)提供單獨(dú)的權(quán)重。
與池化(pooling)相結(jié)合,CNN可以被理解為一種公共特征的提取過(guò)程,不僅是CNN大部分神經(jīng)網(wǎng)絡(luò)都可以近似的認(rèn)為大部分神經(jīng)元都被用于特征提取。
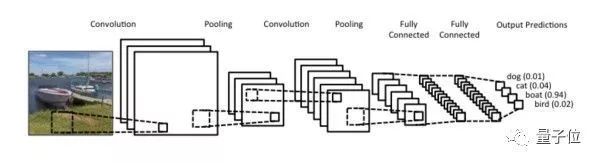
以上圖為例,卷積、池化的過(guò)程將一張圖片的維度進(jìn)行了壓縮。從圖示上我們不難看出卷積網(wǎng)絡(luò)的精髓就是適合處理結(jié)構(gòu)化數(shù)據(jù),而該數(shù)據(jù)在跨區(qū)域上依然有關(guān)聯(lián)。
應(yīng)用場(chǎng)景:雖然我們一般都把CNN和圖片聯(lián)系在一起,但事實(shí)上CNN可以處理大部分格狀結(jié)構(gòu)化數(shù)據(jù)(Grid-like Data)。舉個(gè)例子,圖片的像素是二維的格狀數(shù)據(jù),時(shí)間序列在等時(shí)間上抽取相當(dāng)于一維的的格狀數(shù)據(jù),而視頻數(shù)據(jù)可以理解為對(duì)應(yīng)視頻幀寬度、高度、時(shí)間的三維數(shù)據(jù)。
2. 無(wú)監(jiān)督的預(yù)訓(xùn)練網(wǎng)絡(luò)(Unsupervised Pre-trained Neural Networks) 2.1. 深度生成模型(Deep Generative Models)
說(shuō)到生成模型,大家一般想到的無(wú)監(jiān)督學(xué)習(xí)中的很多建模方法,比如擬合一個(gè)高斯混合模型或者使用貝葉斯模型。深度學(xué)習(xí)中的生成模型主要還是集中于想使用無(wú)監(jiān)督學(xué)習(xí)來(lái)幫助監(jiān)督學(xué)習(xí),畢竟監(jiān)督學(xué)習(xí)所需的標(biāo)簽代價(jià)往往很高…所以請(qǐng)大家不要較真我把這些方法放在了無(wú)監(jiān)督學(xué)習(xí)中。
2.1.1. 玻爾茲曼機(jī)(Boltzmann Machines)和受限玻爾茲曼機(jī)(Restricted Boltzmann Machines)
每次一提到玻爾茲曼機(jī)和受限玻爾茲曼機(jī)我其實(shí)都很頭疼。簡(jiǎn)單的說(shuō),玻爾茲曼機(jī)是一個(gè)很漂亮的基于能量的模型,一般用最大似然法進(jìn)行學(xué)習(xí),而且還符合Hebb’s Rule這個(gè)生物規(guī)律。但更多的是適合理論推演,有相當(dāng)多的實(shí)際操作難度。
而受限玻爾茲曼機(jī)更加實(shí)際,它限定了其結(jié)構(gòu)必須是二分圖(Biparitite Graph)且隱藏層和可觀測(cè)層之間不可以相連接。此處提及RBM的原因是因?yàn)樗巧疃刃拍罹W(wǎng)絡(luò)的構(gòu)成要素之一。
應(yīng)用場(chǎng)景:實(shí)際工作中一般不推薦單獨(dú)使用RBM…
2.1.2. 深度信念網(wǎng)絡(luò)(Deep Belief Neural Networks)
DBN是祖師爺Hinton在06年提出的,主要有兩個(gè)部分: 1. 堆疊的受限玻爾茲曼機(jī)(Stacked RBM) 2. 一層普通的前饋網(wǎng)絡(luò)。
DBN最主要的特色可以理解為兩階段學(xué)習(xí),階段1用堆疊的RBM通過(guò)無(wú)監(jiān)督學(xué)習(xí)進(jìn)行預(yù)訓(xùn)練(Pre-train),階段2用普通的前饋網(wǎng)絡(luò)進(jìn)行微調(diào)。
