 為什么把VLA直接放上自動駕駛汽車沒那么容易?
為什么把VLA直接放上自動駕駛汽車沒那么容易?

[首發于智駕最前沿微信公眾號]在自動駕駛領域,經常會有技術提出將VLA(視覺—語言—動作模型)應用到自動駕駛上。VLA的作用就是把看、懂、決策三件事交給一個大模型,攝像頭看到畫面,模型用“視覺+語言”去理解場景和意圖,最后直接輸出要不要轉向、踩剎車這樣的動作。這個模型的好處顯而易見,模型能用更豐富的語義理解來輔助決策,理論上更靈活、更接近“人怎么想就怎么做”的需求。但從實際落地和安全角度看,直接將自動駕駛汽車的行駛全部交給VLA,又有很多現實的難點和坑。
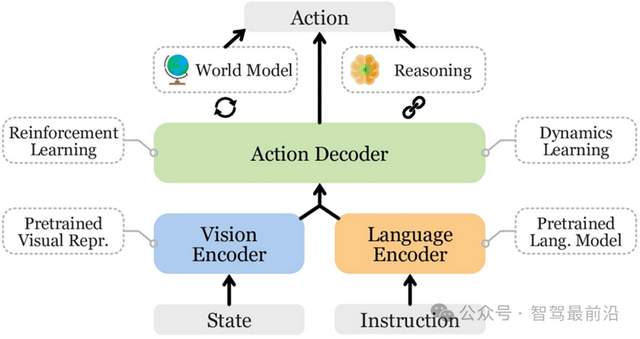
邊緣場景或將難以理解
大模型是靠大量數據學會“看”和“說”,但自動駕駛強調的是不能能“看”,更要能做對事。交通環境中常見的場景很容易被模型學會,但真正危險的往往是那些如臨時擺放的異物、非常規施工標識、突然沖出來的行人、凹陷或濕滑的路面、以及復雜的多車交互等不常見的極端情況。把這些長尾場景都采集齊全幾乎不可能,尤其是要配套高質量的動作標簽(也就是在那些場景下“應該怎么做”)更是難上加難。
對于邊緣場景,有些技術方案提出使用仿真幫忙補樣本,但仿真和真實世界總有差距。光照、材質、行人行為建模都很難完全擬合現實。有時在仿真里“得分高”的策略,也可能利用了仿真里的漏洞,如果這些策略到了真車上反而會危險。對于大模型學習還有一點不容忽視,用于訓練控制的標簽必須是物理可實現的。不是所有人為操作示例都適合直接當作監督信號;一些看起來“聰明”的人為反應其實依賴于人類的直覺和肉體補償(比如猛打方向時人的身體補償),模型直接模仿這些反而可能超出車輛動力學極限。
因此單靠堆數據和堆算力,無法把所有可能的危險都消滅掉。更可行的做法是把VLA用來補強語義理解和異常檢測,而不是把完全的控制權一次性托付給它。把它當成能給出“高層建議”的大腦,而由經過驗證的低級控制器來做最終執行,會安全得多。

