 “超節點+集群”:華為撞出來的算力之路
“超節點+集群”:華為撞出來的算力之路


2005年,時任英特爾CEO的保羅·歐德寧提出了名為“Tick-Tock”的戰略計劃。這一計劃以兩年為周期,快速升級半導體制程工藝與微架構,最大化激活摩爾定律。后來,這項被人稱作“鐘擺革命”的戰略行動成了計算產業的創新標桿,一舉奠定了英特爾在PC與服務器市場的長期主導地位。
可能很多人都不記得,中國科技的發展軌跡中也有過這樣一個雄心勃勃的計劃。2018年,華為公布了全棧全場景AI戰略;作為戰略的關鍵載體,華為隨后在2019年發布了昇騰910芯片。我清晰記得,當時華為宣布昇騰將持續高速演進。面對AI算力的海量需求與巨大缺口,構筑新時代算力底座的機會史無前例地擺在了一家中國企業的面前。
但幾乎就在同一時間,科技鐵幕轟然落下。2019年,美國將華為列入實體清單,隨后在2020年全面制裁華為海思。華為的芯片能力被封禁,芯片供應鏈被切斷。中國科技在AI算力領域發動的鐘擺革命,在一場噩夢中戛然而止。
那么,一切就此畫上句號了嗎?AI算力會變成中國智能化頭上的緊箍咒嗎?

時隔多年,我們等來了答案。9月18日,在華為全聯接大會2025的第一天,華為副董事長、輪值董事長徐直軍發表了“以開創的超節點互聯技術,引領AI基礎設施新范式”的主題演講,期間正式公布了昇騰演進路標,發布全球最強的算力超節點與算力集群。在眾人的一片驚呼當中,我們發現那個暌違了六年的計劃,居然回來了。
徐直軍指出,“算力過去是,未來也將繼續是人工智能的關鍵,更是中國人工智能的關鍵”,并再次強調:“基于中國可獲得的芯片制造工藝,華為努力打造‘超節點+集群’算力解決方案,來滿足持續增長的算力需求。”
這背后到底發生了什么?困擾中國AI那形如無解的算力難題,究竟是如何解開的?
或許有必要重讀一遍華為走過的路。看看他是如何用“‘超節點+集群’”將算力變成一局圍棋;又如何將它迎風展開,變成中國科技的一面旌旗。
那看似走不通的地方,把墻撞破,路就有了。
這是一條撞出來的算力之路。

把時間倒回2019年。或許很多人已經不記得,當時發布的昇騰910在多種規格與能力上都已處在全球領先水平,絲毫不遜色于英偉達的同期產品。但隨后突降的制裁,讓昇騰在諸多方面都受到了打擊與限制。從某種意義上來說,剛剛興起的“昇騰速度”突然消失了。沒有挑戰者的英偉達,在這段時間高歌猛進,從2018年發布的Turing架構一直升級到了2025年的Blackwell Ultra及Rubin架構,牢牢把控住了全球AI算力的統治地位。
而同樣在這段日子里,AI大模型經歷了井噴式發展。2018年谷歌推出的BERT-large約為3.4億參數。而到2025年OpenAI的GPT-5參數規模已經高達1.8萬億,相差了數千倍之多。這意味著全球AI算力的使用需求經歷了指數級的膨脹。昇騰可以說是被迫放棄了絕佳的發展契機,在地緣壓力下為美國企業讓路。
與此同時,現實也證明了制裁華為僅僅是科技鐵幕政策的開端。由于英偉達成了全球AI算力近乎唯一的供應源,過去幾年間美國持續升級面向中國大陸的AI算力封鎖。這迫使英偉達不斷推出性能縮水、價格更高,同時被曝出諸多問題的“中國特供版”GPU。而這種政策的本質,就是要用AI算力的供應限制,鎖死中國AI的發展上限。
從AI技術的發展路徑中可以看出,智能化的可持續發展,來源于算力的可持續獲取。每一輪AI模型的發展,都必然以AI算力的充裕供給作為創新前提。雖然幾年間昇騰為代表的中國AI算力依舊持續成長,但半導體工藝的長期落后,決定了中國AI算力在單卡性能與供貨量上勢必處在長期落后的局面。嚴重的算力困境,客觀上導致中國AI本身長期扮演學習者,而非引領者的角色。
在外部供應受限,內部成長不足的情況下,中國AI產業只能通過囤積算力、優化模型等方式緩解算力焦慮。但這些方案都是暫時的,長期來看算力困局依舊無解。
今天我們囤了卡,優化了模型,但如果AI模型進一步膨脹了呢?如果虛擬現實、機器人、自動駕駛汽車等硬件爆發,帶來了巨大的算力需求提升呢?如果最終我們期待的AGI有可能加速到來呢?
中國AI算力的發展,需要的不是暫時緩解局面,而是能夠支持中國AI的指數級成長,甚至是實現“無盡算力”。
有沒有能從根源上徹底解決AI算力困厄的機會?
消失的六年中,華為在沉默中埋頭狂奔,就是希望找到這個巨型問題的解法。

