") PaddleOCR MCP Server 實戰(zhàn):3步將OCR和文檔解析輕松集成到 AI智能體
PaddleOCR MCP Server 實戰(zhàn):3步將OCR和文檔解析輕松集成到 AI智能體

一,為什么文檔 AI 智能體需要PaddleOCR MCP Server?
在構(gòu)建面向報告分析、合同信息提取或科研論文總結(jié)等場景的文檔 AI 智能體時,解析PDF格式文件及掃描版圖像文檔往往成為大語言模型(LLM)的痛點。這是因為LLM本質(zhì)是語言模型,能處理字符序列,卻無法直接解析圖像或PDF文件的內(nèi)容。
PaddleOCR MCP Server 將 PaddleOCR 的文字識別和文檔解析能力,以MCP工具的形式提供給 AI 智能體,從而讓 AI 智能體能夠直接處理文檔內(nèi)容,而無需手動提取文本。
二,什么是PaddleOCR MCP Server?
PaddleOCR MCP Server 是一個輕量級 Model Context Protocol (MCP) 服務(wù),專為將 PaddleOCR 的文檔理解能力無縫集成到文檔AI智能體而設(shè)計,讓AI智能體能夠按需調(diào)用文字識別或文檔解析工具,如下圖所示,實現(xiàn)從圖像/PDF中提取結(jié)構(gòu)化信息:
- OCR:文字識別工具,從圖像/PDF 提取高質(zhì)量文本。
- PP-StructureV3:文檔解析工具,從圖像/PDF中提取表格、標(biāo)題、段落和公式等文檔元素,并以Markdown/JSON格式輸出。
視頻鏈接:[PaddleOCR MCP Server 實戰(zhàn):3步將OCR和文檔解析輕松集成到 AI智能體 (qq.com)]
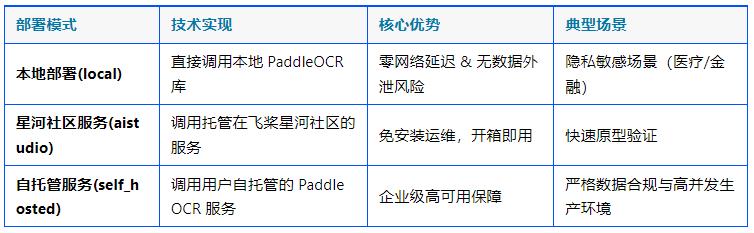
