 有關 AI 算力,華為昇騰刷新行業記錄
有關 AI 算力,華為昇騰刷新行業記錄

電子發燒友網報道(文 / 吳子鵬)近日,GitCode 網站上更新了一份題為《昇騰 AI 算力集群基礎設施高可用技術系列報告》的文件。報告顯示,華為團隊通過構建極致可靠性的 CloudMatrix 超節點,有效降低了故障概率。在訓練業務方面,實現分鐘級 RTO(恢復時間目標);在高頻 HBM 場景下,故障恢復時間縮短至 30 秒級,成功將萬卡級訓練集群可用度提升至 95% 以上。
此外,該文件還涵蓋硬件管理、故障感知與診斷、超節點系統等相關創新內容,帶來了諸多顯著成果:萬卡集群可用度達到 98%,集群訓推最快實現秒級快速恢復,集群線性度超過 95%,并建立起包含千種故障模式的數據庫,實現分鐘級故障診斷。值得注意的是,98% 的萬卡集群可用度在目前已公開的數據中處于領先水平。
AI 算力集群穩定性至關重要
萬卡集群是由超過一萬張加速卡(如 GPU、TPU 或專用 AI 芯片)組成的高性能計算系統,主要用于加速人工智能模型的訓練和推理過程。隨著 AI 大模型參數體量不斷攀升,萬卡集群已逐漸成為行業標配,甚至可以說是最低配置。
這一趨勢推動了算力規模的快速增長。根據 IDC 的報告,2024 年全球智能算力規模達 725.3EFLOPS(FP16),同比激增 74.1%。預計到 2025 年,中國智能算力規模將突破 1037.3EFLOPS,相比 2023 年實現翻倍增長。
然而,萬卡集群在實際應用中面臨著三大顯著挑戰:其一,穩定性直接影響 “算力利用率”,在大規模訓練過程中,節點故障可能導致梯度同步中斷、模型參數回滾,甚至需要重新啟動訓練任務;其二,動態實時推理系統任務呈現兩極分化的特點,推理階段硬件需同時滿足高吞吐與低延遲的要求,并且在不同場景下都要有穩定表現;其三,實現復雜萬卡集群的長期穩定運行難度巨大,萬卡集群包含數萬顆芯片、數十萬條光鏈路、數千臺交換機,僅光模塊故障率就會隨著規模擴大呈指數增長,傳統單機冗余方案在萬卡規模下因 “故障定位難、恢復時間長” 而失效。