在戰略層面,中國向來講求眾志成城,以多勝少。既然單顆芯片必將長期落后,那么能不能依靠多芯片的組合來彌補單點劣勢?幸運的是,以機器學習為基礎原理的AI任務,本身就有著高并發的計算機制。在原理上看這個假設是可行的。
但如果這件事這么簡單,半導體封鎖就不會屢次在全球科技博弈中變成殺手锏。想要在AI算力上實現“集群化作戰”,需要解決數量龐大的具體問題。有些必須沖上高地,破解人有我無的困境;有些則需要竭盡所能發揮優勢,實現人無我有的利好。總而言之,那條看似最簡單直接的路,其實必須撞破無數面的墻。
在這次全聯接大會上,華為發布了諸多AI算力方面的新技術。我們可以選擇其中一些,來看看這條多芯片疊加的路是怎么被撞出來的。
HBM(High Bandwidth Memory),即高帶寬內存。它通過堆疊多個DRAM實現更高的內存帶寬和更低的計算功耗,是高性能計算與圖形處理等計算任務的必備技術。但要實現高水平的HBM,除了需要先進的封裝技術、復雜的系統級設計能力外,還要涉及材料學、熱管理等問題,是計算產業公認的頂級技術。為了解開昇騰的枷鎖,華為自研了HiBL 1.0和HiZQ 2.0兩種HBM,前者相比高性能、高價格的HBM3e/4e,能夠大大降低推理Prefill階段和推薦業務的投資,后者則可以充分滿足推理Decode階段和訓練對互聯帶寬和訪存帶寬的高要求。無數個類似的關鍵技術自研突圍,讓“人有我無”的劣勢逐漸消失,AI算力的限制逐步瓦解。
再比如,大規模AI算力集群化難以實現,很大程度在于算力節點之間的聯接能力不足,會導致嚴重的算力損耗與過強的聯接時延。這也是為什么英偉達迄今為止也只能推出NVL72機架系統。而網絡聯接恰好就是華為的看家本領。基于聯接領域超過三十年的技術積累,華為通過系統級創新,突破了大規模算力集群互聯技術的巨大挑戰。通過多端口聚合與高密封裝技術,以及平等架構和統一協議,華為實現了TB級的超大帶寬以及2.1微秒的超低時延。這就是華為面向超節點的互聯協議靈衢(UnifiedBus)。在全聯接大會2025期間,華為宣布將開放靈衢2.0技術規范,與產業伙伴共建靈衢開放生態。靈衢代表的這條路,是華為通過自身技術積累,撞出了一條“人無我有”的未來之路。
別人有的要自研,別人沒有的要開創。就這樣,華為最終把AI算力從單顆芯片拱卒過河的象棋游戲,變成了集群化算力縱橫捭闔的圍棋棋局。
規則變了,一切就都變了。

