 基于NVIDIA DGX Spark的RAG系統實戰
基于NVIDIA DGX Spark的RAG系統實戰

作者:Arm 首席解決方案架構師 沈綸銘
在大量企業級場景中,工程師和技術人員需要快速定位關鍵信息。他們查找的往往是內部資料,比如硬件規格說明、項目文檔、技術筆記等。但現實情況是,這些資料通常分散在不同系統和位置,導致傳統的關鍵詞搜索效率低下,體驗也并不理想。
此外,這類文檔往往具有高度敏感性,要么是公司內部機密信息,要么涉及核心知識產權。這意味著,它們無法被直接上傳到外部云服務或公共的大語言模型 (Large Language Models, LLMs) 中進行處理。因此,真正的技術難題在于:如何在不犧牲數據安全與隱私的前提下,構建一個人工智能 (AI) 檢索系統,實現在端側輸出安全可靠、響應迅速且上下文精準的答案?
架構解法
在 DGX Spark 上構建異構 RAG 系統
在當下的 AI 系統中,GPU 往往被視為“默認算力擔當”。但從工程視角來看,一次完整的 AI 推理流程其實由多個計算階段組成,而這些階段對算力的需求并不相同。GPU 非常擅長處理大規模矩陣運算;但還有不少環節更強調低延遲與靈活性,比如查詢解析、數據檢索以及向量編碼等。這些任務如果一味壓給 GPU,反而可能帶來不必要的延遲和資源浪費。
這正是 NVIDIA DGX Spark 桌面平臺的優勢所在,其基于 NVIDIA GB10 Grace Blackwell 超級芯片架構打造,在硬件層面為異構計算提供了天然基礎。在這樣的硬件基礎之上,結合 FAISS、llama.cpp[1]等軟件棧,以此展示 CPU 不再只是被動的預處理器,而是轉變為一個以低延遲為目標的主動計算引擎,成為驅動本地 AI 響應的關鍵力量。
[1] https://github.com/ggml-org/llama.cpp
架構與設計
在桌面級硬件上本地運行 RAG 系統
檢索增強生成 (Retrieval-Augmented Generation, RAG) 是一種非常適合用于查詢私有、本地數據的 AI 架構,它可以將這些封閉領域的知識轉換為一個可檢索的向量數據庫,再由語言模型基于檢索到的上下文在本地生成答案。這樣一來,開發者既能獲得 AI 輔助的智能問答體驗,又能完全掌控數據的隱私與所有權。
為了展示這一系統在實際中的工作方式,我們選擇了一套非常貼近開發者日常的示例數據集:完整的樹莓派硬件規格文檔、編程指南以及應用說明。這些文檔往往篇幅較長、格式不統一。很多開發者都有過類似體驗,為了查一個 GPIO 引腳定義、電壓閾值或默認狀態,不得不在多個 PDF 之間來回翻找,耗時長又低效。而在本地 RAG 系統中,用戶只需輸入自然語言問題,系統就會從本地文檔數據庫中檢索相關文本片段,再通過語言模型生成符合上下文的精準答案。
在 RAG 架構確定之后,接下來就進入了系統設計中的一個關鍵問題:向量化 (Embedding) 階段應該放在哪里運行,才能在性能和響應速度之間取得最佳平衡?
在 RAG 管線中
為何 CPU 是更明智的選擇
