 從AI模型到智算中心視角看真正的超節點系統
從AI模型到智算中心視角看真正的超節點系統

英偉達憑借其 GB200、300 NVL72 機架系統,在全球多個AI技術前沿地區已實現大規模出貨與應用,成為業內首家也是少數能將“超節點”概念從理論推向極致工程化實踐的公司。
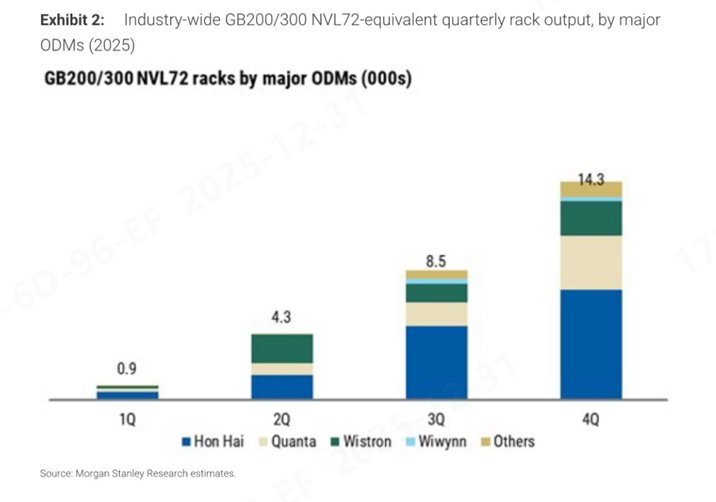
大摩對2025年全年GB200/300 NVL72出貨量的預測在28K臺左右,分別由廣達、Wistron以及鴻海等公司(ODM)組裝集成。
英偉達構建的“超節點”(Super Node)生態,是一個以CUDA統一軟件棧為基座、以極致協同設計為靈魂、貫穿從硅物理到AI應用的全棧式體系。其核心并非單一技術突破,而在于通過端到端的深度集成,將每一層的性能與效率推向極限,從而將龐大的數據中心塑造成一臺能夠高效執行單一AI任務的“巨型計算機”。
更實際的來說,超節點系統的根本需求直接地來源于上層AI的應用本身。如何將AI模型的訓練或者推理在計算、通信與內存訪問等模式下,通過深度的軟硬件協同設計,構成一個高效執行的整體,這個為特定AI負載而生的協同系統,才是真正意義的超節點。

從硬件層到模型算法,構筑全鏈條生態范式
AI生態是一個貫穿“硬件層→系統底層→框架工具→模型算法→推理服務→運維管理→終端應用”的全棧式技術體系。其核心在于打通從芯片算力到行業場景的完整鏈條,旨在實現計算資源的全局智能調度、AI模型的高效部署迭代,以及產業智能價值的全面挖掘與釋放。

服務與管理層
服務與管理層是企業AI能力的“指揮中樞”與“運行平臺”,它面向企業級用戶提供綜合服務以實現算力資源的智能化管理和服務化輸出為目標。此層包括算力調度與管理平臺(統一調度 GPU/NPU 資源)、高性能推理引擎(支持多模型并發)、一站式開發平臺(DevOps+MLOps)、全域監控與容錯系統(保障服務穩定性和可靠性)。這些服務幫助企業構建自主、高效、穩定的AI能力中臺,提高工作效率。
案例:Triton推理服務平臺是英偉達推出的開源推理服務軟件,其核心定位是成為部署與管理生產環境中AI模型的“操作系統”。它不負責底層模型的逐層優化(屬于TensorRT的工作),而是專注于解決在GPU服務器集群上,如何同時高效、穩定地服務成百上千個不同模型實例的系統級挑戰。
Triton的主要功能在于多框架、多模型、多實例并發服務:它能在一個服務器上同時加載和運行來自TensorFlow、PyTorch等多個后端的模型。每個模型還可以部署多個實例并利用動態批處理等技術,讓這些模型和實例并發處理請求,最大化GPU利用率,實現從單卡到多卡、多節點的橫向擴展。Triton可以理解為生產服務平臺,為企業級模型部署進行管理。
推理層
推理層致力于實現模型在實際業務中的高效運行,其核心目標是達到低延遲、高吞吐量、低成本的實時推理服務。它包含推理框架(如TensorRT、OpenVINO)、執行引擎(計算圖編譯器)、性能優化模塊(內存與緩存管理 KV Cache 優化、計算加速如算子融合、低精度推理、并行與調度如連續批處理、混合并行)。這些組成部分保證了模型能夠在生產環境中穩定、高效地運作。