就像我上文提到的,神經(jīng)網(wǎng)絡(luò)的精髓就是進(jìn)行特征提取。和后文將提到的自動(dòng)編碼器相似,我們期待堆疊的RBF有數(shù)據(jù)重建能力,及輸入一些數(shù)據(jù)經(jīng)過(guò)RBF我們還可以重建這些數(shù)據(jù),這代表我們學(xué)到了這些數(shù)據(jù)的重要特征。
將RBF堆疊的原因就是將底層RBF學(xué)到的特征逐漸傳遞的上層的RBF上,逐漸抽取復(fù)雜的特征。比如下圖從左到右就可以是低層RBF學(xué)到的特征到高層RBF學(xué)到的復(fù)雜特征。在得到這些良好的特征后就可以用第二部分的傳統(tǒng)神經(jīng)網(wǎng)絡(luò)進(jìn)行學(xué)習(xí)。
多說(shuō)一句,特征抽取并重建的過(guò)程不僅可以用堆疊的RBM,也可以用后文介紹的自編碼器。
應(yīng)用場(chǎng)景:現(xiàn)在來(lái)說(shuō)DBN更多是了解深度學(xué)習(xí)“哲學(xué)”和“思維模式”的一個(gè)手段,在實(shí)際應(yīng)用中還是推薦CNN/RNN等,類(lèi)似的深度玻爾茲曼機(jī)也有類(lèi)似的特性但工業(yè)界使用較少。
2.1.3. 生成式對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Networks)
生成式對(duì)抗網(wǎng)絡(luò)用無(wú)監(jiān)督學(xué)習(xí)同時(shí)訓(xùn)練兩個(gè)模型,內(nèi)核哲學(xué)取自于博弈論…
簡(jiǎn)單的說(shuō),GAN訓(xùn)練兩個(gè)網(wǎng)絡(luò):1. 生成網(wǎng)絡(luò)用于生成圖片使其與訓(xùn)練數(shù)據(jù)相似 2. 判別式網(wǎng)絡(luò)用于判斷生成網(wǎng)絡(luò)中得到的圖片是否是真的是訓(xùn)練數(shù)據(jù)還是偽裝的數(shù)據(jù)。生成網(wǎng)絡(luò)一般有逆卷積層(deconvolutional layer)而判別網(wǎng)絡(luò)一般就是上文介紹的CNN。自古紅藍(lán)出CP,下圖左邊是生成網(wǎng)絡(luò),右邊是判別網(wǎng)絡(luò),相愛(ài)相殺。
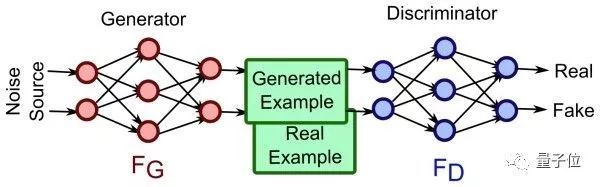
熟悉博弈論的朋友都知道零和游戲(zero-sum game)會(huì)很難得到優(yōu)化方程,或很難優(yōu)化,GAN也不可避免這個(gè)問(wèn)題。但有趣的是,GAN的實(shí)際表現(xiàn)比我們預(yù)期的要好,而且所需的參數(shù)也遠(yuǎn)遠(yuǎn)按照正常方法訓(xùn)練神經(jīng)網(wǎng)絡(luò),可以更加有效率的學(xué)到數(shù)據(jù)的分布。
另一個(gè)常常被放在GAN一起討論的模型叫做變分自編碼器(Variational Auto-encoder),有興趣的讀者可以自己搜索。
應(yīng)用場(chǎng)景:現(xiàn)階段的GAN還主要是在圖像領(lǐng)域比較流行,但很多人都認(rèn)為它有很大的潛力大規(guī)模推廣到聲音、視頻領(lǐng)域。
2.2. 自編碼器(Auto-encoder)
自編碼器是一種從名字上完全看不出和神經(jīng)網(wǎng)絡(luò)有什么關(guān)系的無(wú)監(jiān)督神經(jīng)網(wǎng)絡(luò),而且從名字上看也很難猜測(cè)其作用。讓我們看一幅圖了解它的工作原理…