在 RAG 架構中,第一步是將用戶輸入的問題轉換為向量表示,即文本向量化。這一階段對整體檢索與生成的準確性至關重要,但它的計算特征,與 GPU 擅長的大規模矩陣運算其實并不匹配。在真實使用場景中,用戶的查詢通常只是一小段短語或一兩句話。這使得向量化成為一個吞吐量要求不高,但對延遲極其敏感的任務。如果把這類小批量請求交給 GPU,不僅無法發揮 GPU 的并行優勢,反而會引入額外開銷,例如調度延遲、PCIe 傳輸延遲,以及算力資源利用率偏低等問題。
正因為如此,我們選擇將向量化階段放在 CPU 上執行,而這恰好凸顯了 DGX Spark 平臺中基于 Arm 架構的系統級芯片 (SoC) 的優勢。DGX Spark 集成了由高性能 Arm Cortex-X 與 Cortex-A 核心組成的異構 CPU 架構。其中,Cortex-X 系列專為高頻、低延遲場景而設計,在多線程性能與能效之間取得了良好平衡。這使其非常適合向量化這類小批量、內存訪問密集型的推理任務。
當與 int8 量化的向量化模型結合使用時,CPU 在低功耗條件下,能提供穩定、可預測的性能表現,從而保證快速響應和流暢的交互體驗。對于桌面級或邊緣側的查詢系統而言,Cortex-X 架構針對實時搜索與推理等延遲敏感型工作負載進行了優化,在單線程性能和能效之間實現了出色平衡。
接下來我們將通過真實案例來展示,向量化質量的差異是如何直接影響整個 RAG 系統輸出結果的可靠性的。
有據可依的答案
用 RAG 消除“幻覺”問題
文本向量化這一階段的精度直接決定了后續檢索結果的相關性,也在很大程度上影響了整個 RAG 系統輸出的質量。但從更宏觀的角度來看,RAG 被設計出來,本質上是為了解決一個長期困擾 AI 應用的核心問題 —— 大模型幻覺 (Hallucination)。
當語言模型缺乏足夠的上下文信息,或無法訪問最新、權威的技術文檔時,往往會“自信滿滿”地生成聽起來很合理,但實際上并不準確的回答。在技術和企業級場景中,這種看似“正確”卻并未基于事實的輸出,往往會帶來嚴重風險。正因如此,RAG 的關鍵價值在于:它使得語言模型能基于真實文檔內容進行回答,從而降低幻覺出現的可能性。
為了驗證這一點,我們通過使用開發者的常見問題,并結合一套內部技術文檔,設計并運行了一次可控實驗,用來直觀觀察 RAG 在抑制幻覺方面的實際效果。
場景一:未搭載 RAG 系統的 LLM
查詢問題:“樹莓派 4 上,哪些 GPIO 默認配置了下拉電阻 (Pull-down Resistor)?”
當我們將這個問題直接發送給 Meta-Llama-3.1-8B 模型,而不引入 RAG 或向量檢索機制時,結果清楚地暴露了一個“無事實約束”的大模型所存在的不穩定性問題:
第一次嘗試:模型給出了一組 GPIO 列表,包括 GPIO 1、3、5、7、9、11……并聲稱這些引腳默認配置了下拉電阻。
第二次嘗試(同樣的問題):模型卻返回了一份完全不同的 GPIO 列表,包括 GPIO 3、5、7、8……,并且還重新定義了部分引腳的屬性,例如,GPIO 4 在第一次回答中被認為是上拉電阻,但在這次回答中卻變成了下拉電阻。
觀察結論:盡管兩次輸出在事實層面明顯相互矛盾且并不準確,模型在兩次回答中都表現得非常“自信”。這正是缺乏上下文約束和事實依據時,LLM 幻覺問題的典型體現。

