") VLA和世界模型,誰才是自動駕駛的最優(yōu)解?
VLA和世界模型,誰才是自動駕駛的最優(yōu)解?

[首發(fā)于智駕最前沿微信公眾號]隨著自動駕駛技術(shù)發(fā)展,其實現(xiàn)路徑也呈現(xiàn)出兩種趨勢,一邊是以理想、小鵬、小米為代表的VLA(視覺—語言—行動)模型路線;另一邊則是以華為、蔚來為主導(dǎo)的世界模型(World Model)路線,這兩種路徑都為自動駕駛快速落地提供了可能,那誰才是最優(yōu)解?
什么是VLA模型?
VLA模型,即視覺—語言—行動模型,是將視覺感知、語言理解和動作生成串聯(lián)起來的一套方法。它先是通過視覺編碼器,將攝像頭看到的畫面轉(zhuǎn)換成語義豐富的特征向量,像是SigLIP、Dino V2/V3等這類模型就是用于完成這項任務(wù)的。這些視覺特征會被“翻譯”成一種類似語言的表征單元(token),并將其送入一個大型語言模型(LLM)中。LLM經(jīng)過多模態(tài)改造后,其任務(wù)不再只是生成文本,而是能夠基于這些視覺信息進行如分析車道線的狀況、預(yù)判前方行人的意圖、或者評估不同駕駛策略的合理性等更高層次的語義推理。LLM的推理結(jié)果會被轉(zhuǎn)化為例像是軌跡和速度,從而驅(qū)動車輛執(zhí)行等具體的控制指令。
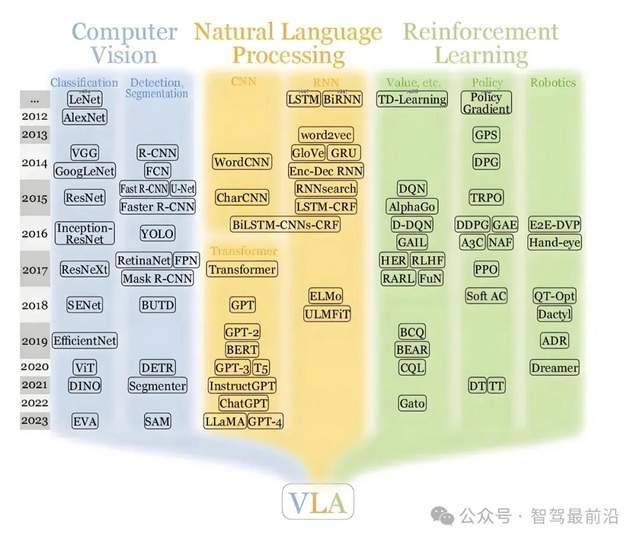
圖片源自:網(wǎng)絡(luò)
從理論上看,VLA還是比較難以理解的,通俗理解下就是,VLA是讓車輛先用語言描述清楚眼睛看到了什么,再用語言進行思考,最后把思考結(jié)果轉(zhuǎn)化為行動。這種方法的優(yōu)勢在于,語言層面天然適合進行抽象和長時序推理,也便于整合上下文信息和規(guī)則知識,這使得從感知到?jīng)Q策的橋梁可以建立在更明確、更具可遷移性的語義表示之上。
因為語言模型擅長將零散信息組合成高層結(jié)論,VLA在遇到多種復(fù)雜場景時,理論上能更容易進行“概念化”的判斷,同時也更容易將人類規(guī)則、法規(guī)或場景說明以文本形式融入到訓(xùn)練與調(diào)優(yōu)流程中。
當然,想將視覺特征可靠地轉(zhuǎn)換為LLM能夠有效利用的token并不容易,有很多問題需要解決。視覺與語言之間的信息損失和對齊問題是一定要解決的;語言推理產(chǎn)生的結(jié)論也需要被嚴格約束在物理可行的動作范圍內(nèi),否則就可能出現(xiàn)“想法很好”但“執(zhí)行不安全”的情況。此外,LLM的推理開銷、系統(tǒng)實時性以及決策的可解釋性等都是需要解決的問題。雖然語言的抽象能力很強,但物理世界對控制精度和約束的要求極高,如何在語義抽象與精確控制之間建立可信賴的映射,更是VLA需要去攻克的。
VLA的優(yōu)勢在于其強大的語義理解能力,對復(fù)雜的社交互動和規(guī)則理解有天然優(yōu)勢,適合用較少的顯式規(guī)則去捕捉場景中的行為意圖。對于那些希望利用“數(shù)據(jù)和模型”將駕駛經(jīng)驗遷移到不同車型、不同城市的廠商而言,VLA的通用性和抽象能力是非常有吸引力的。其短板在于,對物理精度和安全約束的保障需要額外的工程手段,且其推理延遲、模型可解釋性和系統(tǒng)驗證的難度都相對更高。