(圖:來源英偉達)
案例:TensorRT是英偉達推出的高性能深度學習推理優化引擎,專門將訓練好的AI模型轉化為高效的推理引擎,實現最高40倍加速。它將多個計算層合并為單個優化內核。例如將"卷積→批歸一化→激活函數"三個獨立操作融合成一個CUDA kernel,減少67%的內存訪問次數和GPU啟動開銷。TensorRT實現精準與量化,最大化利用GPU Tensor Core,同時支持多精度推理包括FP16,INT8,FP8/INT4等,實現倍數性能提升和顯存節省。
此外,其具備內核自動調優功能,針對不同的模型架構、輸入尺寸和英偉達GPU架構(如Ampere, Hopper),TensorRT會從海量的優化內核實現中,自動為每一層操作選擇或生成運行最快的那個內核。這使得同一個模型在不同代次的GPU上都能獲得最優性能。
模型與算法
模型與算法層聚焦于模型本身的技術創新與優化,旨在不犧牲精度的前提下,提升模型推理速度與部署效率。該層涉及模型架構創新(如 Transformer、MoE)、模型優化技術(量化、壓縮、剪枝、蒸餾)、模型算法加速與改進,以及模型 IDE/模型倉庫(支持模型版本管理、共享與復用)。這些元素結合在一起,促進了模型的快速迭代和高效利用。

(圖:由AI Agent生成)
案例:DeepSeek-V3在架構創新上取得了突破性進展。該模型擁有671B總參數,但每個token僅激活37B參數,激活率僅為5.5%,這極大降低了推理成本 團隊引入了創新的MLA(Multi-head Latent Attention)機制,將傳統MHA(Multi-head Attention)中的KV緩存壓縮至原來的1/8,直接解決了長文本推理中的顯存瓶頸問題。
在優化層面,DeepSeek采用了FP8混合精度訓練,在不損失模型精度的前提下,將訓練速度提升了2.3倍。同時,通過自研的DualPipe流水線并行算法,實現了跨節點94.6%的通信效率,遠超傳統方案的75-80%水平。在2048個GPU節點的超節點集群上,DeepSeek-V3的訓練吞吐量達到了每秒14.8萬tokens,訓練總成本僅為557萬美元,相比GPT-4等同級別模型降低了60%以上。這一系列數據充分證明:算法架構的精心設計與硬件基礎設施的深度耦合,能夠創造出遠超線性疊加的系統級性能增益。
框架與工具
這一層面向算法工程師,提供了構建神經網絡所需的深度學習框架、分布式訓練工具包和自動化運維工具。優秀的框架層能夠自動處理復雜的并行策略(數據并行、模型并行、流水線并行),極大地降低了模型開發的門檻。

