") 【原理到實戰(zhàn)】實驗異質(zhì)性分析
【原理到實戰(zhàn)】實驗異質(zhì)性分析

什么是實驗的異質(zhì)性
1. 如何理解實驗結(jié)果中的指標(biāo)變化
當(dāng)我們看到如下試金石實驗指標(biāo)結(jié)果時
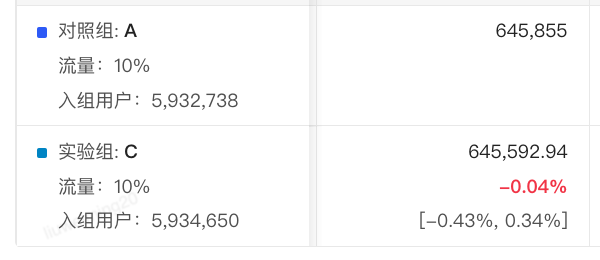
在進行分析前,可能我們的第一直覺是這樣的

經(jīng)過異質(zhì)性分析后,可能會發(fā)現(xiàn)實際情況是這樣的
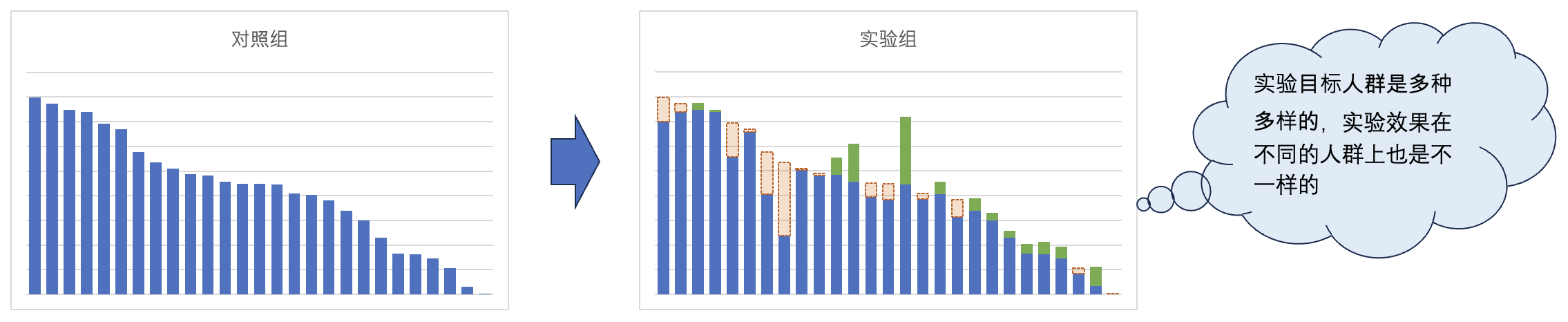
2. 概念解析與定義
實驗的異質(zhì)性,一般被稱為HTE(即Heterogeneous Treatment Effects),意為實驗中同一個treatment對不同的實驗樣本,得到的策略效果可能是不一樣的。另外還有一些重要的概念需要大家理解
| 英文簡稱 | 英文全稱 | 中文譯名 | 含義 | 公式 |
|---|---|---|---|---|
| ATE | Average Treatment Effect | 平均處理效應(yīng) | 所有實驗對象的平均實驗效果 | ATE=E[Y(1)?Y(0)]ATE=E[Y(1)?Y(0)] |
| CATE | Conditional Average Treatment Effect | 條件平均處理效應(yīng) | 滿足一定條件的實驗對象的平均實驗效果 | CATEX=E[Yx(1)?Yx(0)∣x∈X]CATEX?=E[Yx?(1)?Yx?(0)∣x∈X] |
| ITE | Individual Treatment Effect | 個體處理效應(yīng) | 某個實驗對象的實驗效果 | ITEi=E[Yi(1)?Yi(0)],i=1,2,...NITEi?=E[Yi?(1)?Yi?(0)],i=1,2,...N |
* 此處采用Donald Rubin提出的潛在因果框架(Potencial outcome)來對實驗效果進行統(tǒng)計公式上的描述 [1]
* 由于業(yè)內(nèi)并沒有統(tǒng)一的定義,HTE、CATE、ITE概念在一定程度上會有混用的情況,讀者需要參考描述以及上下文綜合判斷名詞的含義
3. 異質(zhì)性分析對于業(yè)務(wù)的意義
1.了解策略對于不同用戶的不同效果,協(xié)助挖掘背后的業(yè)務(wù)邏輯,輔助迭代、進行新一輪的實驗
2.嘗試尋找策略最優(yōu)子人群,讓整體無效的策略,有機會進行部分先推全;反之依然,讓部分負向的策略,減少損失
3.對實驗結(jié)果建模后預(yù)測,對線上提供動態(tài)的最優(yōu)人群支持
根據(jù)試金石測算,以某產(chǎn)品線下6月運行中的35個實驗為例,僅23%左右的實驗沒有在實驗人群視角發(fā)現(xiàn)異質(zhì)性
異質(zhì)性分析方法概述
1. 異質(zhì)性分析的維度選擇
1. 對于分流單元的維度X,當(dāng)X滿足以下條件時,可以作為異質(zhì)性的維度進行后續(xù)分析
??
