2021年5G已經在大城市范圍內普及,等到全面普及和應用還要走多少的路
2021-06-09 18:27:57
要的是,延遲率比4 g LTE 小10到20倍。關于連接的任何對話的一個關鍵組成部分是延遲。延遲(或延遲)是指網絡對一個動作或輸入的反應速度。延遲為5g 網絡的幾個應用程序的出現提供了改變游戲規則的手段
2022-04-10 21:31:45
James Huang也受邀演講,闡述了5G發展道路中那些繞不開的射頻關鍵技術。Qorvo大客戶高級銷售James Huang在2018全球預商用5G產業峰會上發表演講 那大家知道5G發展道路中哪些射頻關鍵技術是繞不開的嗎?
2019-07-30 08:14:07
的標準之路上,3GPP的LTE已經徹底碾壓了其他對手,LTE的下一個版本LTE-Advanced被認為是第一個4G標準,后續還有叫LTE-Advanced Pro的增強版本,然后就該到5G了。我們先是把
2018-01-20 12:36:42
都說2020年是5G商用元年。而在剛剛過去的2016年里,HUAWEI、Nokia、Ericsson、Qualcomm、AT&T、Optus、CMCC等設備商與運營商積極合作測試5G,早已
2019-09-16 10:12:13
移動通信在短短的三十多年里便實現了從1G到4G的跨越式發展。三十多年在漫漫的人類歷史長河只能算是彈指一揮間,5G的8個KPI指標遠不是移動通信發展的終極目標。5G以后,希望每個G不再只是更高的速率、更短的時延,我們期望可以給人類帶來更多、改變更多。
2019-07-11 06:30:39
的機遇。半導體業在先進制程繼續發威、5G芯片競爭也進入白熱化階段。高階半導體也愈戰愈勇、再加上國內去美國化趨勢繼續等五大支柱支撐下,2020年第一季景氣淡季不淡的輪廓似乎日趨顯著。半導體設備的發展預示
2019-12-03 10:10:00
我們可以用5G來描述新一代移動數據標準,也可以用來描述一種Wi-Fi頻率類型或者頻譜。根據環境的不同,其定義和屬性也完全不同。大多人并不明白這一點,因為當我們提到5G時,往往錯誤假定它在移動
2020-12-22 06:45:40
expectations》。文章分析了5G時代eMBB、mMTC和uRLLC三大新領域帶來的挑戰,以及為滿足這些應用的發展訴求,未來網絡在帶寬、時延、SDN等方面需要達成的能力。同時文章指出,目前全球有50
2019-06-18 06:26:28
出,高頻通信,超密集聯網等技術,增加了天線饋線系統的安裝難度,增加了基站數量。5G基站發展建設現狀及組網技術在5G基站建設過程中的環境評估和評估成為重要問題。目前,我國工業和信息化部已開始選擇在一線城市
2020-10-12 16:21:22
穩定運行。那5G基站電源配套如何改造?是怎樣計算的?5G基站由BBU和AAU組成,本文按一個基站三小區(1個BBU+3個AAU)配置,假設5G BBU功耗為350W,AAU功耗為1100W,來進行相關電源
2021-12-28 06:45:15
增加。一直以來,“5G究竟要花多少錢”,是人們普遍關心的話題。有人說,5G的投資將會是4G的2~3倍。也有人說,5G的總投資將到達驚人的1.5萬億元。 根據最新的《2020中國5G經濟報告》,國內
2020-11-27 06:43:18
數據監控病人一系列的重要生命體征,動態管理治療計劃,并通過網絡攝像頭進行咨詢或干預。5G網絡的到來將把這一最新醫療趨勢帶入下一階段,并為醫學界提供一個巨大的經濟增長點。根據IHS Markit的數據
2019-06-18 07:46:37
`物聯網應用興起,細分領域的大部分芯片不需要用到先進晶圓制程,模塊化封裝變成一個趨勢;如BLE,WIFI,RF,PMIC等功能芯片組合成一個模組(SIP),實現模塊的多種功能集成。 同時5G網絡
2020-04-02 16:21:51
,攻城略地,都把商用節點壓在2020年,商用也許離我們不遠了,以下是一些廠商在5G上的發展: 華為:2009年華為就啟動了5G研究的工作,并在加拿大的渥太華建立了全球第一個5G研發中心,并與世界多所著名高校