PaddleOCR MCP Server 提供三種部署模式,適配大多數(shù)智能體場景:
三,三步將 PaddleOCR MCP Server 集成到你的 AI 智能體
本節(jié)將以本地部署為例,介紹如何將 PaddleOCR 集成到你的智能體中。
步驟 1??:安裝 PaddleOCR MCP Server
# 創(chuàng)建并激活虛擬環(huán)境 (推薦)
conda create -n ocr-env python=3.11
conda activate ocr-env
# 安裝PaddlePaddle GPU版本 (根據(jù)您的CUDA版本選擇合適的版本)
pip install paddlepaddle-gpu==3.1.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
python -c "import paddle; paddle.utils.run_check()" # 驗證PaddlePaddle安裝是否成功
# 安裝PaddleOCR
pip install paddleocr[doc-parser]
# 安裝PaddleOCR MCP Server
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
pip install -e mcp_server
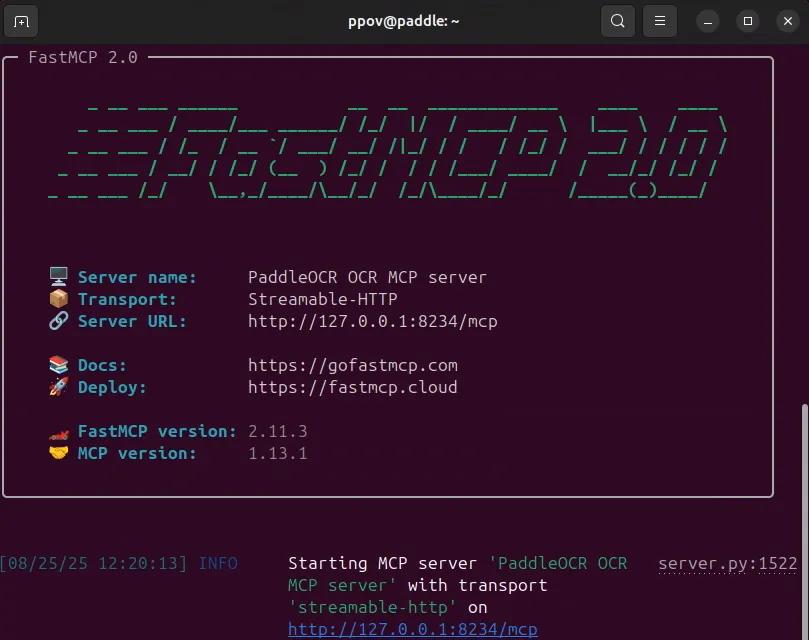
安裝完畢后,運行以下命令,若出現(xiàn)下圖所示的運行信息,則說明安裝成功:
paddleocr_mcp --pipeline OCR --ppocr_source local --port 8234 --http
步驟 2??:配置PaddleOCR MCP Server
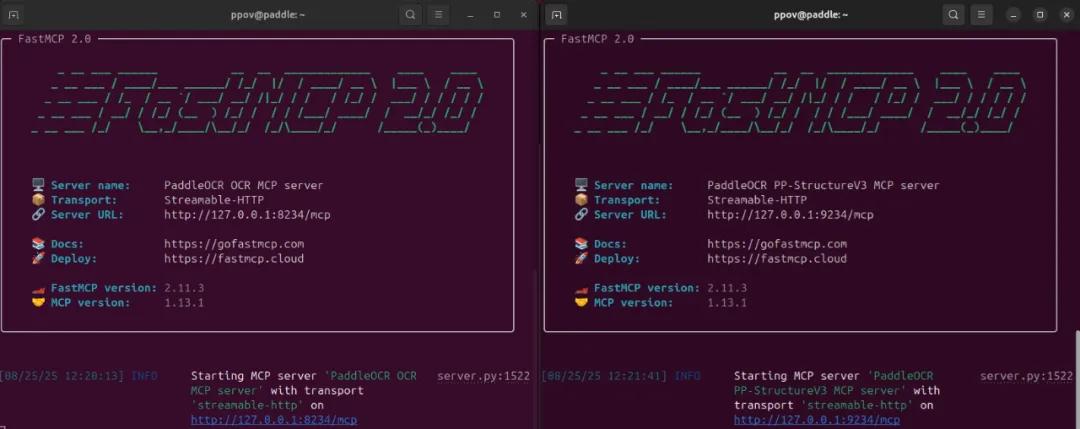