(圖:AI Agent生成)
舉例:Megatron-LM 是由NVIDIA開發的大規模語言模型訓練框架。Megatron-LM作為一個輕量級的研究框架,利用Megatron-Core以無與倫比的速度訓練LLM。Megatron-Core作為主要組件,是一個開源庫,包含GPU優化技術和對大規模訓練至關重要的前沿系統級優化。它支持多種高級模型混合并行技術,包括張量、序列、流水線、上下文和 MoE 專家并行。該庫提供可定制的構建模塊、訓練彈性功能(如快速分布式檢查點)以及許多創新功能。
在單超節點內部(如DGX系統,通過NVLink全互聯),Megatron-LM會優先將通信最密集的張量并行組部署在NVLink帶寬最高、延遲最低的GPU子集內,最大化利用其數TB/s的互聯帶寬。對于跨超節點的流水線并行,則通過InfiniBand或Spectrum-X以太網進行通信,框架會優化通信與計算的重疊,減少跨節點通信的延遲影響。
系統與底層
系統與底層負責操作系統、驅動程序及基礎運行環境的構建,其核心目標是實現硬件抽象、資源統一管理和高并發處理能力。這一層的主要任務是將復雜的硬件拓撲對上層透明化,并提供高效的內存管理、設備通信和并行計算原語。它需要解決異構硬件的兼容性問題,確保算力資源的細粒度切分與調度。
具體而言,系統與底層包含以下核心組件:操作系統與驅動程序——包括各種Linux發行版(如Ubuntu、CentOS)以及國產操作系統(如麒麟OS、統信UOS),以及針對AI加速器定制的驅動程序(CUDA Driver、ROCm等);并行與通信庫——如MPI(Message Passing Interface)用于跨節點進程通信,NCCL(NVIDIA Collective Communications Library)專門優化其GPU間集合通信;DeepEP是專門針對稀疏激活專家特性設計的通信庫,僅按需通信,從而提升帶寬和時延性能;異構計算支持——實現CPU/GPU/NPU等不同計算單元的協同工作,通過統一的運行時(如OpenCL、SYCL)屏蔽底層差異。通過這些組件,系統與底層確保了不同硬件之間的無縫協作和高效資源共享。
硬件層
硬件層作為整個算力軟件生態系統的基石,旨在為上層提供強大、異構且可擴展的計算底座。這一層包括多種類型的硬件設備,如GPU、NPU、ASIC、FPGA 等。此外,還包括高速互聯技術和海量數據存儲解決方案,確保了底層硬件能夠高效地支持大規模并行計算和數據處理需求。
計算:單卡算力
算力芯片是驅動AI大模型與推動產業發展的核心戰略資源。今年1月初,英偉達正式推出新一代“Rubin”計算架構。相比前代Blackwell,Rubin在計算、互聯與存儲方面均實現提升,單卡算力方面,其采用Vera CPU與Rubin GPU異構集成設計。
Vera CPU
集成88個定制Olympus核心,支持176線程空間多線程,兼容Armv9.2。
通過NVLink-C2C與Rubin GPU互聯,共享1.8 TB/s帶寬,為上一代Blackwell 的2倍、是PCIe Gen 6的7倍。
Rubin GPU
首次搭載Transformer引擎,可動態調節各層精度,兼顧吞吐量與關鍵區域精度。
推理性能達50 PFLOPS(NVFP4),為Blackwell的5倍,保持精度并提升BF16/FP4性能;訓練性能達35 PFLOPS,為Blackwell的3.5倍。

網絡互聯
在AI大規模集群超節點概念盛行的當下,計算芯片廠商們的競爭早已不在局限于單顆計算芯片的性能,還包括網絡互聯在內的系統性解決方案的比拼。在2020年完成對Mellanox的收購后,英偉達快速補齊了AI基礎設施網絡拼圖,實現了片間互聯(人員NVLink+ NVSwitch)和網間互聯(如ConnectX 系列網卡進階)等全棧互聯優化方案,形成了極高的技術壁壘和生態粘性。
Scale out:
Connect X系列超級網卡升級
英偉達ConnectX網卡是構建現代數據中心,特別是AI計算集群的底層關鍵技術,其通過硬件深度集成RDMA協議,以及不斷創新的硬件卸載、低延遲通信和超高帶寬技術,支撐著從傳統數據中心到“AI工廠”的演進。
英偉達于近期推出的NVIDIA ConnectX-9 超級網卡,可處理橫向擴展網絡,每個 GPU 可提供 1.6 TB/s 的 RDMA 帶寬,是上一代帶寬2倍,實現機架外部的通訊。 ConnectX-9 與 Vera CPU 共同設計,旨在最大限度地提高數據路徑效率,并引入完全軟件定義、可編程的加速數據路徑,使 AI 實驗室能夠實現針對其特定模型架構優化的自定義數據傳輸算法。其計劃搭載于Vera Rubin NVL72機架,但尚未量產出貨。
Scale up:NVLink/NVSwitch
超節點通過緊密耦合多個GPU,使其協同如單一計算單元,其核心在于實現極低延遲與超高帶寬的互聯。英偉達憑借其NVLink協議實現這一目標,該協議自2014年首次推出至今已迭代至第六代。在全新Rubin架構中集成的NVLink 6.0,使單GPU互聯帶寬達到3.6 TB/s,為上一代(NVLink 5.0)的2倍,SerDes速率達224 GT/s。
NVLink與NVSwitch協同構成了英偉達大規模高效計算集群的基礎。最新NVSwitch 6.0的端口速率提升至400 Gbps,采用SerDes技術保障高速信號傳輸;每顆GPU可實現3.6 TB/s的全互連帶寬。每個Vera Rubin NVL72機架配備9臺該交換機,總縱向擴展帶寬達260 TB/s,支持高效穩定地訓練與運行參數規模達10萬億級的超大模型。
能耗/液冷/供電
為了滿足人工智能和高性能計算對于更強數據中心的需求,越來越多高性能的計算芯片被各大廠商相繼推出。然而高性能通常與高功耗相伴,Blackwell B200 GPU單顆芯片的功耗1000W, GB200 NVL72超節點功耗超過120kw。而最新推出的Rubin NVL144和規劃中的Rubin Ultra NVL576,功耗分別突破200kw和1000kw。