T⊥XT⊥X
?,即分析維度與實驗分流無關(guān) (Unconfoundedness)
?分析工具化的常見簡化方式:對于一個分流ID,選取他在首次進入實驗前一天的標(biāo)簽取值
?簡單推導(dǎo):

T是隨機化的,
T⊥Y,T⊥XT⊥Y,T⊥X
,所以
E[Yi(1)∣x∈X]=E[Yi(1)|Ti=1,x∈X]E[Yi?(1)∣x∈X]=E[Yi?(1)|Ti?=1,x∈X]
,所以(3)成立
2. 異質(zhì)性分析的維度分析bad case舉例
假設(shè)我們需要分析的實驗策略為:根據(jù)用戶的活躍度標(biāo)簽,低、中、高頻用戶的優(yōu)惠券策略分別做了新/老策略迭代
| 分析目標(biāo) & 常見錯誤方法舉例 | 不成立原因簡述 | 推薦的實驗分析方式 |
|---|---|---|
| 不同活躍度人群的策略效果 在實驗運行7天后,利用實驗用戶在第7天的活躍度標(biāo)簽進行結(jié)果拆解 | 在實驗開始后,用戶的活躍度標(biāo)簽受到了策略影響,即T⊥X不成立 | 使用用戶在進入實驗前1天的活躍度標(biāo)簽值 |
| 分別分析低頻策略、中頻策略、高頻策略對于低、中、高頻用戶的策略效果 按天取每天用戶的活躍度標(biāo)簽,對實驗結(jié)果進行拆解 | 用戶的活躍度標(biāo)簽受到了策略影響,即T⊥X不成立 ·用戶所在分組應(yīng)該是確定的,不隨時間改變 | 分別建立3個人群正交實驗 |
| 分析高單價類目商品(3C家電)和低單價類目商品(休閑食品)的轉(zhuǎn)化率差異 選取xx類目曝光用戶,計算實驗周期內(nèi)對應(yīng)類目的曝光訂單轉(zhuǎn)化率 | 分析目標(biāo)是面向指標(biāo)維度的(sku所在類目),而非分流單元的維度(C端實驗通常為賬號、設(shè)備),不適用本文提到的異質(zhì)性分析方法 | 試金石現(xiàn)已支持指標(biāo)維度下鉆 曝光訂單轉(zhuǎn)化率的分子、分母均受到策略影響,需在觀測全面后綜合判斷 |
2. 異質(zhì)性分析的方法選擇
| 研究對象 | 研究方法 | 適用場景 | pros & cons |
|---|---|---|---|
| CATE | 維度下鉆 | ·低維 ·分析目標(biāo)明確 | + 快速簡單,便于理解 + 產(chǎn)品化容易 - 維度選擇依賴分析師經(jīng)驗 - 交互效應(yīng)處理困難 |
| 方差分析(ANOVA,ANCOVA) | ·低維 ·分析目標(biāo)較明確 ·交互效應(yīng)評估 | + 解釋性強,統(tǒng)計學(xué)理論背書 + 可以處理低維度交互效應(yīng) + 可作為feature selection的候選方法 - 基于線性模型假設(shè) - 高維度交互效應(yīng)解讀困難 | |
| 因果樹(Causal Tree) | ·高維 ·分析目標(biāo)不明確,希望探索 | + 建模方法符合分析直覺 - 模型復(fù)雜度不足,無法準(zhǔn)確描述復(fù)雜的現(xiàn)實世界效果 - 本方法為現(xiàn)代機器學(xué)習(xí)因果算法的基石之一,有更好的替代方案 | |