場景二:引入 RAG 架構后查詢場景一相同問題
當我們將完全相同的問題放入本地運行的 RAG 系統中,結果發生了本質性的變化:事實準確,返回的答案與官方技術文檔完全一致,并經過人工核驗,結果正確無誤;可追溯性強,系統在回答中明確標注了信息來源,引用了數據手冊中的具體章節和表格編號,方便開發者進一步查閱與驗證。
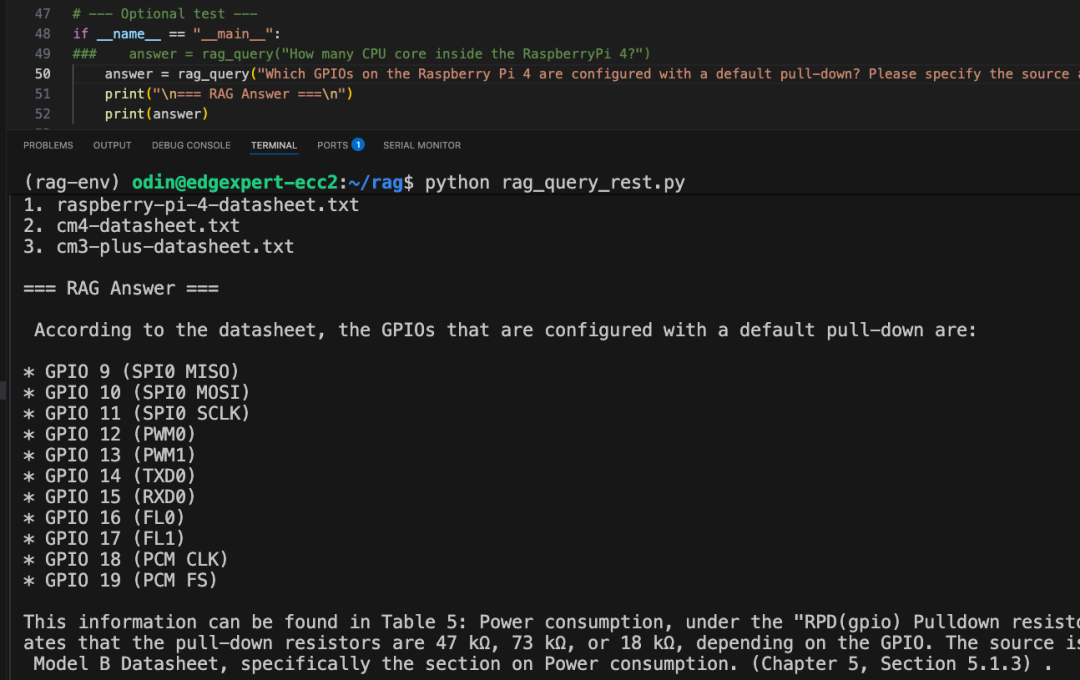
右滑查看場景二
這一對比非常直觀地體現了 RAG 架構的核心優勢。RAG 并不是讓模型基于訓練分布去“猜”答案,而是要求每一次回答都建立在真實文檔檢索結果之上。正是這種“先檢索、再生成”的機制,使得 RAG 能夠有效抑制幻覺問題,確保輸出內容真實、可驗證、可追溯,這對于技術和企業級場景尤為關鍵。
從性能角度看,在該實驗中,由 Arm CPU 處理的向量化階段,單次耗時通常在 70 至 90 毫秒之間,完全滿足交互式查詢系統對低延遲響應的要求。
架構優勢:統一內存
在傳統系統架構中,CPU 生成的數據通常需要通過 PCIe 等互連通道,傳輸到 GPU 的獨立顯存空間中。這一過程不僅會引入額外的延遲,還會占用寶貴的帶寬資源,成為整體性能鏈路中的隱性瓶頸。而在統一內存 (Unified Memory) 架構下,CPU 與 GPU 共享同一塊內存空間。這意味著,CPU 生成的向量結果可以被 GPU 直接訪問,無需顯式的數據拷貝或內存傳輸操作,從而顯著簡化數據流轉路徑。這種設計帶來的效果非常直接:推理管線更短、延遲更低、整體效率更高。對于 RAG 這類強調實時交互體驗的 AI 推理場景而言,每一毫秒的延遲都至關重要。
我們在下表中通過 DGX Spark 平臺在 RAG 各階段的內存使用情況分析,用量化數據來直觀展示這一架構的優勢。
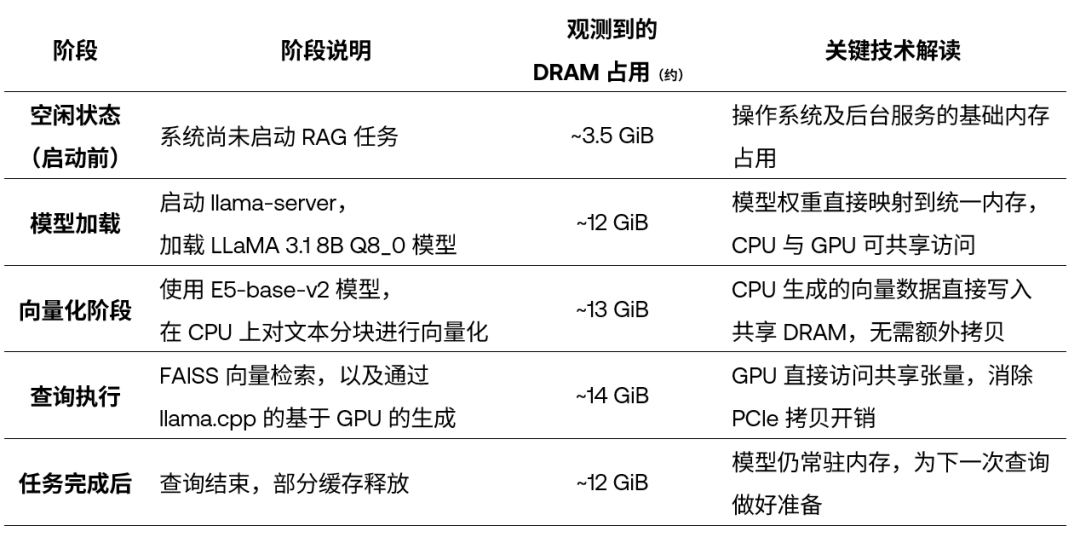
表:RAG 各執行階段的 DRAM 使用情況
請注意:本文中提到的所有性能與內存占用數據,均基于我們在 DGX Spark 平臺上的測試環境和具體工作負載配置。實際結果可能會因系統參數設置、模型規模等因素而有所不同。不過,這組內存與性能畫像仍可作為規劃本地 AI 工作負載、評估內存可擴展性與可預測性時的一個實用參考。
基于上述測試,總結出以下幾條對工程實踐非常有價值的結論:
管線各階段內存使用穩定:在整個 RAG 執行過程中,DRAM 占用從空閑時的 3.5 GiB,提高到高峰期約 14 GiB,整體增長僅約 10 GiB。這表明系統在不同階段都展現出了高效且可控的內存管理能力,資源利用非常緊湊。
模型與向量數據可持續駐留內存:模型加載完成后,內存占用上升至約 12 GiB,并且在多次查詢之后仍保持穩定。這說明模型權重和向量數據不會在查詢過程中被頻繁回收或驅逐出 DRAM,可以被復用,避免了重復加載帶來的性能損耗。
從 CPU 到 GPU 的切換階段內存變化極小:在向量化階段,內存占用約為 13 GiB;進入 GPU 生成階段后,僅小幅上升至 14 GiB。這清楚地表明:向量數據和提示詞張量被 GPU 直接就地使用,過程中沒有發生明顯的內存重新分配,也不存在 PCIe 數據拷貝開銷。