首先,打開兩個命令行窗口,分別運行以下命令,啟動PaddleOCR MCP Server的OCR和PP-StructureV3服務(wù):
# 啟動PaddleOCR OCR MCP Server
paddleocr_mcp --pipeline OCR --ppocr_source local --port 8234 --http
# 啟動PaddleOCR PP-StructureV3 MCP Server
paddleocr_mcp --pipeline PP-StructureV3 --ppocr_source local --port 9234 --http
然后,在你的 AI 智能體 MCP 配置文件中(例如:mcp_settings.json)添加以下內(nèi)容:
{
"mcpServers": {
"pp-ocrv5": {
"isActive": true,
"name": "PP-OCRv5 (local)",
"type": "streamableHttp",
"description": "Local PP-OCRv5 pipeline for text recognition.",
"tags": [],
"baseUrl": "http://127.0.0.1:8234/mcp"
},
"pp-structurev3": {
"isActive": true,
"name": "PP-StructureV3 (local)",
"type": "streamableHttp",
"description": "Local PP-StructureV3 pipeline for document parser.",
"tags": [],
"baseUrl": "http://127.0.0.1:9234/mcp"
}
}
}
以Cherry Studio為例,在Settings中選擇 MCP,并把上述配置復(fù)制到JSON編輯框,然后點擊OK按鈕即可。
https://www.cherry-ai.com/
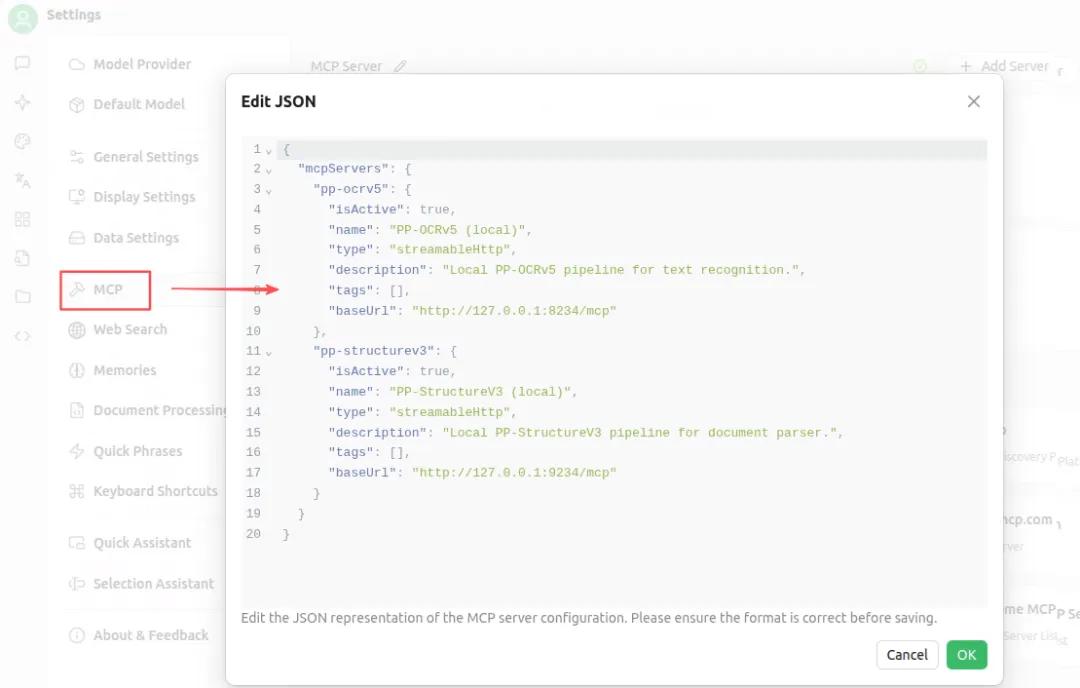
配置成功后,會有一個小綠點出現(xiàn),如下圖所示:
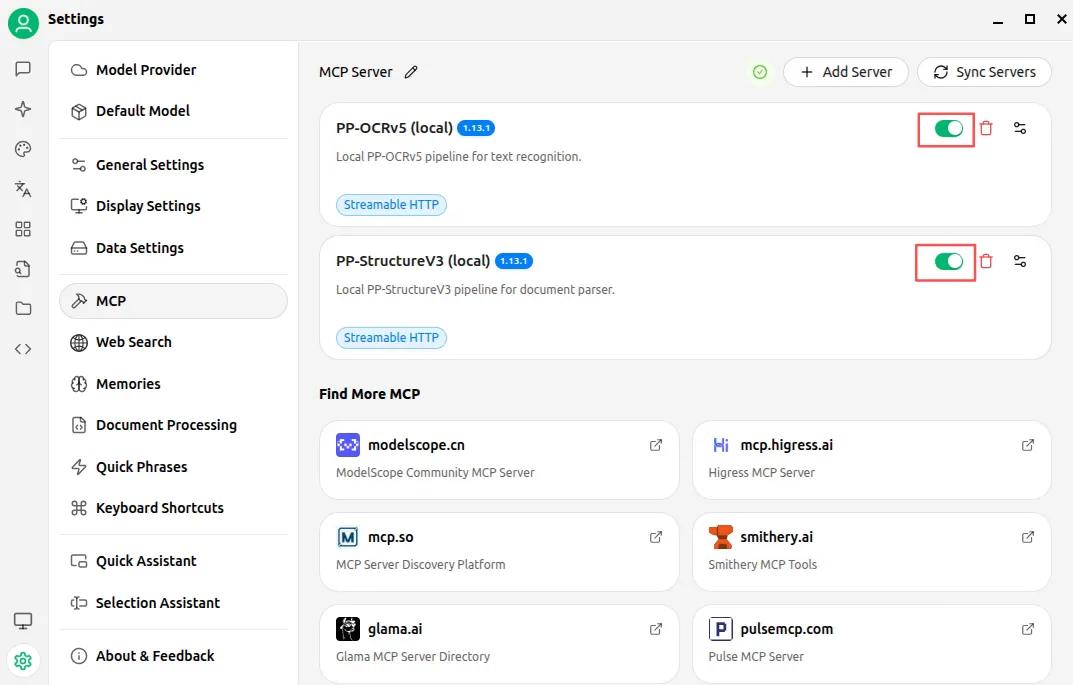
步驟 3??:在智能體中調(diào)用PaddleOCR MCP Server的能力
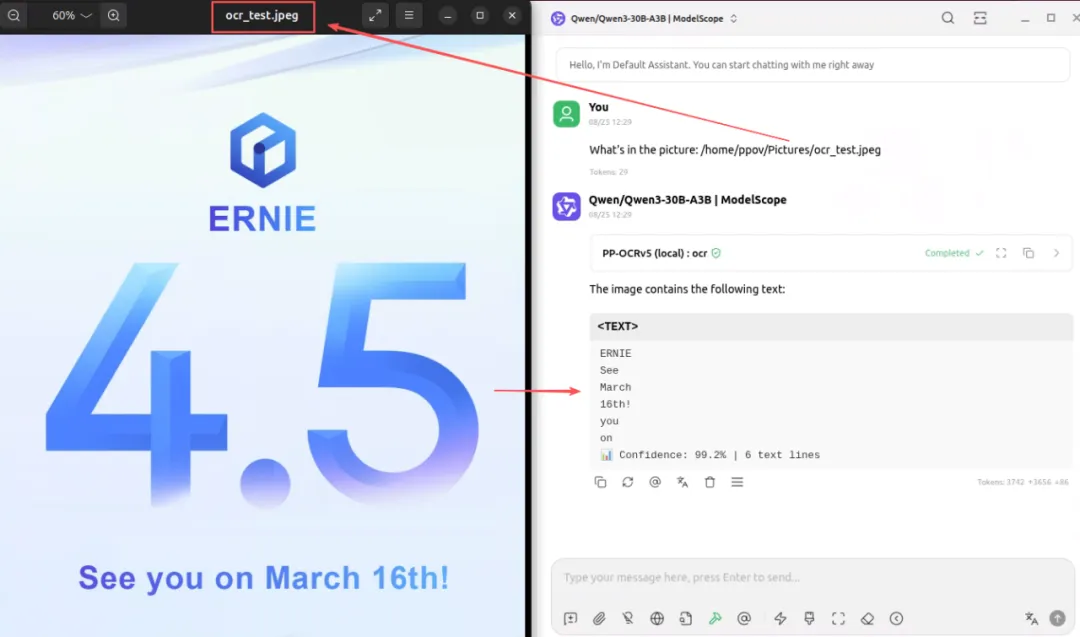
當(dāng)PaddleOCR MCP Server配置成功后,僅需要在智能體中使用具有function-call能力的大語言模型,即可調(diào)用 PaddleOCR MCP Server的工具。以Cherry Studio為例,在智能體中調(diào)用OCR工具的示例如下:
Prompt: What's in the picture: /home/ppov/Pictures/ocr_test.jpeg
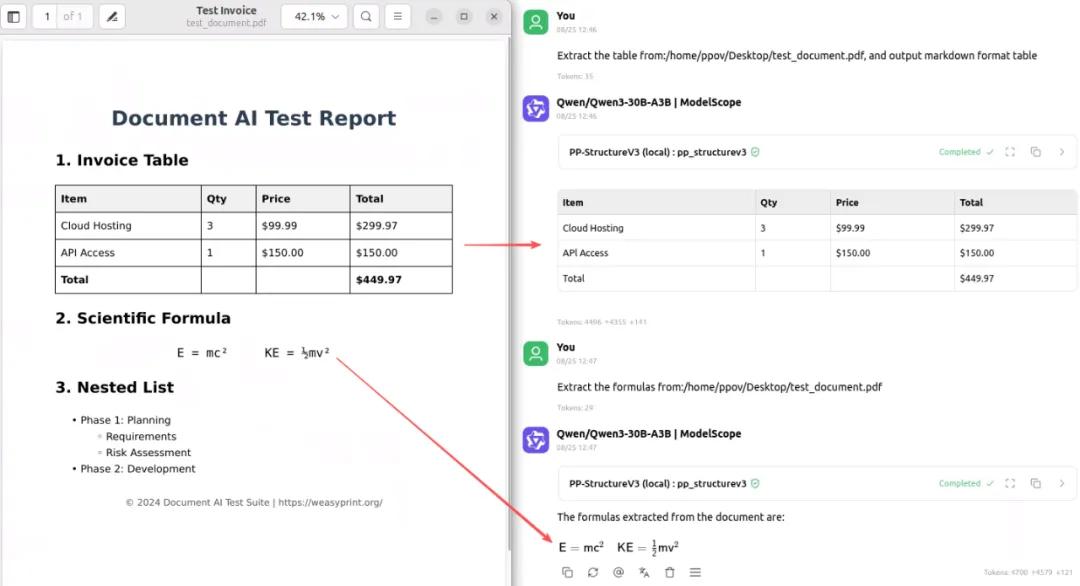
在智能體中調(diào)用PP-StructureV3工具的示例如下:
Prompt: Extract the table from:/home/ppov/Desktop/test_document.pdf, and output markdown format table
四,總結(jié)與展望
PaddleOCR MCP Server是 AI 智能體理解圖片和PDF文檔的橋梁。通過3 步將OCR和文檔解析輕松集成到 AI 智能體 —— 相當(dāng)于讓AI智能體獲得了“閱讀”文檔的能力,拓展了AI智能體的能力邊界。
下一步與資源
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
