 沐曦助力上海創智學院siiRL 2.0全面升級
沐曦助力上海創智學院siiRL 2.0全面升級

在人工智能加速邁向大模型與智能體時代的今天,強化學習(Reinforcement Learning,RL)已經成為推動智能系統演化的關鍵技術。隨著強化學習訓練規模不斷擴大,對底層算力提出了前所未有的挑戰。近日,上海創智學院 AI Infra 團隊發布的 siiRL 2.0,以其卓越特性為強化學習的發展帶來了新的突破,沐曦則憑借自身優勢為 siiRL 2.0 的升級提供了堅實支撐,共同推動強化學習正式邁入 “千卡級”時代。
siiRL:全分布式架構的顛覆性突破
上海創智學院AI Infra團隊發布siiRL 2.0,聚焦性能、生態與前沿探索全面升級:
卓越性能與擴展性
基于全分布式架構,實現千卡級近線性擴展與業界領先吞吐,性能在7B~235B(Dense/MoE)等大規模模型上穩定驗證。
自主可控,擁抱國產算力
全面適配多家主流國產芯片并完成千卡級擴展驗證,為AI基礎設施夯實自主可控的算力底座。
靈活易用與生態兼容
獨創DAG工作流支持無代碼算法實驗,兼容Megatron/FSDP等主流后端,極大提升研發效率。
面向前沿,支持多智能體研究
內建強大的多智能體協同訓練框架,為探索“智能涌現”等前沿課題提供關鍵基礎設施。
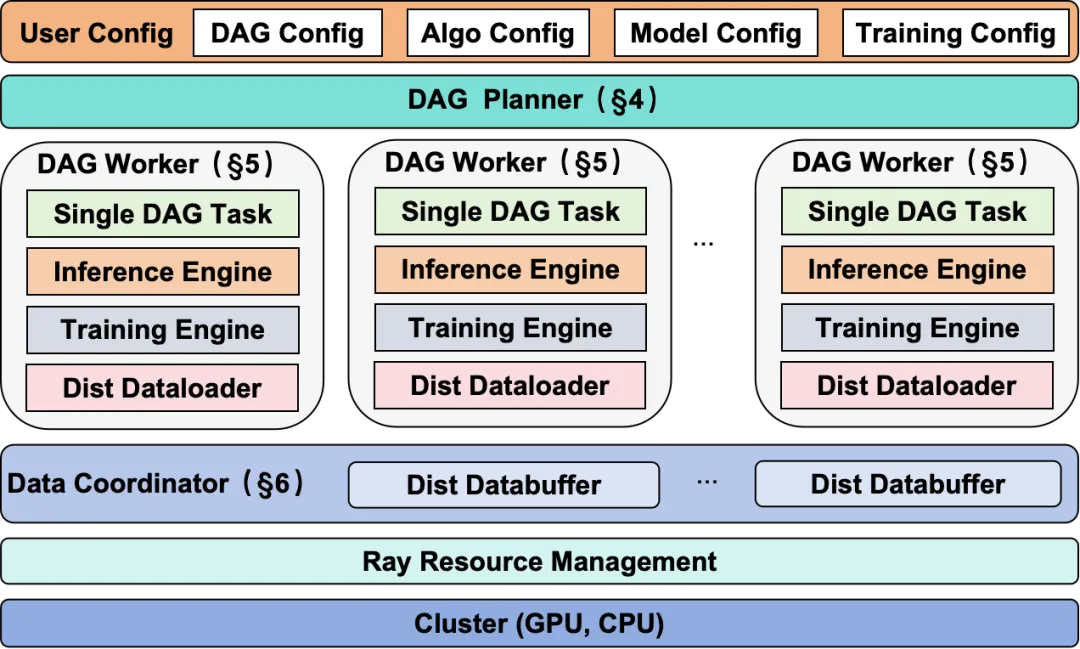
圖 1:siiRL架構概覽
技術論文:https://arxiv.org/abs/2507.13833
開源代碼倉庫:https://github.com/sii-research/siiRL
在本次siiRL的升級適配工作中,沐曦做了一系列針對性優化:
siiRL框架高效適配
基于沐曦自研的MXMACA軟件棧,已經完整適配了siiRL需要的所有后端引擎(Vllm/Pytorch fsdp/Megatron-LM/Ray)以及深度優化的mccl高性能通信庫,不需要其他額外的適配工作,實現了siiRL框架的高效適配。
超節點scale up
沐曦Dragonfly超節點,提供了64卡的光互連高速通信帶寬。在訓練過程中,通過設置fsdp_size=64,可以充分利用超節點內的帶寬,提升模型的訓練效率。
顯存優化
通過設置模型參數offload選項,在共置集群上,有效降低了rollout和training階段的峰值顯存,可以采用更優的切分方式,進一步提升計算效率。
分布式策略調整
結合實際負載與硬件拓撲,優化了不同模型的分布式訓練參數切分方式,并調整了親和性配置,以提升通信效率。
通過上述優化,siiRL框架在沐曦超節點集群上實現了從64卡到1024卡的穩定擴展,系統保持了超過92%的高線性度拓展效率。在模型精度上,與國際主流生態 GPU的訓練結果相比,沐曦超節點集群在驗證集上的平均絕對誤差控制在0.5%以內,滿足實際應用場景的精度要求。

圖 2:siiRL在沐曦超節點集群上的擴展性評估,
展示了64卡到1024GPU規模下的高線性擴展能力
隨著 AI 技術逐漸成為國家科技競爭的核心,構建自主可控的算力基礎設施已經成為產業發展的必然選擇。沐曦與上海創智學院 AI Infra 團隊的攜手合作,不僅驗證了國產 GPU 在前沿 AI 應用上的可行性與先進性,更為中國科研機構、產業界提供了面向未來的堅實算力底座。沐曦將持續與產學研伙伴深度協作,推動大模型框架與國產 GPU 的深度適配和生態完善,加速強化學習、大模型、智能體等關鍵領域的創新應用落地。
關于沐曦
沐曦致力于自主研發全棧高性能GPU芯片及計算平臺,為智算、通用計算、云渲染等前沿領域提供高能效、高通用性的算力支撐,助力數字經濟發展。
-
gpu
+關注
關注
28文章
5194瀏覽量
135443 -
沐曦
+關注
關注
1文章
80瀏覽量
1811 -
大模型
+關注
關注
2文章
3650瀏覽量
5183
原文標題:強化學習進入“千卡級”時代,沐曦助力 siiRL 2.0 全面升級
文章出處:【微信號:沐曦MetaX,微信公眾號:沐曦MetaX】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
沐曦曦云C500/C550 GPU產品深度適配MiniMax M2.5模型
沐曦股份CXO預科班2026冬令營圓滿收官
沐曦曦云C500/C550 GPU產品適配PaddleOCR-VL-1.5模型

沐曦股份與江南大學建立聯合研究中心
沐曦與Arm、熠知一同到訪清華大學交流座談
沐曦受邀出席第二屆開源產業生態大會
沐曦股份曦云C系列GPU Day 0適配智譜GLM-4.6V多模態大模型

DLInfer聯手沐曦股份實現數據生成場景的實際落地




 工商網監
工商網監
評論