 基于RT-Thread的RPMsg-Lite異構多核通信原理分析 | 技術集結
基于RT-Thread的RPMsg-Lite異構多核通信原理分析 | 技術集結

目錄
說明
初識rpmsg-lite
rpmsg-lite組件優勢
rpmsg-lite工程架構
rpmsg-lite通信流程(MCMGR)
1 說明
本文檔旨在說明如何在RT-Thread(運行于Cortex-M85核)和裸機程序(運行于Cortex-M33核)之間使用rpmsg-lite進行通信,并采用MCMGR組件替代rpmsg-lite原生的隊列機制實現雙核間同步管理。
硬件平臺:Renesas RA8P1( ARM Cortex-M85 & ARM Cortex-M33)

或復制鏈接購買:https://item.taobao.com/item.htm?ft=t&id=987791181903
軟件環境
M85核:RT-Thread操作系統
M33核:裸機程序
通信組件:rpmsg-lite + MCMGR
2 初識rpmsg-lite
RPMsg-Lite 是一款輕量級開源異構處理器通信框架,適用于多核系統中的小型微控制器(MCU)。
它支持在非對稱多處理(AMP)配置中,例如運行 Linux 的主處理器與運行實時操作系統(如 RT-Thread)的協處理器之間進行高效的消息傳遞。
RPMsg-Lite 針對資源受限環境設計,相比 OpenAMP 提供更簡化的 API,支持零拷貝和靜態內存選項,并確保與 RPMsg 協議兼容。通過使用共享內存進行數據交換,要求配置非緩存內存,非常適合卸載 CPU 密集型任務。
3 rpmsg-lite組件優勢
1)靜態API創建
相比較RPMsg,RPMsg-Lite采用靜態API創建方式,相比較動態分配,靜態API創建的方式至少減少了5KB的代碼體量,也避免了動態內存管理開銷。

2)基于共享內存的數據零拷貝
相比較傳統驅動外設來說,都需要經歷由應用層->驅動層->硬件緩沖區這么多次拷貝的過程,相對應的也會帶來一定的延遲;而RPMsg-Lite則是數據零拷貝的這么一種實現方式,也就是應用層->共享內存方式,僅一次的內存拷貝,將數據交換周期能夠最小降低至μs微秒級
(當然這部分依賴于雙核硬件平臺的IPC機制,即處理器間通信)

3)硬中斷的高效觸發
對于傳統共享中斷來說,都是需要輪詢所有關聯外設的狀態寄存器;而RPMsg-Lite直接使用 platform_notify 來主動觸發核間中斷通知,同時這個觸發時機可以由用戶決定,比如說累計n個消息后觸發中斷,以此來批量處理核間通信。

4 rpmsg-lite工程架構
rpmsg-lite工程分為兩個版本:
RT-Thread + Freertos + RPMsg-Lite:該示例統一使用RPMsg-Lite結合RTOS的消息隊列來實現子組件queue

RT-Thread + Bera metal + RPMsg-Lite + MCMGR:為了方便裸機系統能夠實時同步主次核之間的狀態,移植了官方的MCMGR組件(multiple core manager)