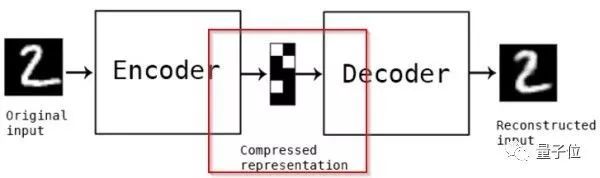
如上圖所示,Autoencoder主要有2個(gè)部分:1. 編碼器(Encoder) 2. 解碼器(Decoder)。我們將輸入(圖片2)從左端輸入后,經(jīng)過(guò)了編碼器和解碼器,我們得到了輸出….一個(gè)2。但事實(shí)上我們真正學(xué)習(xí)到是中間的用紅色標(biāo)注的部分,即數(shù)在低維度的壓縮表示。評(píng)估自編碼器的方法是重建誤差,即輸出的那個(gè)數(shù)字2和原始輸入的數(shù)字2之間的差別,當(dāng)然越小越好。
和主成分分析(PCA)類(lèi)似,自編碼器也可以用來(lái)進(jìn)行數(shù)據(jù)壓縮(Data Compression),從原始數(shù)據(jù)中提取最重要的特征。認(rèn)真的讀者應(yīng)該已經(jīng)發(fā)現(xiàn)輸入的那個(gè)數(shù)字2和輸出的數(shù)字2略有不同,這是因?yàn)閿?shù)據(jù)壓縮中的損失,非常正常。
應(yīng)用場(chǎng)景:主要用于降維(Dimension Reduction),這點(diǎn)和PCA比較類(lèi)似。同時(shí)也有專(zhuān)門(mén)用于去除噪音還原原始數(shù)據(jù)的去噪編碼器(Denoising Auto-encoder)。
-
編碼器
+關(guān)注
關(guān)注
45文章
3953瀏覽量
142603 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107742
原文標(biāo)題:主流的深度學(xué)習(xí)模型有哪些?
文章出處:【微信號(hào):IV_Technology,微信公眾號(hào):智車(chē)科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
算法工程師需要具備哪些技能?
面向嵌入式部署的神經(jīng)網(wǎng)絡(luò)優(yōu)化:模型壓縮深度解析

神經(jīng)網(wǎng)絡(luò)的初步認(rèn)識(shí)

NMSIS神經(jīng)網(wǎng)絡(luò)庫(kù)使用介紹
構(gòu)建CNN網(wǎng)絡(luò)模型并優(yōu)化的一般化建議
在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗(yàn)
液態(tài)神經(jīng)網(wǎng)絡(luò)(LNN):時(shí)間連續(xù)性與動(dòng)態(tài)適應(yīng)性的神經(jīng)網(wǎng)絡(luò)
神經(jīng)網(wǎng)絡(luò)的并行計(jì)算與加速技術(shù)
基于神經(jīng)網(wǎng)絡(luò)的數(shù)字預(yù)失真模型解決方案
小白學(xué)大模型:國(guó)外主流大模型匯總
無(wú)刷電機(jī)小波神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)子位置檢測(cè)方法的研究
神經(jīng)網(wǎng)絡(luò)專(zhuān)家系統(tǒng)在電機(jī)故障診斷中的應(yīng)用
神經(jīng)網(wǎng)絡(luò)RAS在異步電機(jī)轉(zhuǎn)速估計(jì)中的仿真研究
基于FPGA搭建神經(jīng)網(wǎng)絡(luò)的步驟解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論