2016-06-23 10:33:33
5G 商用化是 2019 年最讓眾人期待的技術發展之一。在剛舉行的 2019 世界移動通訊大會上,眾多手機廠商展示新一代 5G 手機。華為推出的新折迭屏幕手機便支持 5G 網絡,更示范在數秒內下載容量達 1GB 的電影內容,大幅提升用戶的移動體驗。
2019-07-29 08:41:14
以下來自國泰君安對5G的深度分析,報告顯示根據5G標準的制定日程以及基礎建設的流程,5G建設周期可以按先后順序分為規劃期、建設期和應用期。 除運營商外,大部分細分行業只歸屬于其中一個階段。規劃期主要
2019-09-17 06:43:09
專利數前十的公司中,中國公司占據了3個席位,其中華為位居全球第一。
據IHS預測,到2035年,5G將給中國帶來9640億美元的總產值、950萬個就業機會。
老百姓啥時候能用上5G
2019-03-14 09:29:58
人望而卻步,畢竟誰的錢都不是大風刮來的,估計需要一到兩年,5G技術發展成熟,市場上5G手機遍地開花,價格才會降到一個合理的位置。
2019-08-17 10:10:01
一、通訊技術發展5G——天下武功,唯快不破!在移動互聯網時代,最核心的技術是移動通信技術。而在通信行業,標準之爭是最高話語權的爭奪。一旦標準確立,將對全球通信產業產生巨大影響。縱觀世界通訊技術發展
2019-07-10 08:16:41
5G技術的演變 5G技術是從4G技術向前的自然演進,相比于目前使用的4G技術,5G甚至可以處理多于3個數量級的信息量和數據。這不僅代表了無線連接的發展方向,更代表了一種全新更高的無線連接
2020-06-30 11:32:05
5G帶來的并非只是單純的速度提升。作為一個統一的連接架構,5G在這個連接設計框架內需要支持多樣化頻譜、多樣化服務與終端和多樣化部署……有媒體朋友采訪到ADI 通信業務部門CTO Thomas Cameron博士,小編為你摘出部分精華,看ADI對5G技術現狀與趨勢的解讀。
2019-09-18 06:16:32
第四代移動通信(4G)技術在全球范圍的規模商用,面向2020年及未來商用的第五代移動通信(5G)技術研發與標準化已全面啟動。在全球業界的大力推動下,5G技術研究快速發展,當前已經進入技術標準研制的關鍵階段,各國也紛紛發布5G試驗計劃來推動5G技術與標準的發展。
2019-07-11 06:26:22
讀者理解5G的現狀及發展,洞見誰崛起、誰隕落,并嘗試理清投資的邏輯。 5G雖好,但也很“燒錢” 首先我們需要了解什么是5G?5G是4G之后的通信標準,今年陸續在世界主要國家和地區開始商用。 每一代通信
2019-08-15 08:30:00
隨著5G技術的出現,現在成為一名RF工程師是一件令人激動的事情。在我們通往5G——下一代無線通信系統——的道路上,工程設計社區有著數不清的挑戰和機遇。5G代表著移動技術的演進和革命,已達到無線
2019-07-11 07:48:26
,到2023年,光模塊市場整體規模將達到120億美元以上,相比2018年的60億美元翻了一倍。從測算數據可以看出,5G(無線接入)和數據中心(以太網)這兩大重點應用會推動光模塊市場迎來更大規模的發展
2019-11-07 17:23:35
,自動駕駛汽車發展迅速,各大汽車廠商都計劃到2020年左右推出旗下自動駕駛量產汽車,在這一過程中,5G技術就是最關鍵的環節之一。目前我們所熟悉的3G和4G技術,主要是將用戶通過智能手機與網絡相連。一旦通訊網
2019-05-09 01:57:59
變成5G,5G將會是一個全新技術。5G不只是一次技術的更新,更是非常大的跳躍性發展、是一個變革,這也意味著網絡架構必須提升,5G對網路的需求將與4G截然不同;雖然現在使用的4G LTE技術仍會不斷演進
2016-06-14 17:02:32
的演進與發展,XR(Extended Reality)擴展現實能夠結合AR,VR,MR技術,利用5G高速網絡與強大的算力,創造一個能夠沉浸式在虛擬世界,并與之交互的學習模式。廣和通提供5G+XR全套行業
2020-10-19 14:58:40
5G有什么優勢?4G LTE-A又如何?
