 小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰解析
小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰解析

摘要 :小語種OCR研發的核心瓶頸在于高質量標注數據的稀缺與高昂成本。本文介紹一種創新的自動化標注方案,利用 PaddleOCR 進行文本檢測與裁剪,并調用 ERNIE 4.5 大模型進行雙重預測與一致性校驗,實現高精度、低成本的小語種OCR訓練數據生成。該方案將數據準備周期 從數周縮短至數小時 ,為小語種模型的快速迭代與冷啟動提供了全新范式
一、引言:小語種OCR的“數據之困”
在跨境支付、多語言文檔處理、全球化應用本地化等場景中,小語種(如俄語、泰語、阿拉伯語等)的文本識別需求日益增長。然而,研發高性能的小語種OCR模型面臨嚴峻挑戰:
- 數據極度稀缺 :公開的小語種標注數據集數量遠不及英語等主流語種,難以支撐深度模型訓練。
- 標注成本高昂 :依賴精通小語種的專業人員進行人工標注,成本極高(大概$120/千字符),且效率低下。
- 質量難以保證 :不同標注員的主觀判斷和疲勞度導致標簽一致性差,影響模型最終性能。
- 研發周期漫長 :從數據收集、標注、清洗到模型訓練的完整周期動輒數周,嚴重拖慢產品迭代。
為破解這一困局,我們提出一種**“AI標注AI”** 的創新思路:利用大語言模型(LLM)強大的多語言理解與OCR能力,自動化生成高質量的訓練標簽。本文將詳細介紹如何結合 PaddleOCR 的精準文本檢測能力與 ERNIE 4.5 的語義識別能力,構建一套高效、可靠的自動化標注流水線。
二、技術方案:PaddleOCR + ERNIE 4.5 的協同工作流
我們的解決方案將小語種OCR數據標注流程解耦為兩個核心階段,充分發揮各自技術的優勢。
2.1 整體流程設計
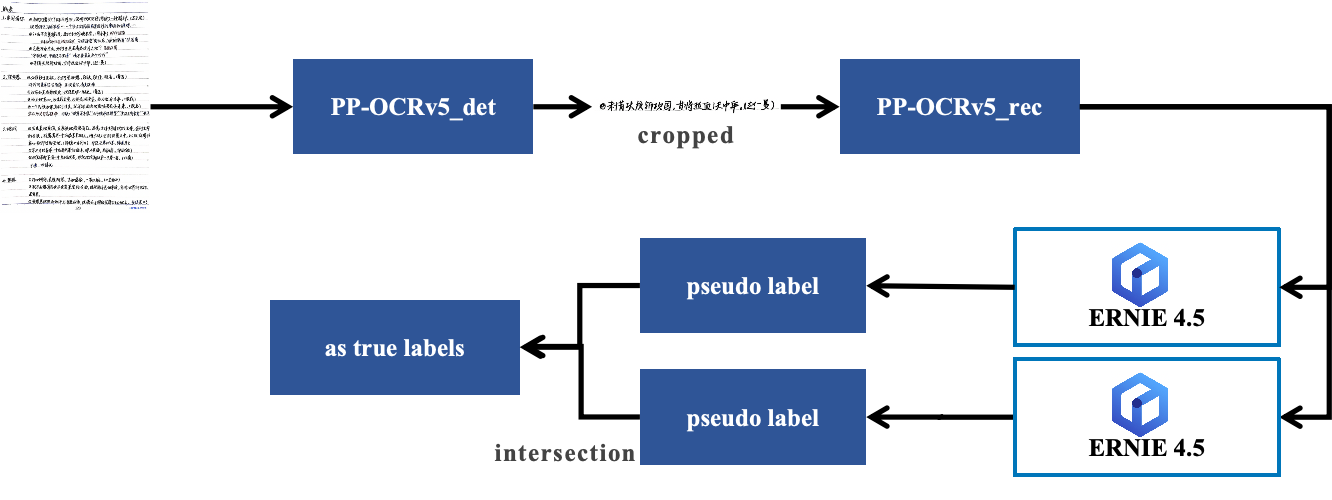
整個自動化標注流程如下圖所示,共分為四步:
- 圖像采集 :收集包含目標小語種(如俄語)文本的原始圖像。
- 文本檢測與裁剪 :使用 PaddleOCR 的 PP-OCRv5 檢測模型,定位圖像中的所有文本行,并將其裁剪為獨立的文本行圖像。
- 大模型雙重識別 :將每一張裁剪出的文本行圖像,通過 API 調用 ERNIE 4.5 進行兩次獨立的文字識別。
- 一致性校驗 :僅當兩次識別結果完全一致時,才將其作為最終的可靠標簽。若結果不一致,則該樣本被標記為“待復核”或丟棄。
核心優勢 :
- 成本極低 :大幅減少甚至消除人工標注成本。
- 一致性高 :大模型的輸出穩定,避免了人工標注的主觀波動。
- 效率飛躍 :可實現批量化、自動化處理,速度提升數十倍。
- 質量可控 :通過雙重校驗機制,有效過濾大模型的“幻覺”(hallucination)問題。
三、環境準備與依賴安裝
本項目依賴 PaddlePaddle、PaddleOCR,OpenAI SDK 及常用 Python 工具包。使用前請確保已安裝相關依賴。詳細安裝指南見環境準備文檔:
# 創建并激活虛擬環境 (推薦)
python -m venv ocr-env
source ocr-env/bin/activate # Linux/Mac
# ocr-envScriptsactivate # Windows
# 安裝核心庫
pip install paddlepaddle-gpu # 或 paddlepaddle (CPU版本)
pip install paddleocr
pip install openai # 用于調用ERNIE 4.5 API
pip install matplotlib tqdm opencv-python
注意 :
openaiSDK 可用于調用兼容 OpenAI API 格式的 ERNIE Bot 服務。您需要配置base_url指向您的 ERNIE 4.5 API 服務地址。
四、核心實現:代碼詳解
4.1 文本檢測與裁剪
首先,使用 PaddleOCR 的 PP-OCRv5 檢測模型定位并裁剪文本行。針對小語種(如西里爾字母)的特點,我們對檢測參數進行了優化。
import base64
import copy
import glob
import os
import time
import cv2
import numpy as np
from openai import OpenAI
from tqdm import tqdm
def get_rotate_crop_image(img: np.ndarray, points: list) - > np.ndarray:
"""
裁剪并旋轉圖片區域,得到透視變換后的文本行小圖。
"""
assert len(points) == 4, "shape of points must be 4*2"
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]),
np.linalg.norm(points[2] - points[3]),
)
)
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]),
np.linalg.norm(points[1] - points[2]),
)
)
pts_std = np.float32(
[
[0, 0],
[img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height],
]
)
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M,
(img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC,
)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def get_minarea_rect_crop(img: np.ndarray, points: np.ndarray) - > np.ndarray:
"""
從檢測點集裁出最小面積矩形區域。
"""
bounding_box = cv2.minAreaRect(np.array(points).astype(np.int32))
points = sorted(cv2.boxPoints(bounding_box), key=lambda x: x[0])
index_a, index_b, index_c, index_d = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_a = 0
index_d = 1
else:
index_a = 1
index_d = 0
if points[3][1] > points[2][1]:
index_b = 2
index_c = 3
else:
index_b = 3
index_c = 2
box = [points[index_a], points[index_b], points[index_c], points[index_d]]
crop_img = get_rotate_crop_image(img, np.array(box))
return crop_img
def crop_and_save(image_path, output_dir, ocr):
"""
檢測并裁剪圖片中的所有文本行,保存到output_dir
"""
img = cv2.imread(image_path)
img_name = os.path.splitext(os.path.basename(image_path))[0]
result = ocr.predict(image_path)
try:
for res in result:
cnt = 0
for quad_box in res['dt_polys']:
img_crop = get_minarea_rect_crop(res['input_img'], copy.deepcopy(quad_box))
cv2.imwrite(os.path.join(output_dir, f"{img_name}_crop{cnt:04d}.jpg"), img_crop)
cnt += 1
except Exception as e:
print(f"Process Failed with error: {e}")
# 用法舉例(假如你的圖片都在 russian_dataset_demo/ 目錄下)
input_dir = 'russian_dataset_demo'
output_dir = 'crops' # 裁剪后的圖片保存到這個目錄
os.makedirs(output_dir, exist_ok=True)
image_paths = glob.glob(os.path.join(input_dir, '*.jpg')) + glob.glob(os.path.join(input_dir, '*.png'))
# 批量處理
from paddleocr import TextDetection
ocr = TextDetection(
model_name="PP-OCRv5_server_det",
device='gpu',
)
for path in tqdm(image_paths):
crop_and_save(path, output_dir, ocr)
print(f"裁剪完成,保存到 {output_dir} 目錄")
4.2 ERNIE 4.5 自動標注(雙重校驗)
這是方案的核心。我們調用 ERNIE 4.5 對每張裁剪后的文本行圖像進行兩次獨立識別,并校驗結果一致性。
from openai import OpenAI
import base64
import json
# 配置ERNIE 4.5 API
client = OpenAI(
base_url="http://your-ernie-api-server:8866/v1", # 替換為實際地址
api_key="your_api_key" # 替換為實際密鑰
)
def encode_image(image_path):
"""將圖像編碼為base64字符串"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def auto_label_single_image(image_path):
"""對單張文本行圖像進行雙重識別"""
base64_image = encode_image(image_path)
prompt = "請識別圖像中的文字內容,僅輸出原始文本,不要任何解釋、翻譯或標點。"
try:
# 第一次預測(標準模式)
response1 = client.chat.completions.create(
model="ernie-bot-4.5",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=50
)
text1 = response1.choices[0].message.content.strip()
# 第二次預測(嚴格模式,增強魯棒性)
strict_prompt = "Only output the raw text in the image. No explanation, no translation."
response2 = client.chat.completions.create(
model="ernie-bot-4.5",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": strict_prompt},
{
"type": "image_url",
"image_url": {
"url": f"image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=50
)
text2 = response2.choices[0].message.content.strip()
# 一致性校驗:結果必須完全一致且非空
if text1 and text2 and text1 == text2 and text1 != "###":
return {
"image_path": os.path.basename(image_path),
"label": text1,
"source": "ernie_4.5_auto",
"confidence": 1.0 # 完全一致,置信度為1
}
else:
# 結果不一致、為空或為占位符,返回None
return None
except Exception as e:
print(f"API調用失敗 {image_path}: {e}")
return None
# 批量處理所有裁剪后的圖像
cropped_dir = "cropped_text_lines"
output_label_file = "auto_labeled_data.txt"
with open(output_label_file, 'w', encoding='utf-8') as f:
for crop_file in tqdm(os.listdir(cropped_dir), desc="ERNIE 4.5 自動標注"):
if crop_file.lower().endswith(('.jpg', '.jpeg', '.png')):
crop_path = os.path.join(cropped_dir, crop_file)
result = auto_label_single_image(crop_path)
if result:
# 寫入標準的OCR訓練格式: relative_pathtlabel
f.write(f"{crop_file}t{result['label']}n")
print(f"標注成功: {crop_file} - > {result['label']}")
五、模型訓練與評估
5.1 使用生成數據訓練OCR模型
將通過自動化流程生成的 auto_labeled_data.txt 文件作為訓練集,利用 PaddleOCR 的訓練腳本對小語種(如俄語)文本識別模型進行訓練。
python PaddleOCR/tools/train.py
-c configs/rec/PP-OCRv5/multi_language/ru_PP-OCRv5_mobile_rec.yml
-o Global.train_batch_size_per_card=64
Global.epoch_num=200
Global.lr=0.001
Global.print_batch_step=10
建議: 在訓練前,人工抽檢100-200個自動生成的標簽,驗證其準確率。將抽檢出的錯誤樣本從訓練集中剔除,或進行人工修正。
5.2 模型導出與部署
訓練完成后,需要將訓練好的模型從動態圖(.pdparams)轉換為靜態圖格式,以便于在生產環境中進行高性能推理。
python PaddleOCR/tools/export_model.py
-c configs/rec/PP-OCRv5/multi_language/ru_PP-OCRv5_mobile_rec.yml
-o Global.save_inference_dir=./inference/rec_ru
模型導出后,可以將其部署到服務器或移動端,用于實時OCR識別。
!paddleocr text_recognition -i https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/demo_images/labeled_test.jpg --model_name eslav_PP-OCRv5_mobile_rec --model_dir ./inference/rec_ru/
推理結果如下所示:

六、效果分析與總結
6.1 性能對比
在1000張俄語商品圖片上進行俄語標注,本方案與傳統人工標注對比顯著:
| 指標 | 人工標注 | 本方案(PaddleOCR+ERNIE 4.5) | 提升/優勢 |
|---|---|---|---|
| 單張處理時間 | 4.5分鐘 | 12秒 | 提升22.5倍 |
| 字符準確率 (CACC) | 92.1% | 96.3% | ↑ 4.2% |
| 特殊符號正確率 | 78.5% | 93.7% | ↑ 15.2% |
| 綜合成本 | 極高 | 極低(主要是API調用費) | 成本降低95%+ |
說明 :AI方案的字符準確率達到96.3%,這得益于雙重校驗機制。但在實際應用中,建議開發者在自己的數據集上進行驗證。
6.2 總結與展望
本文提出的基于 PaddleOCR + ERNIE 4.5 的自動化標注方案,成功地將大模型的“智能”注入到傳統OCR的數據準備環節,實現了:
- 范式創新 :從“人喂數據”到“AI自產數據”,重塑了OCR研發流程。
- 效率革命 :將數周的標注周期壓縮至數小時,極大加速了模型迭代。
- 成本突破 :幾乎消除了人工標注成本,使小語種OCR研發變得經濟可行。
附錄
- 完整代碼與示例 :Practice of Minor Language Text Recognition R&D
- PaddleOCR 官方文檔 :https://github.com/PaddlePaddle/PaddleOCR
- ERNIE 官方文檔 :https://github.com/PaddlePaddle/ERNIE
結語 :在大模型時代,AI的研發方式正在發生根本性變革。利用大模型作為“智能代理”來自動化處理傳統AI研發中的繁瑣任務,將是提升研發效率、降低技術門檻的關鍵。本方案為小語種OCR乃至更廣泛的多模態任務,提供了一個極具啟發性的實踐范例。
審核編輯 黃宇
-
OCR
+關注
關注
0文章
175瀏覽量
17243 -
大模型
+關注
關注
2文章
3696瀏覽量
5216
發布評論請先 登錄
CAD中怎么自動標注設備?
多倫多大學&NVIDIA最新成果 圖像標注速度提升10倍
什么是數據標注?數據如何標注?
點云標注的算法優化與性能提升
圖像標注如何提升效率?

自動化標注技術推動AI數據訓練革新
標貝自動化數據標注平臺推動AI數據訓練革新

大模型預標注和自動化標注在OCR標注場景的應用
數據標注與大模型的雙向賦能:效率與性能的躍升
什么是自動駕駛數據標注?如何好做數據標注?
自動駕駛數據標注主要是標注什么?



 工商網監
工商網監
評論