5 rpmsg-lite通信流程(RTOS)
需要說明的是,裸機rpmsg-lite與RTOS版的rpmsg-lite的收發邏輯是不一樣的,這里分開說明

這里繪制了一張圖簡單說明下,首先明確上層留給用戶的rpmsg-lite api,最為關鍵的就是rpmsg-dev的初始化、消息的發送與接收:
1) 初始化
# masterstructrpmsg_lite_instance*rpmsg_lite_master_init(void*shmem_addr, size_tshmem_length, uint32_tlink_id, uint32_tinit_flags)# remotestructrpmsg_lite_instance*rpmsg_lite_remote_init(void*shmem_addr,uint32_tlink_id,uint32_tinit_flags)
這一步會分別在master和remote初始化一個 rpmsg-dev 實體,并且聲明共享內存起始地址,這個過程中會綁定兩個virtualqueue的回調函數(收發關鍵)
callback[0] = rpmsg_lite_rx_callback;
callback[1] = rpmsg_lite_tx_callback;
structrpmsg_lite_endpoint*rpmsg_lite_create_ept(structrpmsg_lite_instance *rpmsg_lite_dev, uint32_taddr, rl_ept_rx_cb_trx_cb, void*rx_cb_data);
這里最終會傳遞給 virtqueue 的初始化創建,并作為 callback_fc 參數進行綁定:
int32_tvirtqueue_create(uint16_tid, constchar *name, structvring_alloc_info *ring, void(*callback_fc)(structvirtqueue *vq), void(*notify_fc)(structvirtqueue *vq), structvirtqueue **v_queue)
與此同時,virtqueue_notify() 函數會作為第五個參數綁定為通知函數,這一步對接到移植層的子 layer:enviroment layer,也就是 platform_notify(),用于觸發通知另外一個核心,一般使用核間中斷,基于此,就可以觸發另一個核心來處理接收數據的邏輯了:
voidplatform_notify(uint32_tvector_id){ env_lock_mutex(platform_lock); R_IPC_MessageSend(&g_ipc1_ctrl, (uint32_t)(RL_GET_Q_ID(vector_id))); env_unlock_mutex(platform_lock);}
注意:
補充一點,為了方便多核心間的通信,這里的virtualqueue默認都是配置為兩個,并且雙核間的收發virtualqueue都是分別一一對應的:
Master Remotevqx[0]:tx_vq -> rx_vqvqx[0]:rx_vq -> tx_vq
2) 發送數據
首先來看下 rpmsg-lite 的發送數據API:
int32_trpmsg_lite_send(structrpmsg_lite_instance *rpmsg_lite_dev, structrpmsg_lite_endpoint *ept, uint32_tdst, char*data, uint32_tsize, uintptr_ttimeout)
這里的data是我們傳輸過來的數據,那么后面就是這么幾個步驟:
# 1.從共享內存申請buffer(vq_tx_master)buffer = rpmsg_lite_dev->vq_ops->vq_tx_alloc(rpmsg_lite_dev->tvq, &buff_len, &idx);# 2.將共享地址傳遞給rpmsg_msg,并對該變量傳遞實際數據rpmsg_msg = (structrpmsg_std_msg *)buffer;env_memcpy(rpmsg_msg->data, data, size);# 3.將前面申請的這段buffer標記為可用模式,并加入到vq_ring.avail中,一般這里應該是用于緩存下的多核通信/* Enqueue buffer on virtqueue. */rpmsg_lite_dev->vq_ops->vq_tx(rpmsg_lite_dev->tvq, buffer, buff_len, idx);
那么到這里,我們想要傳遞的數據就已經放進去 virtualqueue了,那么接下來就是再發送一個通知給另外一個核心,通知它從共享隊列中讀取數據。對應的流程如下:
>>> rpmsg_lite_send -> rpmsg_lite_format_message -> virtqueue_kick -> vq_ring_notify_host -> virtqueue_notify -> platform_notify
3) 接收數據
首先明確接收數據的api,在RTOS下我們使用的是 rpmsg_queue_recv():
int32_trpmsg_queue_recv(structrpmsg_lite_instance *rpmsg_lite_dev, rpmsg_queue_handle q, uint32_t*src, char*data, uint32_tmaxlen, uint32_t*len, uintptr_ttimeout)