在這些顯性挑戰背后,還隱藏著其他問題。例如,在長穩運行方面,除了硬件設備的穩定性,還需考慮軟件調度的 “蝴蝶效應”。在超大規模訓練中,單個節點的 HBM 內存錯誤可能引發梯度同步失敗,進而破壞整個集群的參數一致性,若調度系統無法快速隔離故障節點,可能引發 “級聯失效”;同時,網絡拓撲的脆弱性也不容忽視,萬卡集群通常采用 Fat-Tree 或 3D Torus 拓撲,核心交換機負載極高,一旦發生擁塞或鏈路閃斷,會導致全局通信延遲大幅上升。
可用性(Availability)與穩定性一樣,也是衡量超大規模集群性能的核心指標,它是穩定性的量化體現,指集群在規定時間內正常運行、滿足計算需求的比例,通常以百分比表示。據測算,萬卡集群的可用性每提升 1%,相當于每年節省數千萬算力成本,這也是頭部 AI 企業將可用性視為 “算力投資回報率” 核心指標的原因。
提升萬卡集群可用性
如前文所述,萬卡級集群的穩定性和可用性已不再僅僅是技術指標,而是決定 AI 產業競爭力的關鍵要素。華為團隊通過構建極致可靠性的 CloudMatrix 超節點,大幅降低故障概率,實現訓練業務分鐘級 RTO 以及高頻 HBM 場景 30 秒級故障恢復。
為解決萬卡級別 AI 集群平均每天會出現一次甚至多次故障的問題,華為團隊提出基于系統工程的硬件故障管理技術,建立起集群全系統可靠性分析模型。CloudMatrix 384 超節點計算柜和總線設備柜關鍵部件均采用冗余設計:在計算柜方面,整柜電源模塊冗余,風扇采用 N+1 冗余,并配備 2N 和 N+R 等供電系統;總線設備柜的交換機采用雙電源供電設計,風扇同樣采用 N+1 冗余設計。此外,還引入了 NPU HBM 多級 RAS 技術以及光模塊本體高可靠技術,使 CloudMatrix 超節點具備萬卡集群連續數天無故障運行的硬件高可靠能力,系統可用度超過 95%。
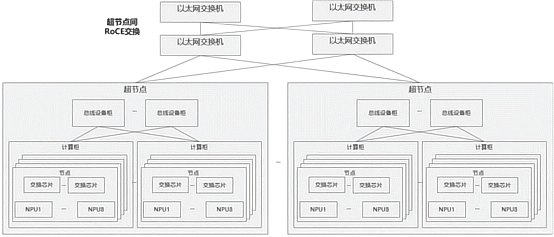
CloudMatrix 超節點,圖源:華為技術報告
針對萬卡集群規模大、故障頻發,軟硬技術棧復雜,涉及數據多、傳播快、依賴復雜等問題,華為團隊提出大規模集群在線故障感知與診斷技術。該方案提供全棧監控,FlowScope 利用自研可編程設備實現準 TB 級流量預處理,能夠在域內快速定位故障。目前該技術已在華為云產品技術棧落地,支持網絡故障 3 分鐘感知、5 分鐘定界,網絡故障診斷準確率達 95%。