91文章
39793瀏覽量
301436 -
OCR
+關(guān)注
關(guān)注
0文章
175瀏覽量
17203 -
MCP
+關(guān)注
關(guān)注
0文章
289瀏覽量
15013
發(fā)布評論請先 登錄
百度正式發(fā)布并開源新一代文檔解析模型PaddleOCR-VL-1.5

使用 Docker 一鍵部署 PaddleOCR-VL: 新手保姆級教程

PP-OCRv5 MCP服務(wù)器在海光主板的部署與實戰(zhàn)
智能硬件通過小聆AI自定義MCP應(yīng)用開發(fā)操作講解
【內(nèi)測活動同步開啟】這么小?這么強?新一代大模型MCP開發(fā)板來啦!
精準(zhǔn)定位性能瓶頸:深入解析 PaddleOCR v3.2 全新 Benchmark 功能
小語種OCR標(biāo)注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標(biāo)注實戰(zhàn)解析
【HZ-T536開發(fā)板免費體驗】5- 無需死記 Linux 命令!用 CangjieMagic 在 HZ-T536 開發(fā)板上搭建 MCP 服務(wù)器,自然語言輕松控板
【EASY EAI Orin Nano開發(fā)板試用體驗】PP-OCRV5文字識別實例搭建與移植
端側(cè)OCR文字識別實現(xiàn) -- Core Vision Kit ##HarmonyOS SDK AI##
在Cherry Studio中快速使用markitdown MCP Server?

如何用FastMCP快速開發(fā)自己的MCP Server?

用MCP將百度地圖能力輕松接入DeepSeek




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論