| ITE | Meta - Learner | ·高維 ·希望輸出ITE ·算法訓(xùn)練 | + 算法常用,可大規(guī)模并行,有工程化先例 + 在過往的simulation中X-learner對ITE估計的準(zhǔn)確度表現(xiàn)優(yōu)秀 + X-learner通常使用xgboost模型,對各種feature有較強的處理能力 - 計算量大,耗資源 - 需要調(diào)參 - 由于缺乏統(tǒng)計推斷結(jié)果,一般不會直接產(chǎn)出p-value,存在對于ITE數(shù)值準(zhǔn)確性的質(zhì)疑,算法利用結(jié)果的rank居多 |
| DML | ·高維 ·希望輸出ITE和置信區(qū)間 | + 有嚴謹統(tǒng)計理論證明ITE估計的無偏有效性,可產(chǎn)出樣本級的ITE以及置信區(qū)間 + 在過往的simulation中Causal Forest DML對ITE估計的準(zhǔn)確度表現(xiàn)優(yōu)秀 + DML模型框架本身具備一定的robust特性,在結(jié)合Forest模型后,調(diào)參需求低,不容易過擬合,對各種feature有較強的處理能力 - 慢,耗資源,工程化先例少 | |
| ITE + CATE hybrid | ITE Model + Decision Tree Interpreter | ·高維 ·分析目標(biāo)不明確,希望探索 | + 決策樹的建模方法符合分析直覺 + ITE模型可以較好的對復(fù)雜的現(xiàn)實世界進行抽象總結(jié) - ITE模型可能會慢 |
* CATE、ITE建模方法的細節(jié)可參考Appendix
CATE下鉆探索工具MVP版邏輯介紹
項目地址:http://xingyun.jd.com/codingRoot/abtest_ds/CATE_model?
模型邏輯:多維度的維度下鉆 + Decision Tree Interpreter
快速開始:
from CATE_model.utils.workflow import CateWorkFlow yaml_path = 'config.yaml' # 按分析要求配置YAML文件 cate_workflow = CateWorkFlow(yaml_path) # 初始化CATE對象 cate_workflow.prepare_analysis() # 初始化ABTestAnalyzer cate_workflow.execute_cate_auto() # 自動執(zhí)行所有環(huán)節(jié) cate_workflow.df_out.styler # 輸出CATE差異最大子人群目標(biāo)指標(biāo)統(tǒng)計
項目基本流程
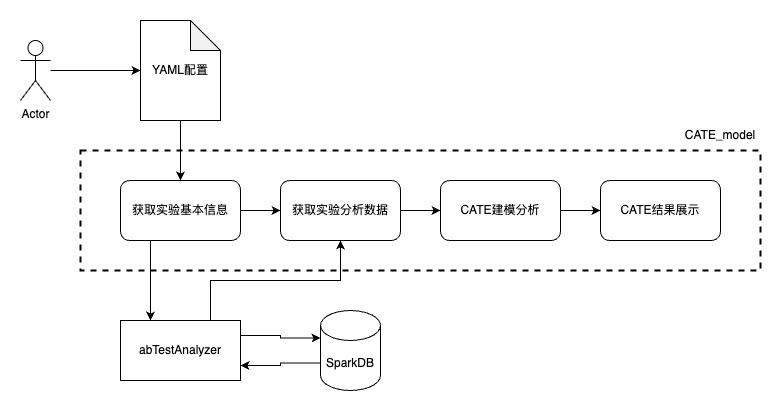
YAML配置方法:第一次可以先根據(jù)項目demo修改,并參考YAML配置說明.md?
