 自動駕駛大模型的訓練數據有什么具體要求?
自動駕駛大模型的訓練數據有什么具體要求?

[首發于智駕最前沿微信公眾號]想訓練出一個可以落地的自動駕駛大模型,不是簡單地給其提供幾張圖片,幾條規則就可以的,而是需要非常多的多樣的、真實的駕駛數據,從而可以讓大模型真正理解道路、交通參與者及環境的變化。

圖片源自:網絡
大模型能不能在真實交通環境中看懂路、判斷狀況、做出正確決定,關鍵在于它訓練時看到的東西有沒有覆蓋足夠多、夠真實、夠準確。若訓練數據有缺陷、種類單一、環境單一、標注不準確、傳感器不對齊,那么訓練出的大模型在真實交通環境中面對復雜、極端、多變場景時,就容易失靈、判斷失誤。
多傳感器+多模態,感知數據來源要豐富
對于自動駕駛來說,僅依靠單一攝像頭圖像無法穩定、全面地判斷路況。視覺圖像擅長提供顏色、紋理、標志、燈光信號等語義信息,但在光線不足、夜間、強逆光、遮擋以及雨雪霧等復雜環境下容易失效。因此,使用如激光雷達(LiDAR)、毫米波雷達(Radar),以及用于獲取定位、姿態和速度信息的IMU/GNSS/GPS等傳感器補全這類視覺盲區是非常有效的手段。通過將這些傳感器的數據相融合,能實現多模態感知,從而讓自動駕駛汽車更可靠地理解周圍環境。
對于能夠實現“端到端”感知、決策甚至控制的自動駕駛模型而言,多模態數據是必不可少的。這類模型需要像人一樣,綜合多種“感官”信息來理解環境,不僅會用攝像頭“看見”物體和標識,也會通過激光雷達等傳感器“測量”距離、深度與速度。當遇到惡劣天氣或視覺受限的情況時,多種數據可以相互補充,從而維持系統感知的穩定性。

圖片源自:網絡
因此,訓練這類模型的數據必須包含來自不同傳感器的信息,其中不僅要有攝像頭圖像信息,還應包括激光雷達點云、毫米波雷達數據、定位及慣性測量單元(IMU)信息等。這些不同來源的數據必須在時間上嚴格同步、在空間上精確對齊,經過校準后才能有效用于模型訓練,確保多模態融合的效果。

環境與場景需要更多樣
現實中的道路環境復雜多變,從城市街道、高速公路到鄉村小道、橋梁隧道,再到不同國家和地區的交通設施與駕駛習慣,均各有差異。同時,天氣和光照條件也時刻變化,晴天、陰天、雨雪、霧天、夜晚、逆光等場景都可能出現。
交通參與者更是種類繁多,其中不僅包括汽車、卡車、摩托車、自行車和行人,還可能涉及寵物、動物、臨時路障、施工標志等不規則障礙物,更有一些人為導致的異常障礙物。
如果訓練模型的數據只包含白天、天氣良好、道路規整、交通有序的理想場景,那么模型學到的駕駛經驗將非常有限。一旦遇到復雜、混亂或不常見的路況,自動駕駛系統就容易出現誤判甚至失效。

