") VLA與世界模型有什么不同?
VLA與世界模型有什么不同?

[首發(fā)于智駕最前沿微信公眾號(hào)]當(dāng)前自動(dòng)駕駛行業(yè),各車企的技術(shù)路徑普遍選擇了單車智能方向。而在實(shí)際落地過程中,不同企業(yè)選擇了差異化的技術(shù)實(shí)現(xiàn)方式,部分車企側(cè)重于視覺—語言—?jiǎng)幼髂P停╒ision Language Action,VLA),另一些則致力于構(gòu)建并應(yīng)用世界模型(World Model)。這兩種路徑有什么不同?

什么是VLA,什么是世界模型
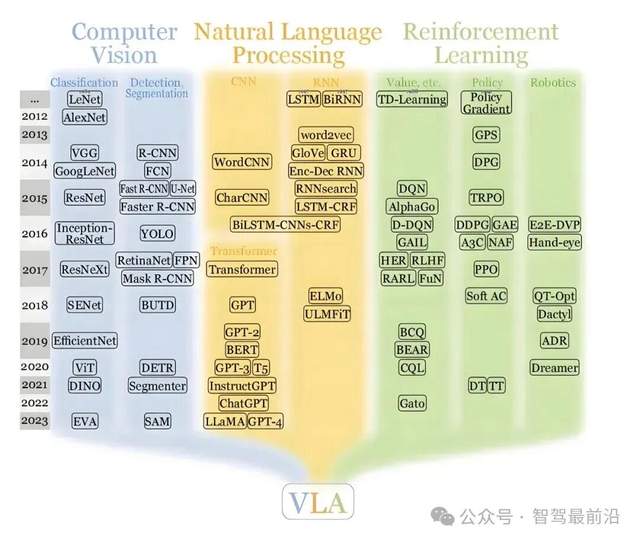
先說說VLA。VLA是英文Vision-Language-Action的縮寫,即視覺—語言—?jiǎng)幼鳌R簿褪钦f,這種模型把視覺感知、語言/語義理解/推理和動(dòng)作/控制輸出這三步融合到一個(gè)端到端(end-to-end)的體系里。

圖片源自:網(wǎng)絡(luò)
VLA先通過攝像頭(或其他傳感器)獲取環(huán)境信息,再用視覺編碼器把它轉(zhuǎn)成特征向量,然后把這些視覺特征“翻譯”到類似語言模型(LLM,large language model)可以理解的語義空間里,通過語言模型進(jìn)行高層推理、判斷(如識(shí)別車道線、行人、交通標(biāo)志,甚至判斷行人的意圖、交通規(guī)則優(yōu)先級(jí)、當(dāng)前場景該采取什么策略等等),語言模型的“結(jié)論”將會(huì)被送到動(dòng)作生成模塊,直接輸出控制指令(例如轉(zhuǎn)向、加減速、軌跡規(guī)劃)。
VLA的主要作用就是讓自動(dòng)駕駛汽車具備“看、想、做”的能力,從視覺信息到動(dòng)作輸出,中間有進(jìn)行了思考、推理、語義理解的環(huán)節(jié),而不是簡單的感知→規(guī)劃→控制那種模塊化規(guī)則的方式。
再說世界模型。世界模型的核心,是在模型大腦中里構(gòu)建一個(gè)對(duì)外部世界的虛擬、內(nèi)部模型。也就是說,它不只是看到當(dāng)前路況,而是嘗試?yán)斫馐澜绲奈锢硪?guī)律、交通規(guī)則、各種動(dòng)態(tài)變化,然后在這個(gè)內(nèi)部模型里模擬、推演、預(yù)測(cè)未來可能的場景。如可以預(yù)測(cè)前方那輛車會(huì)不會(huì)突然轉(zhuǎn)向、行人是否會(huì)沖出、天氣或光線變化會(huì)有怎樣影響等,通過對(duì)交通環(huán)境的預(yù)測(cè),可以輔助決策、規(guī)劃、甚至策略驗(yàn)證。
世界模型常被用來做仿真、模擬,通過大規(guī)模模擬極端、稀有場景、長尾場景,為自動(dòng)駕駛系統(tǒng)訓(xùn)練、驗(yàn)證、生成數(shù)據(jù)。也能讓系統(tǒng)在內(nèi)部預(yù)演并判斷風(fēng)險(xiǎn),而不僅僅依賴當(dāng)前看到的畫面。
簡而言之:
VLA=視覺+語言(語義)+動(dòng)作,通過一個(gè)端到端體系,把“看、理解、做”連起來。
世界模型=在“腦子里”建立對(duì)世界的模型、仿真,讓系統(tǒng)可以想象未來、做預(yù)測(cè)/推理,從而判斷風(fēng)險(xiǎn)。