項目MVP功能說明
1.通過填寫YAML配置,自動生成實驗分析SQL,并執(zhí)行取數(shù),目前包括
?自動獲取試金石實驗分流信息
?自動獲取試金石實驗指標(biāo)信息
?解析實驗CATE研究使用的用戶標(biāo)簽表
?自動生成所有數(shù)據(jù)源的關(guān)聯(lián)關(guān)系
2.為實驗CATE研究提供自動化工具,目前包括
?自動化生成實驗?zāi)繕?biāo)指標(biāo)的CATE差異最大化子人群
?提供調(diào)參接口,高級用戶可自定義模型參數(shù)
?提供可視化的模型結(jié)果輸出,高級用戶可根據(jù)輸出調(diào)節(jié)模型表現(xiàn)
3.為實驗的下鉆分析提供探索、分析功能,目前包括
?CATE人群的實驗效果統(tǒng)計檢驗
?CATE人群的多指標(biāo)拆解
?CATE人群的特征描述
?
實驗異質(zhì)性分析show case
針對近期某頻道重點改版實驗,此項目整體實驗指標(biāo)為負向不顯著,但通過運行分析工具后發(fā)現(xiàn),有兩類子人群分別具有正向和負向的顯著效果
| 實驗HTE人群統(tǒng)計 |
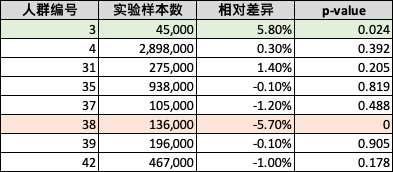 |
?
對于這些子人群,我們發(fā)現(xiàn)他們在業(yè)務(wù)漏斗上的變化并不一樣,那么下次對于頻道進行迭代時,產(chǎn)品經(jīng)理可以整理有針對性的選擇對負向人群進行針對性的優(yōu)化
| 人群編號 | 用戶畫像總結(jié) | 頻道uv | 點擊uv | 加車uv | 轉(zhuǎn)化訂單數(shù) |
|---|---|---|---|---|---|
| 3 | 年輕人,低活躍 | 1.0% | 2.2% | 2.6% | 5.8% |
| 38 | 非年輕人,高線城市,plus用戶 | -2.2% | -2.2% | -3.1% | -5.7% |
?
未來展望
1.自定義分流表
2.自定義畫像表 & 經(jīng)海路畫像表
3.CATE模型迭代
4.通用維度配置模版 & 業(yè)務(wù)場景模版
5.圖形化交互界面,簡化輸入配置
Appendix & 參考資料
【1】因果分析框架 & Donald Rubin的Potencial Outcome
?Potencial Outcome
?設(shè)
TiTi?
?代表第i個樣本是否收到了處理(treatment,策略影響),是為1,否為0
??
YiYi?
?代表個體i的結(jié)果,另外記
{Yi(1),Yi(0)}{Yi?(1),Yi?(0)}
?為個體i接受處理、對照的潛在結(jié)果
?每個個體通常只會有1個狀態(tài),個體因果作用無法直接觀測,我們只有
Yi=Ti?Yi(1)+(1?Ti)?Yi(0)Yi?=Ti??Yi?(1)+(1?Ti?)?Yi?(0)
?在隨機化實驗的場景下,我們可以得到
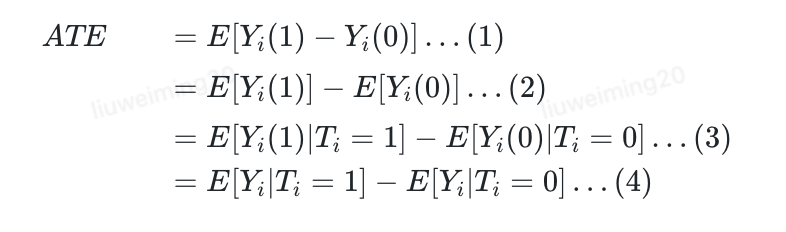
其中最重要的邏輯為:
T是隨機化的,
T⊥YT⊥Y
,所以
E[Yi(1)]=E[Yi(1)|Ti=1]E[Yi?(1)]=E[Yi?(1)|Ti?=1]
,所以(3)成立
?因果推斷(一):因果推斷兩大框架及因果效應(yīng):https://zhuanlan.zhihu.com/p/652174282?