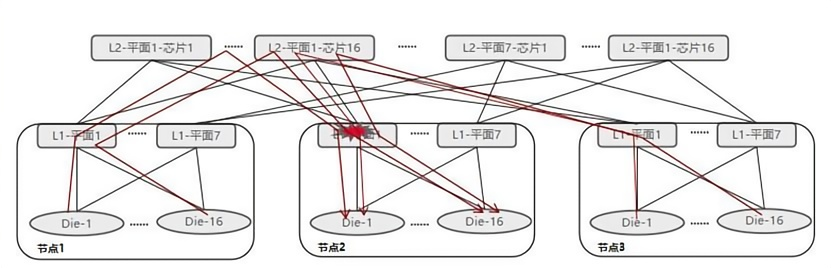
網絡域故障定位,圖源:華為技術報告
為打造緊耦合服務器模式,華為團隊提出極致可靠性的 CloudMatrix 超節點系統技術。單個超節點由 48 臺服務器組成,每臺服務器包含 4 顆 CPU 及 8 顆 NPU。每臺服務器的接口數量為:管存 / VPC 平面 2200GE;參數面 8400GE;超節點平面 56×400G HCCS。一個機柜最大支持 4 個 8 卡節點,管存面 / 參數面交換機以及超節點 L2 層交換機外置,支持靈活組網。該超節點的設計目標是實現光模塊閃斷的故障率容忍度超過 99%;將高頻的 HBM 多比特 ECC 故障恢復時間縮短至 1 分鐘,使因 HBM 故障造成的用戶算力損失下降 5%。通過 “系統層容錯”“業務層容錯” 以及后續 “運維層容錯” 方案,成功實現了這一目標。
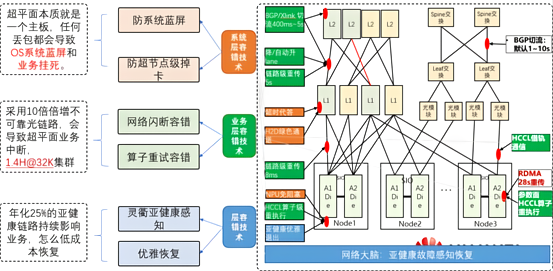
CloudMatrix 超節點系統技術,圖源:華為技術報告
為做到千億稀疏模型訓練線性度優化,華為團隊提出 4 項關鍵技術,包括拓撲感知的協同編排技術 TACO、網絡級網存算融合技術 NSF、拓撲感知的層次化集合通信技術 NB、無侵入通信跨層測量與診斷技術 AICT。實驗及理論分析結果顯示,Pangu Ultra 135B 稠密、Pangu Ultra MoE 718B 稀疏模型訓練線性度超過 95%。具體來看,訓練 Pangu Ultra 135B 稠密模型時,4K 卡 Atlas 800T A2 集群相比 256 卡基線,線性度為 96%;訓練 Pangu Ultra MoE 718B 稀疏模型時,8K 卡 A2 集群相比 512 卡基線,線性度為 95.05%;4K 卡 CloudMatrix 集群相比 256 卡基線,線性度為 96.48%。
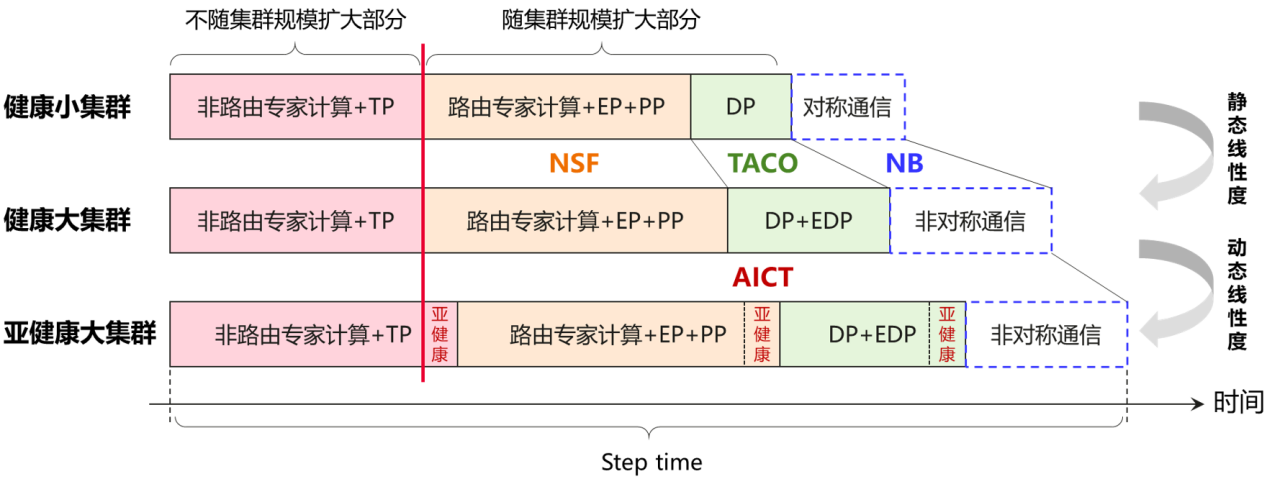
線性度問題分析,圖源:華為技術報告