能想出來不等于能做得到
語言模型擅長推理和生成,但車輛有明確的物理約束。一個優秀的駕駛“想法”可能需要的轉向角、加速度或車體傾斜等要求,有些在現實中可能根本實現不了。若不把這些物理約束強行嵌入到輸出環節,模型又有可能提出不可行或危險的軌跡。對于這類問題,要么在模型輸出端加上物理約束或后驗校正,要么把動作空間離散化讓模型只選“有限個可行動作”。前者可以保持流暢性但增加工程復雜度,后者雖然簡單但犧牲了自然和效率。
還有就是時序問題。自動駕駛的控制回路有嚴格的頻率和延遲要求。若模型在算力受限的車端運行太慢,或者把重要推理放在云端遇到網絡波動,決策就會基于舊畫面來執行,這反而會帶來駕駛風險。那種“決策滯后于現實”的情況,比決策錯誤還危險。很多常見的解決思路是“快思維+慢思維”架構,小而穩定的模型在車端做基礎感知和閉環控制,復雜的語義推理和策略優化放在后臺或云端,只在非關鍵時刻下提供建議。但這要求架構設計非常嚴謹,必須保證背景推理的結論不會在關鍵時刻破壞即時控制路徑。
訓練端到端系統常用的方法之一是強化學習或帶有獎勵的優化。若獎勵函數設計不當,模型可能學到在訓練或仿真中高分但現實里危險的策略。比如會利用某些規則漏洞快速完成任務,或者在仿真里靠冒險動作取勝。解決這類問題需要把安全約束顯式納入訓練目標,或采用混合監督(讓模型既學專家示范也學安全約束),還要在訓練里引入更多對抗和擾動場景。但這些措施會顯著抬高訓練成本和驗證復雜度。
其實對于模型來說,算力和成本也是需要直面的問題,更大的模型意味著更貴、更耗電、更熱、需要更強的散熱設計,這直接影響整車成本和可靠性。這就要求廠商采用“既省錢又靠譜”的折中方案,而不是盲目堆模型參數。
黑箱很難過審,責任也難界定
傳統自動駕駛系統將感知、預測、規劃、控制等各模塊分得非常清晰,各模塊可以單獨驗收、打樁測試、形式化驗證。端到端的VLA可以把這些環節耦合在一起,提升效率,但出問題時也很難追根溯源。監管機構、保險公司和法律體系更信任可審計、可重放、可證明的決策路徑。一個不能解釋為何在某一時刻緊急轉向或未能剎停的黑箱模型,在面對事故調查和責任認定會極為不利。
這就要求必須設計日志機制、關鍵中間態保存和可回溯的決策證據。把VLA用于生成解釋性文本(例如“由于前方有臨時施工牌,我建議減速”)是一條可行路徑,但這種解釋必須真實可驗證,不能只是后置拼湊的“借口”。此外,形式化安全約束和保證性測試在端到端系統里更難做,需要新的驗證方法論和更多的試驗數據,短期內法規適配也是一道門檻。
視覺好用但不會在所有場景都看清
VLA的名字里有個“V”(視覺),這意味著相機會是主傳感器。相機能提供豐富的語義信息,但在弱光、逆光、霧霾、雨雪或被遮擋時,它的表現會明顯下降。雷達和激光雷達在測距和穿透性上有優勢,但它們給出的信息不是“語義友好”的,對于“這是誰/這塊牌子意味著什么”的解釋不如視覺直觀。把視覺的語義理解和雷達/激光雷達的物理量整合起來,是一件技術上復雜但很有必要的事。
此外,同樣的視覺目標在不同城市或國家外觀可能差別很大,標準交通標識、路面材質、車輛樣式都不同。模型的跨域遷移需要大量本地化數據和細致的微調,不然在新環境中容易出問題,就像特斯拉FSD在國內使用初期,其表現也并不是很好。簡而言之,要讓大模型做到“放車就能跑遍全世界”,現階段還不現實。
如何安全地把控制權還給人?
VLA最大的優勢之一是能用自然語言和人互動,這對用戶體驗很重要。但自然語言含糊和歧義性極高。用戶可能給出矛盾或不完整的指令,系統必須在理解意圖與遵守安全約束之間平衡。還有一個更現實的情況是,系統在遇到邊緣場景時,如何安全地把控制權還給人?人被動從乘客身份到主動接管需要時間和注意力切換,如果這個過程設計不當,就會增加風險。因此,需要明確接管觸發條件、足夠的時間窗和清晰的提示方式,同時在設計上盡量減少對用戶即時高復雜度決策的依賴。
對于消費者來說,對自動駕駛汽車的信任也非常關鍵。一次危險的動作就可能毀掉用戶對系統的信心。要建立信任,系統需要持續可靠且能解釋自己的行為。VLA在解釋性輸出方面有天然優勢,但前提是解釋必須準確、可驗證,并且易于理解。

可落地的折中策略
鑒于VLA模型不可不去面對的這些挑戰,現階段最務實的做法是漸進式、混合式落地。把VLA用在語義理解、異常檢測、場景注釋、人機交互等對實時性不那么敏感但對語義能力要求高的功能上,讓它成為“智能的助手”;對于關鍵的高頻控制仍然交給經過驗證的低級控制器。還有一種思路就是把VLA當作慢思維:在后臺做長時間的策略優化、駕駛風格學習和復雜場景分析,再把受限的結論以可解釋且受約束的方式下發給車端控制系統。
對于商用化的模型,還必須設計好回退機制、日志與可審計模塊,并把它們寫進每一次版本的驗收標準。數據采集策略要優先覆蓋那些影響安全的長尾場景,仿真和現實測試要結合進行,驗證體系要能給出可量化的安全證據而不是單純的性能曲線。
審核編輯 黃宇
-
Vla
+關注
關注
0文章
20瀏覽量
5895 -
自動駕駛
+關注
關注
793文章
14883瀏覽量
179900
發布評論請先 登錄
自動駕駛汽車如何完成超車?
自動駕駛汽車如何實現自動駕駛
已有VLM,自動駕駛為什么還要探索VLA?
自動駕駛汽車如何檢測石頭這樣的小障礙物?
VLA與世界模型有什么不同?

VLA能解決自動駕駛中的哪些問題?
自動駕駛汽車如何確定自己的位置和所在車道?
VLA和世界模型,誰才是自動駕駛的最優解?
自動駕駛上常提的VLA與世界模型有什么區別?
如何確保自動駕駛汽車感知的準確性?

自動駕駛汽車是如何準確定位的?
VLA,是完全自動駕駛的必經之路?




 工商網監
工商網監
評論