為什么車企會(huì)選擇這兩個(gè)方向?
現(xiàn)階段眾多車企在這兩個(gè)方向并行投入,都期望這兩項(xiàng)技術(shù)能給自動(dòng)駕駛的落地帶來更多可能。之所以會(huì)這樣,是因?yàn)樽詣?dòng)駕駛對(duì)復(fù)雜性、不確定性、安全性、長尾場景的高要求,傳統(tǒng)的模塊化+規(guī)則/規(guī)劃+靜態(tài)預(yù)測(cè)模式在真實(shí)交通場景中無法完全應(yīng)對(duì)。
傳統(tǒng)的自動(dòng)駕駛系統(tǒng),主流架構(gòu)普遍采用“感知→規(guī)劃→控制”的模塊化設(shè)計(jì)。其通過攝像頭、毫米波雷達(dá)、激光雷達(dá)等傳感器采集環(huán)境數(shù)據(jù),交由感知模塊進(jìn)行目標(biāo)檢測(cè)、分類與跟蹤,識(shí)別如行人、車輛、車道線等關(guān)鍵信息;規(guī)劃模塊再依據(jù)感知結(jié)果,結(jié)合預(yù)設(shè)規(guī)則與預(yù)測(cè)模型,生成軌跡、速度及加減速等決策;控制模塊將根據(jù)決策執(zhí)行具體的轉(zhuǎn)向、油門及制動(dòng)指令。

圖片源自:網(wǎng)絡(luò)
但隨著自動(dòng)駕駛車輛在道路上應(yīng)用越來越多,復(fù)雜的路況、場景的動(dòng)態(tài)多變以及邊緣案例的持續(xù)涌現(xiàn),讓基于固定規(guī)則與靜態(tài)預(yù)測(cè)的串聯(lián)式架構(gòu)局限凸顯,難以覆蓋所有潛在場景,尤其在長尾與極端情況下,系統(tǒng)的適應(yīng)能力與魯棒性面臨顯著挑戰(zhàn)。
于是,人們希望自動(dòng)駕駛系統(tǒng)能像老司機(jī)一樣,不只是看見世界,還能“理解”、能“推理”、能“預(yù)測(cè)未來”、能“靈活應(yīng)對(duì)變化”。VLA和世界模型正是基于此出現(xiàn)的。