?因果推斷簡介之二:Rubin Causal Model (RCM) 和隨機化試驗:https://cosx.org/2012/03/causality2-rcm/?
?
【2】ANOVA與CATE的交互效應(yīng)分析
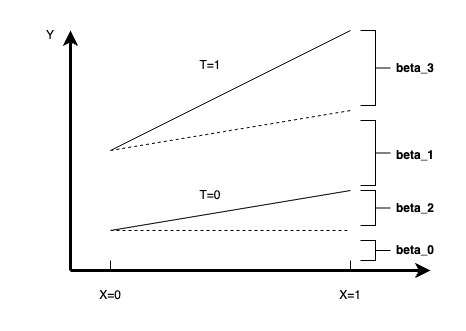
當(dāng)需要進行異質(zhì)性分析的維度為X時,我們可以通過構(gòu)建下列回歸方程去描述X在實驗中是否存在顯著的異質(zhì)性,當(dāng)
β3β3?
對應(yīng)的F-test顯著時,我們就可以認為實驗在維度X上存在顯著的異質(zhì)性
Y=β0+β1?T+β2?X+β3?X?TY=β0?+β1??T+β2??X+β3??X?T
當(dāng)
X∈{0,1}X∈{0,1}
時,我們可以用下圖來進行異質(zhì)性的理解
【3】CATE & ITE估計
idea1:對于每個參與實驗的對象i,如果能得到
Yi(1)Yi?(1)
?和
Yi(0)Yi?(0)
?的合理估計,那么ITE就可求了 idea2:對于實驗人群X,如果能找到一種觀測方式,求得
E[Yx(1)?Yx(0)∣x∈X]E[Yx?(1)?Yx?(0)∣x∈X]
?,那么CATE就有了
?Meta Learner的極簡介紹
?S-Learner
?stage1: 利用模型估計
μ(x,t)=E[Y∣X=x,T=t]μ(x,t)=E[Y∣X=x,T=t]
?stage2: 定義CATE結(jié)果如下
τ^(x)=μ^(x,T=1)?μ^(x,T=0)τ^(x)=μ^?(x,T=1)?μ^?(x,T=0)
?T-Learner
?stage1: 利用兩個模型,分別估計
μ0(x)=E[Y(0)∣X=x]μ0?(x)=E[Y(0)∣X=x]
μ1(x)=E[Y(1)∣X=x]μ1?(x)=E[Y(1)∣X=x]
?stage2: 定義CATE結(jié)果如下
τ^(x)=μ1^(x)?μ0^(x)τ^(x)=μ1?^?(x)?μ0?^?(x)
?X-Learner
?stage1:利用兩個模型,分別估計
μ0(x)=E[Y(0)∣X=x]μ0?(x)=E[Y(0)∣X=x]
μ1(x)=E[Y(1)∣X=x]μ1?(x)=E[Y(1)∣X=x]
?stage2:實驗組、對照組數(shù)據(jù)交叉擬合構(gòu)造
Di1=Yi1?μ0^(Xi1),τ1(x)=E[D1∣X=x]Di1?=Yi1??μ0?^?(Xi1?),τ1?(x)=E[D1∣X=x]
Di0=μ1^(Xi0)?Yi0,τ0(x)=E[D0∣X=x]Di0?=μ1?^?(Xi0?)?Yi0?,τ0?(x)=E[D0∣X=x]
?stage3:定義CATE為模型估計值的加權(quán)平均,權(quán)重來自于在condition x下實驗組、對照組的樣本比例
τ(x)=g(x)τ0(x)+(1?g(x))τ1(x)τ(x)=g(x)τ0?(x)+(1?g(x))τ1?(x)
?更多資料參考uber的causalML項目:https://causalml.readthedocs.io/en/latest/methodology.html?