圖片源自:網絡
因此,想訓練好自動駕駛大模型,必須有高質量的訓練數據,其必須覆蓋廣泛、多樣的真實場景,且盡可能還原現實中可能遇到的各種情況。這也是讓自動駕駛模型具備泛化能力、安全適應不同環境的基礎。
標注與對齊—數據必須干凈、準確、有意義
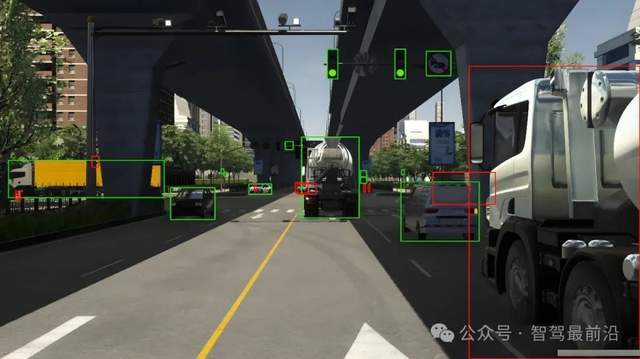
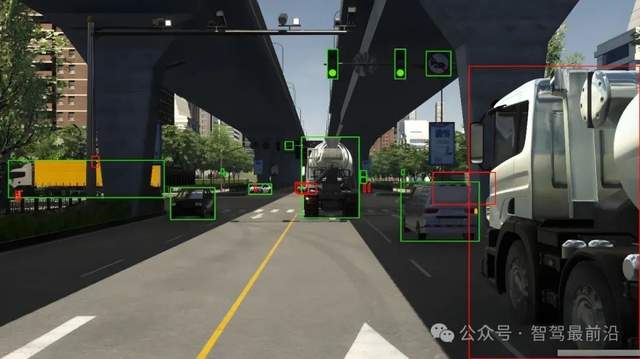
再好的傳感器、多模態數據與豐富的復雜場景,如果數據本身沒有被準確標注、嚴格同步與精確對齊,也可能達不到訓練大模型的要求。自動駕駛訓練數據不僅要求有圖像和點云,更關鍵的是要讓大模型知道圖像和點云中每個物體是什么、位于何處、屬于哪一類,以及可能的運動狀態。
為了讓模型學會識別這是車道線、那是行人、這是障礙物、那是遠處的車輛、這是從左側走來的行人、這是交通信號燈、那是交通標志、這是路邊的立柱等各類元素,訓練數據必須對這些場景進行精確而細致的標注。標注內容包括物體的3D邊界框、類別(如車輛、行人、自行車、交通標志、信號燈、障礙物等),有時還需涵蓋跨幀的運動軌跡、被遮擋的狀態、以及運動方向與速度(如果預測任務需要)等信息。
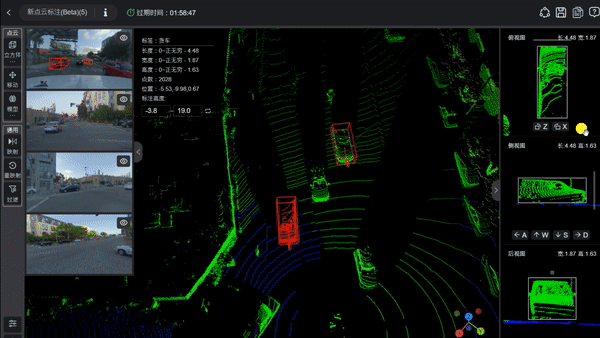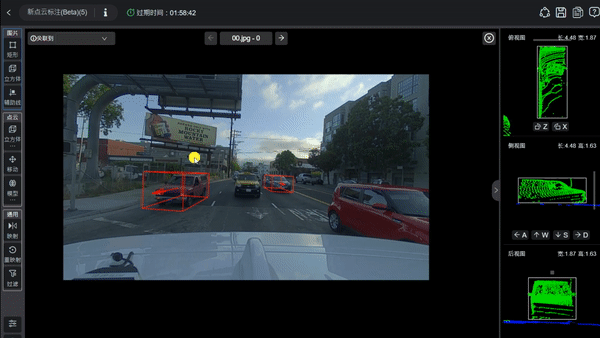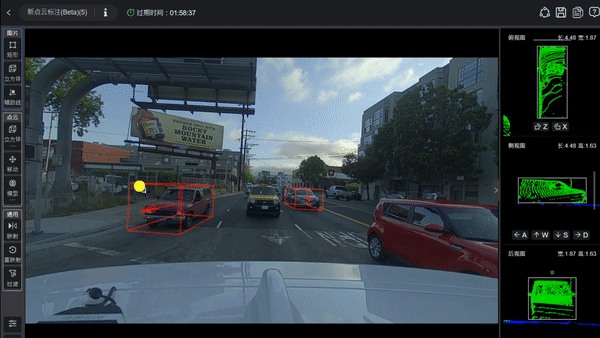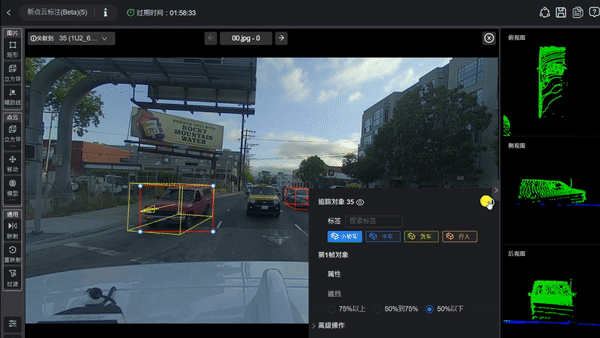
圖片源自:網絡
由于數據來自多模態傳感器(如攝像頭、激光雷達、毫米波雷達等),不同傳感器之間必須進行校準并在時間上同步,以確保同一時刻的圖像幀、激光雷達點云以及其他傳感器數據能夠完全對應。否則,模型在融合多模態信息時,會因時間偏差或空間未對齊而產生誤差,進而影響感知準確性,甚至危及行車安全。
在進行標注時,一定要注意標注的質量,錯誤標注、漏標物體、類別混淆、邊界框的位置尺寸或角度標注不準確、前后不一致或跨幀不連貫等問題,都可能導致模型學到錯誤的規律,以至于在實際部署時做出誤判。
數據需適應真實駕駛的動態、遠、長特性
自動駕駛的感知與決策需要適應真實交通環境中動態、遠距離、長時間連續的特性。交通環境并不是靜止的,而是隨時間連續變化的,物體可能處于運動狀態(如行人、車輛),會加速、減速、轉向,也可能被遮擋、進入或離開視野。一個完善的自動駕駛模型不僅要能識別當前瞬間的畫面,還需要理解隨時間變化的動態過程,預測物體未來的狀態與軌跡,并能應對遮擋、規劃路徑與決策。
因此,對于自動駕駛大模型訓練的數據僅依賴靜態圖像或單幀點云的標注數據依舊不夠。訓練數據最好包含多幀連續的時序信息,使模型能夠學習運動規律、軌跡預測、速度與加速度估計、遮擋與重現現象,以及物體之間的交互行為。當前很多多模態數據集與研究都已將時序動態建模納入考量。