各自優(yōu)勢(shì)與局限
1)VLA的優(yōu)勢(shì)
語義理解+可解釋性
因?yàn)閂LA將視覺信息“翻譯”成語義(類似語言描述),所以它更貼近人類理解世界的方式。對(duì)于如行人、騎車人、交通標(biāo)志、交互意圖等復(fù)雜交通場景,VLA的語言推理能力就表現(xiàn)出其優(yōu)勢(shì)性。
端到端+整體優(yōu)化
端到端模型中,從感知到動(dòng)作的流程都被統(tǒng)一在一個(gè)模型里,中間沒有太多手工設(shè)定的規(guī)則和模塊邊界,使得它理論上可以通過大數(shù)據(jù)訓(xùn)練、學(xué)習(xí),從經(jīng)驗(yàn)里學(xué)會(huì)開車該怎樣反應(yīng),從而體現(xiàn)出較強(qiáng)的泛化能力。
適合復(fù)雜語義場景+人機(jī)交互
自動(dòng)駕駛系統(tǒng)需要實(shí)現(xiàn)與人類的高效協(xié)同,如準(zhǔn)確理解請(qǐng)?jiān)谇胺奖憷昱R時(shí)停車等自然語言指令,或在必要時(shí)向用戶解釋因左側(cè)行人突然靠近而制動(dòng)等決策原因。VLA技術(shù)所具備的多模態(tài)語義對(duì)齊與自然語言處理能力顯現(xiàn)出其獨(dú)特價(jià)值。其架構(gòu)天然支持復(fù)雜語義的解析、推理與生成,能夠?yàn)槿藱C(jī)交互提供直觀、可解釋的溝通界面,從而增強(qiáng)系統(tǒng)的可理解性與用戶體驗(yàn)。
2)VLA的局限
對(duì)環(huán)境物理動(dòng)態(tài)+長尾、稀有場景的預(yù)測(cè)能力弱
VLA本質(zhì)是“看到+推理+輸出”,如果只是基于當(dāng)前畫面做判斷,沒有對(duì)未來可能變化(比如前方車輛突然緊急剎車、行人沖出、雨雪、光照變化等)做足夠仿真及預(yù)測(cè),就可能反應(yīng)不夠及時(shí)或不夠安全。
監(jiān)督信號(hào)稀疏/學(xué)習(xí)不充分
一些最新研究指出,僅靠動(dòng)作輸出(方向盤轉(zhuǎn)角/加速/制動(dòng))作為監(jiān)督,對(duì)于一個(gè)容量很大的VLA模型來說可能遠(yuǎn)遠(yuǎn)不夠,有可能讓模型的大部分潛能無法利用。近期就有研究提出把世界建模(預(yù)測(cè)未來畫面)加到VLA的訓(xùn)練中,以獲得更豐富、更密集的監(jiān)督信號(hào)。
實(shí)時(shí)性、計(jì)算資源消耗
端到端大模型整合了多模態(tài)感知與直接動(dòng)作生成,若進(jìn)一步要求其具備長短時(shí)預(yù)測(cè)與復(fù)雜場景推理能力,將面臨算力需求、實(shí)時(shí)延遲及能效挑戰(zhàn)。這在車載嵌入式平臺(tái)上尤為突出,這樣成為其實(shí)際落地應(yīng)用中必須攻克的難題。
3)世界模型的優(yōu)勢(shì)
對(duì)未來、動(dòng)態(tài)、復(fù)雜場景的“預(yù)測(cè)+仿真+規(guī)劃”能力強(qiáng)
通過在內(nèi)部建立對(duì)世界的模型,系統(tǒng)可以不僅看到當(dāng)下,還可以推演未來,從而實(shí)現(xiàn)如模擬前車可能剎車、行人可能穿過、光照/天氣可能變、車輛可能并線等等預(yù)測(cè),然后提前規(guī)劃最安全/穩(wěn)妥的動(dòng)作。這對(duì)于自動(dòng)駕駛尤其重要,因?yàn)檎鎸?shí)道路環(huán)境充滿變化、不確定和突發(fā)性。
適合大規(guī)模訓(xùn)練/長尾/極端場景生成
在真實(shí)交通環(huán)境中,某些危險(xiǎn)或極端情況很難大量收集(比如夜間雨雪、大霧、極端行人行為、突發(fā)障礙物等),但用世界模型可以“仿真”這些情況,用來訓(xùn)練、驗(yàn)證、測(cè)試自動(dòng)駕駛系統(tǒng),增強(qiáng)其魯棒性和安全性。
提供冗余、安全校驗(yàn)機(jī)制
即使主系統(tǒng)(決策/動(dòng)作模塊)出現(xiàn)問題,世界模型也能作為“虛擬大腦”進(jìn)行冗余判斷、風(fēng)險(xiǎn)分析、仿真校驗(yàn)。某些設(shè)計(jì)還會(huì)把輕量世界模型放到車端,用作校驗(yàn)及安全網(wǎng)。
4)世界模型的局限
構(gòu)建和訓(xùn)練復(fù)雜
要讓世界模型準(zhǔn)確反映真實(shí)的交通環(huán)境,必須對(duì)車輛動(dòng)力學(xué)、交通規(guī)則、不確定性因素及行人行為等多維要素進(jìn)行高保真度建模。這種對(duì)物理、社會(huì)及動(dòng)態(tài)規(guī)則的高精度模擬,對(duì)數(shù)據(jù)質(zhì)量、計(jì)算規(guī)模與系統(tǒng)設(shè)計(jì)均提出了極高要求。正因如此,早期世界模型在實(shí)現(xiàn)實(shí)時(shí)推理與高效部署時(shí)存在諸多問題,尤其在GPU算力加速與車規(guī)級(jí)延遲約束下,其工程化應(yīng)用受到較大限制。
與語義理解/規(guī)則/常識(shí)融合較弱
純世界模型偏重物理+動(dòng)態(tài)+預(yù)測(cè)/仿真/規(guī)劃,但對(duì)復(fù)雜語義、交通規(guī)則、行人意圖、社會(huì)交互規(guī)則這些語義+常識(shí)+規(guī)則+語言的范疇不一定做得很好。對(duì)于某些需要語義理解、規(guī)則判斷、解釋及交互的場景,表現(xiàn)將不夠靈活。
可解釋性/透明性可能較差
世界模型的核心機(jī)制在于對(duì)物理規(guī)律與動(dòng)態(tài)場景進(jìn)行內(nèi)部仿真與數(shù)值化概率推演,其決策過程依賴于高維隱式狀態(tài)空間的建模與計(jì)算。但這種基于數(shù)值模擬的推理方式,在對(duì)外輸出時(shí)難以轉(zhuǎn)化為人類可直觀理解的語義解釋。在自動(dòng)駕駛的安全驗(yàn)證、法規(guī)合規(guī)、責(zé)任界定與系統(tǒng)可審計(jì)性等實(shí)際落地要求中,這種“黑箱”特性成為了不得不去面對(duì)的問題。