統一內存不僅降低了開發復雜度,更在執行層面提供了穩定、高效的內存運行特性,成為桌面級與邊緣側 AI 推理架構的重要基礎。
結語:CPU 是 AI 系統設計中
不可或缺的“關鍵協作者”
通過在 DGX Spark 上構建并運行一個完整的本地 RAG 系統,讓我們重新審視了 CPU 在現代 AI 架構中的真實價值。在大量實際 AI 應用中,尤其是圍繞檢索、搜索和自然語言交互的場景,計算負載并不只集中在 LLM 的推理本身。查詢解析、文本向量化、文檔檢索、提示詞組裝等關鍵環節,恰恰是 CPU 擅長的領域。
隨著 AI 持續向端側與邊緣部署演進,CPU,尤其是高能效的 Arm 架構,將在系統中扮演越來越核心的角色。CPU 會是未來低延遲、強隱私保護 AI 系統中不可或缺的核心賦能者。
如果你想復現本文中的實踐,或將類似方案用于真實項目,可以在Arm Learning Path[2]中找到完整示例與分步教程。無論你是在做概念驗證 (PoC),還是規劃生產級部署,這些模塊化教程都能幫助你快速上手真實的 RAG 工作流 —— 它們充分利用了 CPU 高效向量化與統一內存架構,并針對基于 Arm 架構的平臺進行了優化,非常適合作為本地 AI 應用落地的起點。快來與我們一起動手嘗試吧!
[2] https://learn.arm.com/learning-paths/laptops-and-desktops/dgx_spark_rag/
* 本文為 Arm 原創文章,轉載請留言聯系獲得授權并注明出處。
-
cpu
+關注
關注
68文章
11300瀏覽量
225432 -
NVIDIA
+關注
關注
14文章
5661瀏覽量
109936 -
超級芯片
+關注
關注
0文章
39瀏覽量
9330
原文標題:重新審視 CPU 在 AI 中的價值:基于 NVIDIA DGX Spark 的 RAG 實戰
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
在NVIDIA DGX Spark平臺上對NVIDIA ConnectX-7 200G網卡配置教程
NVIDIA DGX Spark系統恢復過程與步驟

NVIDIA DGX Spark快速入門指南

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機

NVIDIA GTC2025 亮點 NVIDIA推出 DGX Spark個人AI計算機

NVIDIA DGX Spark桌面AI計算機開啟預訂

NVIDIA DGX Spark新一代AI超級計算機正式交付
NVIDIA黃仁勛向SpaceX馬斯克交付DGX Spark
NVIDIA DGX Spark助力構建自己的AI模型

如何在DGX Spark上運行NVIDIA Omniverse




 工商網監
工商網監
評論