什么是世界模型路線
世界模型的核心思想,是把環(huán)境、物體和行為都建模成一個可計算、可推演的“物理世界”,決策不用借助自然語言作為中介,可以直接在狀態(tài)空間中進行。世界模型強調(diào)“空間認知與物理推演”,它從多傳感器數(shù)據(jù)出發(fā),能構(gòu)建一個連續(xù)、可預(yù)測的世界狀態(tài)表示,并基于物理規(guī)則進行行為生成與驗證。
以華為WEWA的“云端與本地協(xié)同”模式為例,團隊可以在云端構(gòu)建高保真的物理仿真環(huán)境,讓模型在虛擬世界中不斷“駕駛”并生成海量的仿真軌跡。仿真環(huán)境能提供極高的數(shù)據(jù)密度,模型可以在大量受控的、甚至是極端的場景中學(xué)習(xí)物理世界的因果關(guān)系。通過一套對模型生成行為進行打分的獎懲機制,模型可以逐漸學(xué)會在各種情境下如何規(guī)避風(fēng)險,并做出合規(guī)且穩(wěn)定的決策。

華為WEWA技術(shù)架構(gòu),圖片源自:網(wǎng)絡(luò)
訓(xùn)練完成后,通過模型蒸餾或壓縮技術(shù),將復(fù)雜的云端模型轉(zhuǎn)化為能在車端實時運行的輕量版本,使得車輛能夠根據(jù)實時傳感器數(shù)據(jù)直接生成軌跡與控制命令。
世界模型的優(yōu)勢在于其出色的可控性和物理一致性。因為決策是建立在明確的、可驗證的狀態(tài)與動力學(xué)模型之上,所以更容易進行形式化驗證、安全邊界檢查以及物理約束的強制執(zhí)行。這對于安全關(guān)鍵場景的可解釋性和可證偽性也更為有利。由于采用的是仿真訓(xùn)練,可以人為創(chuàng)造現(xiàn)實中罕見但對安全至關(guān)重要的極端場景,能有效彌補真實道路采集數(shù)據(jù)的不足,從而提升系統(tǒng)在危險情況下的魯棒性。
與VLA模型一樣,世界模型技術(shù)路線也有很多問題需要解決。高保真仿真、復(fù)雜動力學(xué)建模以及對自車與環(huán)境的精確重建,都需要龐大的算力支撐與成本投入,這將是一筆非常大的開銷。對于如何構(gòu)建足夠多樣化的仿真環(huán)境以覆蓋現(xiàn)實世界的復(fù)雜性,并有效彌合“仿真與現(xiàn)實之間的遷移鴻溝”,也是一個需要解決的問題。此外,該路線對感知傳感器的類型與精度存在較高依賴性,若采用以激光雷達為核心的方案,將直接讓系統(tǒng)成本與部署門檻直接提升,進而會影響其規(guī)模化落地的進程。
世界模型的優(yōu)勢在于其決策結(jié)果更接近真實的物理世界,易于注入約束并進行形式化的檢驗,仿真訓(xùn)練能夠高效覆蓋各類風(fēng)險場景,適合對安全性要求極高的產(chǎn)品化路徑。其短板在于仿真與現(xiàn)實的差距難以完全消除、系統(tǒng)建模復(fù)雜,以及對高精度傳感器的依賴可能推高整體成本。此外,在某些需要“常識”或長時序社會推理的場景下,純物理規(guī)則驅(qū)動的模型可能不如引入語言中介的模型那樣靈活和直觀。
兩條路線的核心差異
將兩條路線進行比較,會發(fā)現(xiàn)它們在“世界如何表示”、“決策如何形成”、“訓(xùn)練數(shù)據(jù)來源”以及“部署策略”這幾個維度上是完全不同的。
對于世界如何表示的問題上,VLA傾向于用語義化的token來表達世界,突出抽象概念和高層意圖,這種表示方式便于將人類知識和規(guī)則以語言形式注入系統(tǒng);而世界模型則將世界表示為連續(xù)的狀態(tài)變量和實體間的空間關(guān)系,更強調(diào)幾何屬性、動力學(xué)與可預(yù)測性。
在推理機制上,VLA依賴大語言模型的語義推理能力,擅長處理長時序依賴和復(fù)雜上下文的綜合判斷,但需要將語言結(jié)論映射到具體動作,并確保其滿足物理約束;世界模型則直接在狀態(tài)空間進行物理推演和策略生成,其推理過程更貼近物理規(guī)律,結(jié)果通常更易于驗證,但在處理語義模糊、規(guī)則解釋或長時序社會行為推斷時,靈活性可能不如前者。
兩者訓(xùn)練數(shù)據(jù)的來源也有明顯差異。VLA更依賴大量經(jīng)過標注的多模態(tài)數(shù)據(jù)、真實道路場景數(shù)據(jù),以及用于對齊的語言數(shù)據(jù);世界模型則重度依賴高質(zhì)量的仿真數(shù)據(jù)以及多傳感器融合的真實駕駛?cè)罩荆抡鏀?shù)據(jù)在數(shù)據(jù)量和場景可控性上占據(jù)明顯優(yōu)勢。
兩者在部署策略上也各有側(cè)重。VLA需要更復(fù)雜的模型棧來完成從視覺到語言再到控制的完整映射,LLM帶來的推理開銷和實時性要求會影響其在車端的直接應(yīng)用,因此很多技術(shù)方案中會采用輕量化、模型蒸餾或分層決策的方式,將高層規(guī)劃放在云端或開發(fā)階段,而將受嚴格約束的執(zhí)行模塊部署在車端。世界模型的“云端仿真訓(xùn)練、車端模型蒸餾”流程則更為直接,將仿真中學(xué)到的策略壓縮后運行在車端,車端系統(tǒng)可以根據(jù)實時感知直接進行物理層面的決策。
最后的話
將VLA和世界模型放在一起比較,會發(fā)現(xiàn)它們各有專長,也各有局限,如果要給出誰更具優(yōu)勢的結(jié)論,或許會很難。未來,VLA與世界模型或?qū)⒆呦蛏疃热诤系姆较颍琕LA作為感知與決策的“大腦”,負責(zé)理解復(fù)雜場景與高層規(guī)劃;世界模型則成為控制與執(zhí)行的“小腦”,確保所有動作均符合物理規(guī)律與安全邊界。
審核編輯 黃宇
-
Vla
+關(guān)注
關(guān)注
0文章
21瀏覽量
5911 -
自動駕駛
+關(guān)注
關(guān)注
794文章
14942瀏覽量
180923
發(fā)布評論請先 登錄
理想汽車發(fā)布下一代自動駕駛基礎(chǔ)模型MindVLA-o1