液冷方面,隨著高性能服務器機柜功率普遍突破100kW,傳統風冷方案已無法滿足散熱需求。對此,液冷技術成為行業主流解決方案。以英偉達最新發布的Rubin NVL72系統為例,該平臺實現了全系統級液冷設計,完全取消傳統風冷組件,并首次采用微通道冷板技術。優化后的冷卻系統流速達60L/min以上,散熱效率為上一代系統的兩倍,同時仍支持高達45°C的進水溫度。
供電方案方面,芯片功耗的急劇上升使電力成為制約AI規模化部署的關鍵因素。為突破現有供電方案瓶頸,英偉達率先推動機架電源從54V直流向800V高壓直流(HVDC)升級。該方案采用邊緣固態變壓器(SST),直接將10kV-20kV交流電轉換為800V直流,簡化供電鏈路為“高壓市電→800V DC→芯片低壓”。此舉顯著降低了電阻損耗、釋放了機架內部空間、改善了熱管理效果,并具備高度可擴展性,支持單機架供電能力從100kW逐步提升至1MW。
總結
過去數十年,無論是硬件還是軟件層級,在進化迭代上更多考慮單點突破帶動性能狂飆。進入2025年之后,在摩爾定律及算法技術瓶頸等各方面因素推動下,產業鏈軟硬件環節更加考慮系統層級協同,如行業也不再一味追求“超級硬件”和“超級集群”,而是強調從軟件側、互聯等各方面更大程度釋放硬件的潛力。2026年,系統的優化工作將會更加精細化,與進一步探索基于低成本硬件的極致性價比,其根本驅動力與最終歸宿,都指向一個務實的目標:更高效地推動AI技術走出實驗室與數據中心,滲透至千行百業,并以更低的總體成本創造普惠價值。
-
芯片
+關注
關注
463文章
54007瀏覽量
465926 -
AI
+關注
關注
91文章
39755瀏覽量
301358 -
英偉達
+關注
關注
23文章
4086瀏覽量
99169
原文標題:Kiwi Talks:從AI模型到智算中心視角看真正的超節點系統
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
中科曙光3套scaleX萬卡超集群落地國家超算互聯網鄭州核心節點
從云端集中到邊緣分布:邊緣智算如何重塑算力網絡布局



華為超節點互聯技術引領AI基礎設施新范式
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的未來:提升算力還是智力
睿海光電領航AI光模塊:超快交付與全場景兼容賦能智算時代——以創新實力助力全球客戶構建高效算力底座
睿海光電以高效交付與廣泛兼容助力AI數據中心800G光模塊升級
面向萬億級參數大模型,“超節點”涌現

AI的未來,屬于那些既能寫代碼,又能焊電路的“雙棲人才”
【書籍評測活動NO.64】AI芯片,從過去走向未來:《AI芯片:科技探索與AGI愿景》
立訊技術解讀ETH-X超節點高速互連技術的現狀與未來




 工商網監
工商網監
評論