深入進去就是需要從消息隊列中拿出數據
可以觀察上圖中紅色箭頭所指示的流程,在接收到來自另一個核心的IPC通知后,會觸發進入 env_isr:
voidg_ipc0_callback(ipc_callback_args_t *p_args){ rt_interrupt_enter(); /* Check for message received event */ if(IPC_EVENT_MESSAGE_RECEIVED & p_args->event) { env_isr(p_args->message); } rt_interrupt_leave();}
此處會告知本核心的virtualqueue,并觸發對應的回調函數(接收為rpmsg_lite_rx_callback),在這個回調函數中,會執行到一個 ept->rx_cb,這里也就是我們在初始化rpmsg-lite時綁定的endpoint回調函數,即 rpmsg_queue_rx_cb:
my_ept =rpmsg_lite_create_ept(my_rpmsg, LOCAL_EPT_ADDR, rpmsg_queue_rx_cb, my_queue);int32_trpmsg_queue_rx_cb(void*payload,uint32_tpayload_len,uint32_tsrc,void*priv){ rpmsg_queue_rx_cb_data_tmsg; RL_ASSERT(priv != RL_NULL); msg.data = payload; msg.len = payload_len; msg.src = src; /* if message is successfully added into queue then hold rpmsg buffer */ if(0!=env_put_queue(priv, &msg,0)) { /* hold the rx buffer */ returnRL_HOLD; } returnRL_RELEASE;}
接著就是激活 rpmsg-lite 的消息隊列線程,進而去處理消息。
6 rpmsg-lite通信流程(MCMGR)
MCMGR組件開源地址:https://github.com/nxp-mcuxpresso/mcux-mcmgr
1)mcmgr雙核間同步
# M85# 首先注冊一個event回調函數,實時檢測來自次核的通知,也就是 APP_RPMSG_READY_EVENT_DATA 和 APP_RPMSG_EP_READY_EVENT_DATA事件staticvoidRPMsgRemoteReadyEventHandler(uint16_t eventData,void*context){ uint16_t *data = (uint16_t *)context; *data = eventData;}/* Register the application event before starting the secondary core */ (void)MCMGR_RegisterEvent(kMCMGR_RemoteApplicationEvent, RPMsgRemoteReadyEventHandler, (void*)&RPMsgRemoteReadyEventData); while(APP_RPMSG_READY_EVENT_DATA != RPMsgRemoteReadyEventData) { }; /* Wait until the secondary core application signals the rpmsg remote endpoint has been created. */ while(APP_RPMSG_EP_READY_EVENT_DATA != RPMsgRemoteReadyEventData) { }--------------------------------------------------------------------------------------------------------------------------------# M33# 通過MCMGR_TriggerEvent觸發IPC中斷,發送通知給主核 /* Signal the other core we are ready by triggering the event and passing the APP_RPMSG_READY_EVENT_DATA */ (void)MCMGR_TriggerEvent(kMCMGR_RemoteApplicationEvent, APP_RPMSG_READY_EVENT_DATA); /* Signal the other core the endpoint has been created by triggering the event and passing the * APP_RPMSG_READY_EP_EVENT_DATA */ (void)MCMGR_TriggerEvent(kMCMGR_RemoteApplicationEvent, APP_RPMSG_EP_READY_EVENT_DATA);
2)mcmgr雙核間通信
<1>接收
接收邏輯關鍵取決于下面這個API:
structrpmsg_lite_endpoint*rpmsg_lite_create_ept(structrpmsg_lite_instance *rpmsg_lite_dev, uint32_taddr, rl_ept_rx_cb_trx_cb, void*rx_cb_data, structrpmsg_lite_ept_static_context *ept_context)
通過綁定的回調函數rx_cb,再由mcmgr多核管理器統一注冊事件,并根據平臺層提供的platform_notify機制觸發env_isr,并觸發到mcmgr_ipc_callback
來執行接收回調rx_cb,而這個觸發由rpmsg_lite_send提供觸發動作(virtqueue_kick)
# 示例代碼staticint32_tmy_ept_read_cb(void*payload,uint32_tpayload_len,uint32_tsrc,void*priv){ int32_t*has_received = priv; if(payload_len <=?sizeof(THE_MESSAGE))? ? {? ? ? ? (void)rt_memcpy((void?*)&msg, payload, payload_len);? ? ? ? *has_received =?1;? ? }? ? (void)rt_kprintf("Primary core received a msg\r\n");? ? (void)rt_kprintf("Message: Size=%x, DATA = %i\r\n", payload_len, msg.DATA);? ? return?RL_RELEASE;}my_ept =?rpmsg_lite_create_ept(my_rpmsg, LOCAL_EPT_ADDR, my_ept_read_cb, (void?*)&has_received, &my_ept_context);
所以流程為:
mcmgr_ipc_callback ->mcmgr_event_handler ->env_isr ->virtqueue_notification ->rpmsg_lite_rx_callback(vq->callback_fc) ->my_ept_read_cb(ept->rx_cb)
<2>發送
發送邏輯關鍵取決于下面這個API:
int32_trpmsg_lite_send(structrpmsg_lite_instance *rpmsg_lite_dev, structrpmsg_lite_endpoint *ept, uint32_tdst, char*data, uint32_tsize, uintptr_ttimeout)
流程為
(void)rpmsg_lite_send(my_rpmsg, my_ept, REMOTE_EPT_ADDR, (char*)&msg,sizeof(THE_MESSAGE), RL_DONT_BLOCK);returnrpmsg_lite_format_message(rpmsg_lite_dev, ept->addr, dst, data, size, RL_NO_FLAGS, timeout);# 這里的data是我們傳輸過來的數據,那么后面就是這么幾個步驟:# 1.從共享內存申請buffer(vq_tx_master)buffer = rpmsg_lite_dev->vq_ops->vq_tx_alloc(rpmsg_lite_dev->tvq, &buff_len, &idx);# 2.將共享地址傳遞給rpmsg_msg,并對該變量傳遞實際數據rpmsg_msg = (structrpmsg_std_msg *)buffer;env_memcpy(rpmsg_msg->data, data, size);# 3.將前面申請的這段buffer標記為可用模式,并加入到vq_ring.avail中,一般這里應該是用于緩存下的多核通信/* Enqueue buffer on virtqueue. */rpmsg_lite_dev->vq_ops->vq_tx(rpmsg_lite_dev->tvq, buffer, buff_len, idx);# 最后執行通知機制virtqueue_kick ->vq_ring_notify_host(vq->notify_fc(vq)) ->platform_nofity -> (void)MCMGR_TriggerEventForce(kMCMGR_RemoteRPMsgEvent, (uint16_t)RL_GET_Q_ID(vector_id)); ->trig ipc callback ->mcmgr_ipc_callback
RT-Thread Github 開源倉庫,歡迎撒個星(Star)支持,更期待你的代碼貢獻:https://github.com/RT-Thread/rt-thread
獲取硬件
RT-Thread 與瑞薩電子聯合推出 RA8P1 Titan Board,基于 1GHz Arm Cortex-M85 + 250MHz Cortex-M33 雙核架構,集成 Ethos-U55 NPU ,實現 256 GOPS 的 AI 性能、超過 7300 CoreMarks 的突破性 CPU 性能和先進的人工智能 (AI) 功能,可支持語音、視覺和實時分析 AI 場景!
-
通信
+關注
關注
18文章
6405瀏覽量
140101 -
異構
+關注
關注
0文章
47瀏覽量
13552 -
RT-Thread
+關注
關注
32文章
1620瀏覽量
44956
發布評論請先 登錄
多核異構通信框架(RPMsg-Lite)