如何構(gòu)建適合自動駕駛的世界模型?

2026年,3DGS和世界模型,在自動駕駛仿真中的組合應(yīng)用

已有VLM,自動駕駛為什么還要探索VLA?
黃仁勛:未來十年很多汽車是自動駕駛 英偉達發(fā)布Alpamayo汽車大模型平臺
自動駕駛中常提的世界模型是什么?
VLA模型是基于預(yù)置規(guī)則來指導(dǎo)行動嗎?
VLA與世界模型有什么不同?

世界模型是讓自動駕駛汽車理解世界還是預(yù)測未來?

VLA能解決自動駕駛中的哪些問題?
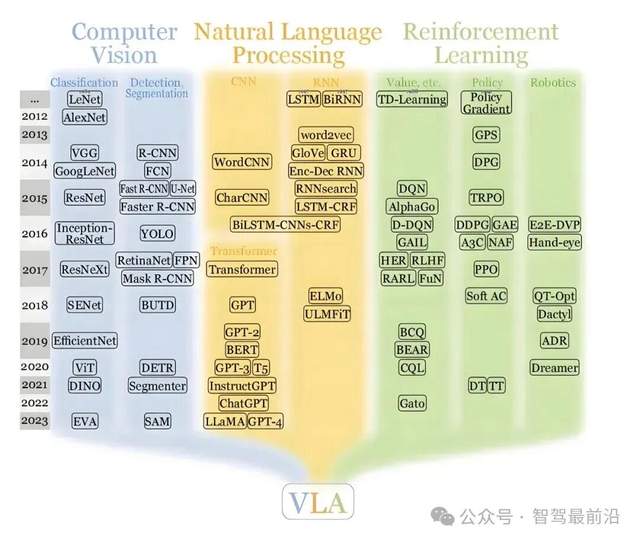
大模型中常提的快慢思考會對自動駕駛產(chǎn)生什么影響?

PLC vs 嵌入式:誰才是工業(yè)場景的“最優(yōu)解”?

自動駕駛上常提的VLA與世界模型有什么區(qū)別?
自動駕駛中常提的世界模型是個啥?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論