圖片源自:網絡
此外,針對高速場景下的遠距離感知(如遠處車輛或障礙物),以及復雜天氣、低光照、遮擋等邊緣情況,訓練數據也需要覆蓋足夠遠、足夠復雜、足夠不完美的場景。只有這樣,模型在真實世界中面對各種環境時才能保持穩定可靠。
因此,遠距離感知、夜間、雨天、混合光照、遮擋與復雜背景等情形,都應在訓練數據中得到充分體現。目前,已有不少公開數據集致力于融合激光雷達、相機與毫米波雷達數據,實現360度覆蓋,并包含夜間、雨天、城市、高速、郊區等多種復合場景,以提升模型的適應性與穩健性。
最后的話
要訓練出能在真實路上使用的大模型,數據必須是“多、準、廣、連”。也就是說要有攝像頭、LiDAR、雷達、IMU等多種傳感器的同步數據,覆蓋白天/夜晚、多種天氣和不同道路場景,包含連續幀與大量邊緣情況,標注要精確到3D邊框、跟蹤id、速度/方向和遮擋信息,并且做好隱私合規。只有這種高質量、多模態、時序化且標注嚴謹的數據,模型才能把海量樣本變成可靠的感知、預測與決策能力,從而讓自動駕駛加速落地。
審核編輯 黃宇
-
自動駕駛
+關注
關注
793文章
14879瀏覽量
179779 -
大模型
+關注
關注
2文章
3648瀏覽量
5179
發布評論請先 登錄
大模型時代自動駕駛標注有什么特殊要求?

如何構建適合自動駕駛的世界模型?

自動駕駛中常提的模仿學習是什么?
自動駕駛大模型中常提的泛化能力是指啥?

如何訓練好自動駕駛端到端模型?

不同等級的自動駕駛技術要求上有何不同?
自動駕駛仿真測試有什么具體要求?

自動駕駛數據標注主要是標注什么?
什么是自動駕駛數據標注?如何好做數據標注?
為什么自動駕駛端到端大模型有黑盒特性?

卡車、礦車的自動駕駛和乘用車的自動駕駛在技術要求上有何不同?
自動駕駛中常提的世界模型是個啥?
新能源車軟件單元測試深度解析:自動駕駛系統視角
《2025年汽車標準化工作要點》發布,對自動駕駛行業提了啥要求?



 工商網監
工商網監
評論