回到2025年,這時華為正不斷破解著算力集群化的挑戰。與此同時,外部環境也出現了巨大的變化。如前文所述,現階段AI大模型的參數規模已經發展到了難以置信的地步。這種情況下,大規模集群化的AI算力底座已經成為必然需求。曾經我們認為萬卡集群已經非常驚人,但現在十萬卡的訓練集群成了主流。這意味著集群化AI算力的比拼將站在舞臺中央。與之相對,單芯片能力強弱的價值在不斷弱化。在宏觀產業趨勢的驅動下,華為看到了徹底解決AI算力困境的契機。
其實早在全聯接大會2024期間,華為就已經提到了“打造‘超節點+集群’算力解決方案,持續滿足算力需求”的設想。在一年之后,華為給這個設想寫出了答卷。“超節點+集群”戰略的核心邏輯,就是要把算力競賽變成圍棋。在圍棋規則中,每一枚棋子能夠發揮的作用很小,但它們聯接在一起的價值卻是巨大的。圍棋中有所謂以“勢”壓“地”的說法。“地”是局部,是單點;而“勢”則是全局,是整體,是聯接。意思是棋手哪怕局部單點失利,也能靠整體局勢戰勝對方,所謂“先謀全局再謀一域”。
華為要的“勢”,就是“超節點+集群”。
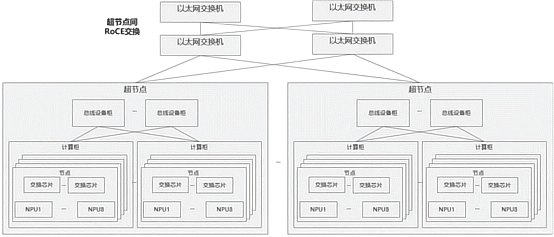
超節點,是將物理意義上的多個機柜、多個計算單元聯接成一個超級計算單元,讓它們像一臺計算機一樣運行。集群則是將多個超節點以網絡聯接在一起,讓他們像云服務一樣以軟件進行調用。
在全球AI產業的趨勢中看,超節點已經成為滿足AI算力需求的主導性產品形態,甚至是AI基礎設施建設的新常態。而華為能以昇騰為基礎打造的“超節點+集群”,恰好可以在滿足主流AI需求的同時,規避單芯片所受到的限制。這樣就在順應AI大勢的最大化昇騰價值,規避掉昇騰短板。
今年3月,華為正式推出了Atlas 900超節點,其采用384顆昇騰計算單元聯接成統一的計算節點,最大算力可達300 PFLOPS。到目前為止,這依然是全球算力規模最大的超節點。由此開始,華為正式踏入了AI超節點的征程。

但就像我們說的,華為要的不是“目前最大”、“暫時領先”,他要的是徹底解決AI算力困境,一舉打破所有禁錮。于是在全聯接大會2025期間,華為發布了最新超節點產品 Atlas 950 SuperPoD和Atlas 960 SuperPoD超節點,它們分別支持8192及15488個昇騰計算單元的聯接。在計算單元規模、總算力、內存容量、互聯帶寬等關鍵指標上實現全面領先,并且必將在漫長的未來中始終保持全球最強算力。
基于超節點,華為發布了全球最強的超節點集群Atlas 950 SuperCluster和 Atlas 960 SuperCluster,算力規模分別超過五十萬卡和達到百萬卡,這也是當之無愧的全世界最強算力集群。
如此規模的“超節點+集群”,已經必然能夠覆蓋住所有單芯片劣勢。因為相比英偉達將在明年下半年上市的NVL144,Atlas 950超節點算卡規模是其56.8倍,總算力為其6.7倍,內存容量是其15倍,互聯帶寬是其62倍。即使與英偉達計劃2027年上市的 NVL576相比,Atlas 950超節點在各方面依然領先。這意味著,無論AI大模型如何發展,實現怎樣的跨越式創新,華為都可以為其提供絕對充裕的算力,在長時間中實現AI算力供給恒定大于模型創新的算力需求。AI算力這局圍棋中的“勢”,就是“超節點+集群”構成的基礎設施海納之勢。
與此同時,華為還率先將超節點技術引入通用計算領域,發布了全球首個通用計算超節點TaiShan 950 SuperPoD,其結合GaussDB分布式數據庫,能夠徹底取代各種應用場景的大型機、小型機以及Exadata數據庫一體機。通算+智算的混合超節點,可以為一代生成式推薦系統打開全新架構方向。
“超節點+集群”的產業邏輯,在于從根本上改變AI算力的游戲規則。AI算力并不等同于單顆芯片性能。原本AI算力體系暴露了華為芯片工藝受限的劣勢,經此一役,卻可以將AI算力變成華為獨有的戰略優勢,甚至實現對英偉達的領先。
“原本大家共同遵守著一個游戲規則,但一方突然宣布游戲禁止參與。那不如就不玩你的國際象棋,直接把規則變成我的圍棋”——只有改變底層規則,華為才有機會,中國的AI算力困境才有根本解法。