RT-Thread Vector軟件包:嵌入式開發的動態數組容器 | 技術集結
JH-7110現已支持AMP雙系統(Linux + RT-Thread)
【米爾NXP i.MX 93開發板試用評測】1、異構核心通信的技術內容
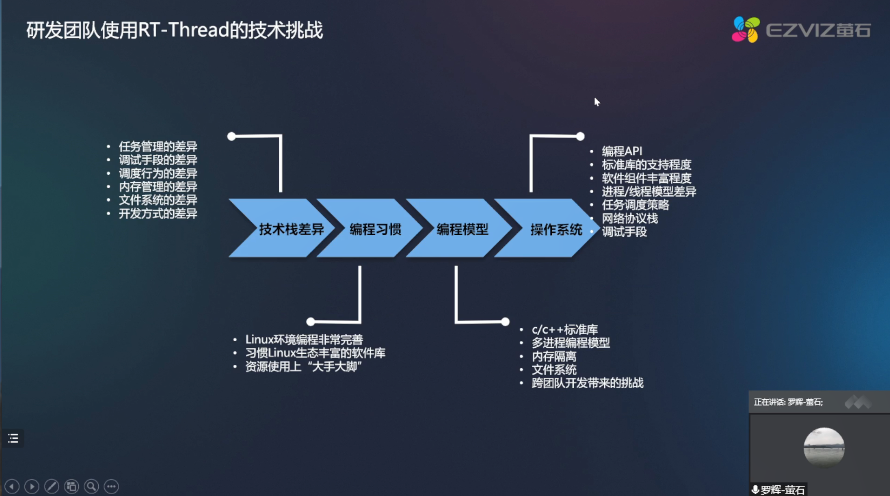
RT-Thread全球技術大會:螢石研發團隊使用RT-Thread的技術挑戰
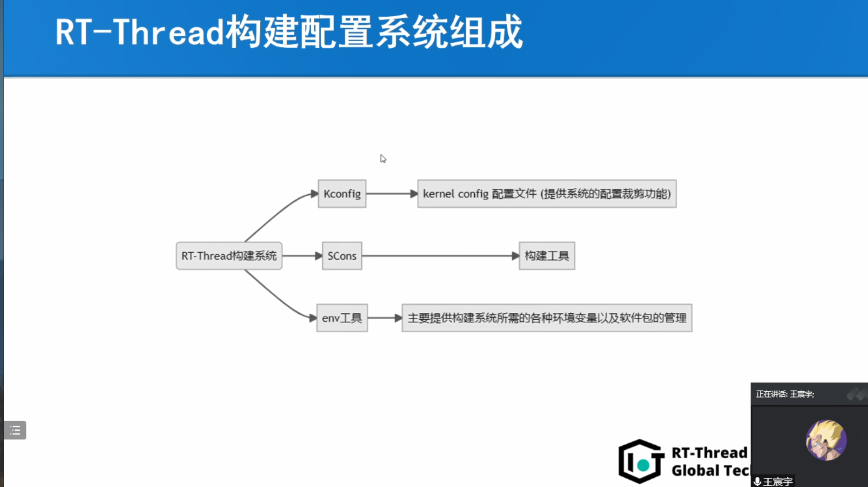
RT-Thread全球技術大會:Kconfig在RT-Thread中的工作機制
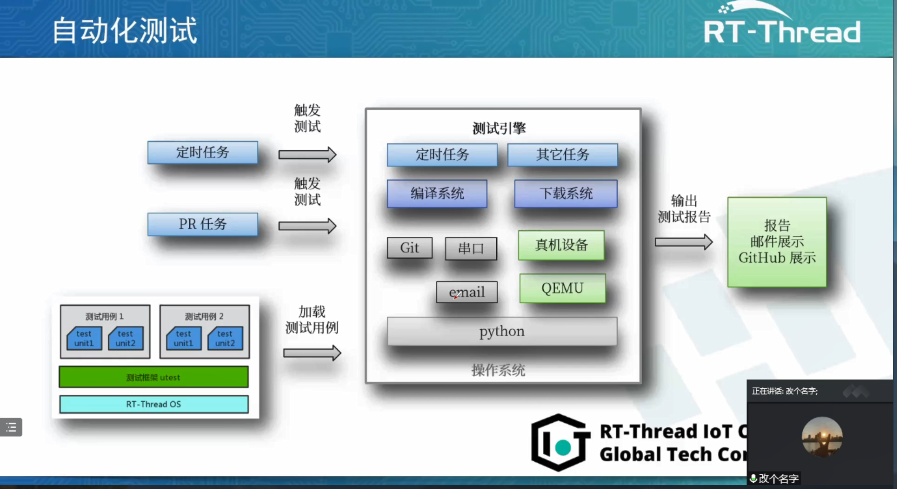
RT-Thread全球技術大會:在RT-Thread上編寫測試用例

RT-Thread全球技術大會:RT-Thread測試用例集合案例
RT-Thread全球技術大會:RT-Thread對POSIX的實現情況介紹


基于rt-thread的socket通信設計
YY3568多核異構(Linux+RT-Thread)--啟動流程

RT-Thread 巡回培訓終極場次11月1日登陸深圳、上海、成都 | 活動速遞




 工商網監
工商網監
評論