?Causal Forest的極簡介紹
?如果將普通決策樹算法的葉子分裂準(zhǔn)則從最小化整體
Y^Y^
?的MSE,替換為最大化葉子結(jié)點的CATE差異,那么根據(jù)貪心算法,我們可以得到一個拆解CATE的Causal Tree(還有很多保證樣本平衡、估計可靠的weighting和honest的方法細節(jié)沒有介紹)
?為了克服一棵樹帶來的high variance,仿照random forest,構(gòu)建由Causal Tree組成的森林,并且我們可以通過觀察在不同樹中樣本是否被多次劃入一個葉子結(jié)點來調(diào)節(jié)本樣本對當(dāng)前葉子估計的權(quán)重,最終得道一個可以產(chǎn)出ITE估計的森林模型
?DML的極簡介紹
?我們定義
θ(x)θ(x)
?為CATE,那么構(gòu)建下列函數(shù)
Y=θ(x)?T+g(X)+?,E[?∣T,X]=0Y=θ(x)?T+g(X)+?,E[?∣T,X]=0
T=f(X)+η,E[η,X]=0T=f(X)+η,E[η,X]=0
?stage1: 擬合g、f函數(shù),求得殘差
ω=Y?E[Y∣X]ω=Y?E[Y∣X]
υ=T?E[T∣X]υ=T?E[T∣X]
?stage2: 擬合殘差,求得CATE估計
ω=θ(x)?υ+?ω=θ(x)?υ+?
?如果我們將上述double ML的過程用GMM的方式寫成矩函數(shù),
E[((Y?E[Y∣X])?(T?E[T∣X])θ(x))(T?E[T∣X])]=0E[((Y?E[Y∣X])?(T?E[T∣X])θ(x))(T?E[T∣X])]=0
那么根據(jù)Neyman orthogonality condition,我們可以證明此過程估計的
θ(x)θ(x)
在大樣本下具備無偏一致性,此特性與
ω,υω,υ
在一定程度上沒有關(guān)系
?關(guān)于doubly robust,R-learner,CausalForestDML等方法呢?是否有理論框架能總結(jié)這一類利用殘差進行推斷的方法呢?參考:Orthogonal Statistical Learning Arxiv:1901.09036V3
?更多關(guān)于DML、CausalForest資料請參考微軟的EconML項目:https://www.pywhy.org/EconML/spec/overview.html
審核編輯 黃宇
-
YAML
+關(guān)注
關(guān)注
0文章
22瀏覽量
2616
發(fā)布評論請先 登錄
芯粒設(shè)計與異質(zhì)集成封裝方法介紹

RK平臺Linux IOMMU開發(fā):從原理到實戰(zhàn)
實驗性光纜有哪些應(yīng)用場景
矢量網(wǎng)絡(luò)分析儀校準(zhǔn)全解析:從原理到實戰(zhàn)的精準(zhǔn)測量指南

雙向保護開關(guān)評估套件使用指南:從原理到實戰(zhàn)
肖克利 | 極端環(huán)境測試,讓驗證與實戰(zhàn)同頻!

醫(yī)療電子EMC整改:原理到實戰(zhàn)的系統(tǒng)化全攻略策略
迅為iTOP-3568開發(fā)板?Linux驅(qū)動開發(fā)實戰(zhàn):menuconfig圖形化配置實驗

SAW 濾波器從原理到測量:一套可復(fù)用的實驗室實戰(zhàn)流程

大功率電磁兼容整改:技術(shù)原理到實戰(zhàn)策略的系統(tǒng)化方案
從原理到實操:BLE藍牙配網(wǎng)(STA+SoftAP雙模式)一文通關(guān)!

數(shù)據(jù)庫慢查詢分析與SQL優(yōu)化實戰(zhàn)技巧
泰克TBS1052C示波器從基礎(chǔ)波形捕獲到FFT頻譜分析實戰(zhàn)
電機微機控制系統(tǒng)可靠性分析
UC3854 功率因數(shù)校正設(shè)計全攻略:從理論到實戰(zhàn)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論