“有時候,創新是被逼出來的”。
這幾年我們愈發清晰認識到這句話的意義與分量。一旦科技鐵幕落下,原本依靠的創新根基、全球化基礎設施都可能蕩然無存。這時候別無他法。只能在絕境里創新,在無路可走時撞出路來。撞開一個角,闖出一個縫,我們也就有了自己的路。向后推演,當中國AI產業開始習慣在“超節點+集群”的算力包裹下完成創新,當整個產業鏈形成了正向聯動。這條路就越走越寬廣,最終或許會成為四海同來的陽關大道。
算力是中國AI發展的基座。華為所打造的“超節點+集群”,一個核心意義在于它可以完全在中國大陸制造,并能滿足未來很長時間內中國AI的任意算力需求。國家再不需要擔心算力,產業各界再不需要為算力焦慮。這條路上不需再看任何人的臉色行事,它的根基與安全屬于我們,它的未來與無盡可能性也屬于我們。
“超節點+集群”的算力獲取方式,有沒有問題?其實是有的。問題無非兩點,一是算力集群化可能帶來軟件管理等層面問題,但華為已經有了充沛的解決方案。另一個算力集群化會帶來更大的功耗。但得益于中國完善的基礎設施建設與新能源發展,電力價格恰好就是我們的優勢。這種“恰好”,或許就是中國的棋局,就是中國給科技鐵幕的回應。
向未來看,“超節點+集群”對于中國AI,乃至中國科技整體的意義在于,它將可能提供永遠供大于求的算力資源。它實現的不是對某個模型的滿足,對某個階段的緩解,而是從戰略本質上破解中國的算力困局,甚至滿足未來中國通往AGI路上無盡的算力需求。
“確保中國AI要多少算力,就能提供多少算力”,這是華為給出的承諾。
在經歷了漫長的制裁與封鎖,討論了不知道多少次“卡脖子”之后,東方算力巨獸發出咆哮。這次我們不是應對眼前的問題,而是要徹底解決這個問題。
向未來看,向四野看,中國AI,旌旗蔽日。

2019年開始,雖然芯片供應問題阻礙了昇騰生態的發展,但昇騰依舊在幾年間支撐了中國AI的長足發展。我采訪過許多遷移到昇騰生態的企業,他們有的是出于成本考慮,有的是希望與華為合作獲得更多機會,也有人告訴我“就是相信昇騰能行,沒考慮過原因”。在智能化的引力與逆全球化的催逼下,大家心向一處,力出一孔,昇騰在它的幽暗歲月里依舊茁壯生長。
而在今天,華為原本設計好的那條昇騰之路正式回歸。放眼望去,全球AI算力需求依舊在極速增長,甚至較此前更甚。各行業的智能化渴望轉化為算力饑渴,新形態的軟硬件體系爆發必須以算力為前提。
在這個節點,AI算力領域對一場鐘擺革命的期待較六年前更甚。但此時英偉達面臨創新疲軟與產業瓶頸的挑戰,英特爾與AMD的AI算力布局方興未艾。此時,華為卻積累了各方能力,最有機會開啟一場新的鐘擺革命。在最新公布的昇騰路標中,華為宣布接下來將以幾乎一年一代算力翻倍的效率對昇騰進行升級。六年前戛然而止的雄心,在“超節點+集群”的機會下將一切重新點燃。
一切仿佛都回來了,一切仿佛又都變得不同。所有因緣際會下,我們看到此刻的華為抖落灰燼,浴火而歸。
“一顆芯片不行,就十顆一起上”,這就是華為的答案。這個答案的弦外之音是,千難萬阻,我們總有辦法。
“超節點+集群”, 會形成一個意味深長的象征。它提醒這個世界,用任何方式來圍困中國科技的發展權利,都只有一個結果:此路不通。所有手段和算計,都擋不住算力的聯接,產業生態的凝結,中國人的團結。
用AI牽引第四次工業革命,這是屬于中國的機會。誰也拿不去,誰都搶不走。
這條通往智能世界的算力之路,終是被我們撞出來了。

審核編輯 黃宇
-
華為
+關注
關注
218文章
36138瀏覽量
262531 -
AI
+關注
關注
91文章
40696瀏覽量
302338 -
算力
+關注
關注
2文章
1619瀏覽量
16819
發布評論請先 登錄
最全!一文看懂華為昇騰芯片和超節點最新演進路線

國產算力出海元年開啟

摩爾線程與中國移動研究院等,聯合發布128卡高密超節點參考設計,定義超大規模智算底座新標準
中科曙光3套scaleX萬卡超集群落地國家超算互聯網鄭州核心節點
中科曙光scaleX萬卡超集群重塑超大規模算力基礎設施
靈汐杭州電信類腦智算集群正式發布

中科曙光scaleX640超節點亮相2025世界計算大會
AI算力架構分化,連接器迎“光銅共生”格局
華為超節點互聯技術引領AI基礎設施新范式
重磅!華為昇騰384超節點真機登場,中興攜廠商首秀GPU超節點實力

一文看懂AI算力集群

有關 AI 算力,華為昇騰刷新行業記錄



 工商網監
工商網監
評論