最后的話
VLA和世界模型,看起來像是自動(dòng)駕駛領(lǐng)域里兩種不同的“腦子設(shè)計(jì)方式”,VLA讓車具備“看到+理解+判斷+動(dòng)作”的能力;世界模型則給車提供了一個(gè)“內(nèi)部虛擬世界+預(yù)測(cè)/仿真/推演未來”的能力。但在方向選擇上,智駕最前沿以為,如果能把兩條路結(jié)合起來、互補(bǔ)使用,或許可以讓自動(dòng)駕駛真正安全、智能、穩(wěn)定地落地。
審核編輯 黃宇
-
Vla
+關(guān)注
關(guān)注
0文章
21瀏覽量
5911
發(fā)布評(píng)論請(qǐng)先 登錄
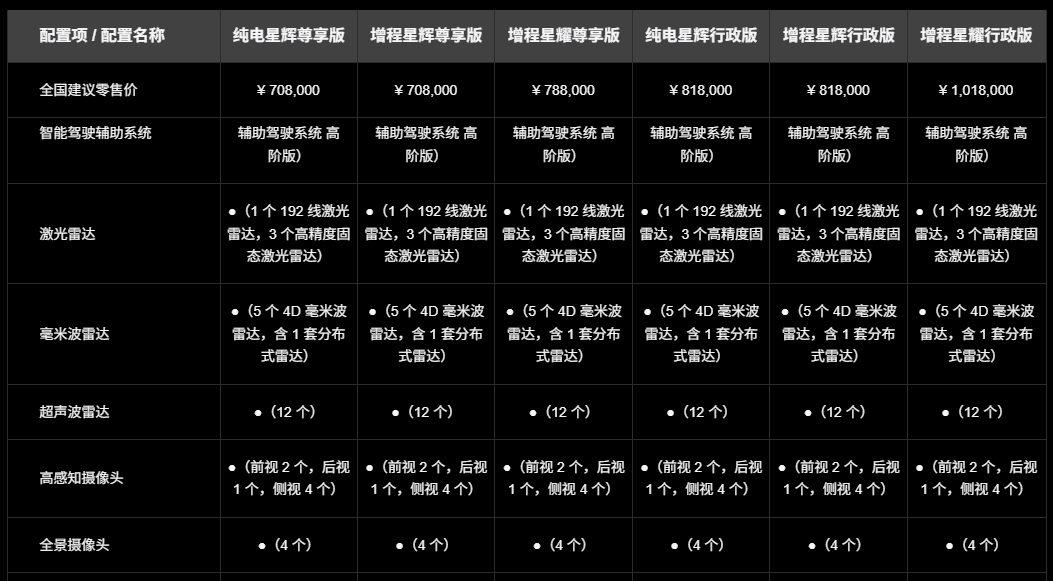
2500 TOPS!特斯拉HW5智駕算力怪獸突擊,國產(chǎn)VLA火速進(jìn)化
小鵬汽車正式發(fā)布世界模型X-World技術(shù)報(bào)告

如何構(gòu)建適合自動(dòng)駕駛的世界模型?

黑芝麻智能華山A2000芯片與Nullmax VLA算法完成深度適配
自動(dòng)駕駛中常提的世界模型是什么?
VLA模型是基于預(yù)置規(guī)則來指導(dǎo)行動(dòng)嗎?
全球首車搭載元戎啟行VLA模型,魏牌藍(lán)山智能進(jìn)階版重磅上市

世界模型是讓自動(dòng)駕駛汽車?yán)斫?b class='flag-5'>世界還是預(yù)測(cè)未來?

VLA能解決自動(dòng)駕駛中的哪些問題?
VLA和世界模型,誰才是自動(dòng)駕駛的最優(yōu)解?
自動(dòng)駕駛上常提的VLA與世界模型有什么區(qū)別?
基于大規(guī)模人類操作數(shù)據(jù)預(yù)訓(xùn)練的VLA模型H-RDT

自動(dòng)駕駛中常提的世界模型是個(gè)啥?
VLA,是完全自動(dòng)駕駛的必經(jīng)之路?
元戎啟行周光:VLA模型將于2025年第三季度量產(chǎn)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論