針對大 EP 推理架構的可靠性難題,華為團隊提出千億 MOE 分布式推理分鐘級恢復技術,通過基于請求切流實例間恢復、基于實例 / Pod 重調度與進程原地恢復的實例內有感恢復、基于 token 級重試和減卡容錯的實例內無損恢復的三級容錯方案,從芯片驅動層、框架層、平臺層協同發力,構筑端到端可靠性體系。面向未來,華為團隊還將持續研發減卡彈性恢復技術和基于快照進程的進程初始化加速技術。
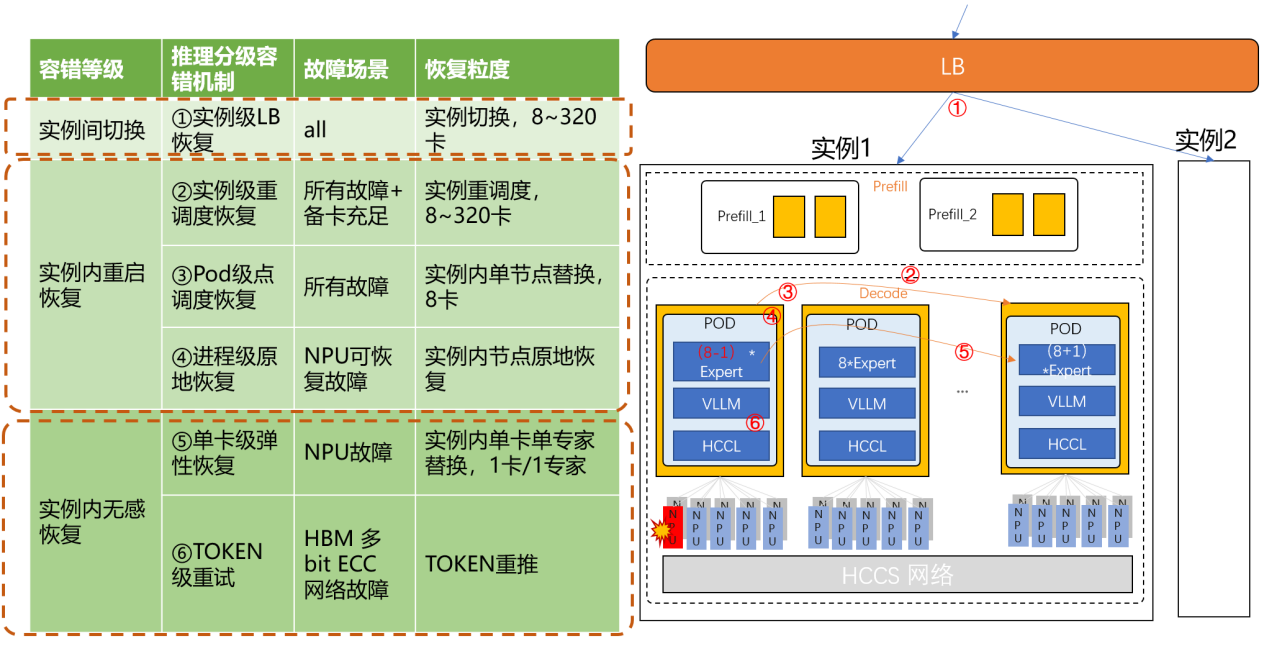
千億 MOE 分布式推理分鐘級恢復技術,圖源:華為技術報告
結語
在 AI 算力集群邁向萬卡規模的產業變革進程中,華為昇騰憑借 CloudMatrix 超節點技術體系,通過硬件冗余設計、全棧故障感知、系統層容錯等創新舉措,將萬卡集群可用度提升至行業領先的 95% 以上,實現高頻 HBM 故障 30 秒級恢復、訓練線性度超 95% 的突破,切實解決了大規模算力集群穩定性與可用性的核心難題。這不僅為 AI 大模型訓練與推理構建了堅實的算力底座,更以 “每提升 1% 可用度節省數千萬成本” 的實際效益,重新定義了算力投資回報率的行業標準。
-
華為
+關注
關注
218文章
36145瀏覽量
262558 -
AI
+關注
關注
91文章
40746瀏覽量
302390
發布評論請先 登錄
【硬核發布】昇騰310B算力盒上新賦能2026集創賽華強x昇騰賽道玩轉新創意!

華為發布全新昇騰950PR,Atlas 350單卡算力接近3倍于H20
2026華為中國合作伙伴大會昇騰人工智能伙伴峰會圓滿落幕
國產算力新標桿!昇騰Atlas 950上市,算力三倍H20和超節點雙突破

【賽題解析】2026集創賽華強x昇騰企業命題!用國產AI算力重塑未來數字幻境!
邊緣AI算力臨界點:深度解析176TOPS香橙派AI Station的產業價值
香橙派昇騰系列開發板如何部署OpenClaw
AI+FPGA助力昇騰生態新篇章|2025昇騰AI技術研討會·杭州站成功舉辦
華為發布全球最強算力超節點和集群



中軟國際出席華為昇騰計算產業發展峰會
華為開發者大會2025(HDC 2025)亮點:華為云發布盤古大模型5.5 宣布新一代昇騰AI云服務上線




 工商網監
工商網監
評論