2021-01-06 07:56:28
去年12月份是5G發展進程中一個激動人心的里程碑,3G合作伙伴計劃(3GPP)正式宣布5G新無線電(NR)的新標準,開啟了5G網絡全方位高性價比發展的新時代。已批準的標準包括對非獨立5G的支持,這項
2018-07-18 11:07:16
`5G作為新一代移動通信技術,在實現更優體驗的路上面臨著很多挑戰。上一期的漫畫中,麒麟君為大家解讀了麒麟發展歷程,一路克服艱辛終成“5G宗師”。 麒麟是用哪些“招式”攻克難關的?今天先為大家解讀兩招
2020-05-13 09:04:01
無人駕駛、遠程手術這些對于低時延、高可靠性有極高要求的場合。在這些領域,5G將發揮巨大的作用。”是德科技全球副總裁兼無線測試業務總經理Satish Dhanasekaran如是說。日前,第一屆“全球5G大會
2019-06-10 07:55:01
目前繁瑣的程序,通過相應的網絡門戶定制產品。 5G正式投入商業使用一年多來,正逐漸將人們對未來信息生活的想象變為現實。對消費者意味著什么?5G消費有哪些發展趨勢? 近日,全國政協經濟委員會副主任
2020-11-30 15:12:43
劃分的頻譜也有了定論,當下才是5G商用的開始……5G時代漸行漸近 萬億級市場一觸即發5G市場到底有多大,已經不是一個簡單的數字就能闡釋清楚了。5G不只惠利于移動手機,還裹挾著人工智能、云計算等技術卷席
2018-11-12 15:09:35
5G到底是什么?為什么引得一眾通訊巨頭相繼搶占先機?在這里,將用一組圖帶您梳理一下5G的發展史。在視頻、游戲霸屏移動端的今天,4G已不能滿足龐大的流量需求。4G即將成為明日黃花,5G即將接棒流量市場
2020-12-24 06:25:54
5G命令及操作
2021-02-26 06:46:29
將比4G提高10倍左右,只需要幾秒即可下載一部高清電影,能夠滿足消費者對虛擬現實、超高清視頻等更高的網絡體驗需求,另一方面,安全性上,5G具有更高的可靠性,更低的時延,能夠滿足智能制造、自動駕駛等行業應用的特定需求,拓寬融合產業的發展空間。那么,如此厲害的第五代移動通信技術,背后究竟有哪些相關技術的提升呢?
2019-07-16 07:00:20
5月17日,是中國電信日。從2G到5G時代,短短幾十年間,中國就從曾經的落后迅速跨越到了如今的領跑地位。三天前,在由工信部召開的5G、6G專題會議中透露,我國已經累計建成5G基站超81.9萬個,占
2021-07-27 07:59:37
全球首個 5G 數據連接,發出了 5G 時代 “第一聲” 。3GPP3rd Generation Partnership Project第三代合作伙伴計劃釋義:是一個成立于 1998 年 12 月
2017-12-01 09:17:58
說道通信,5G是非常火的一個詞,雖然到現在,5G標準還未完全確定,但是包括我國在內的多個國家都已經明確將第一時間(2020年或更前)開始大規模商用,中國移動和中國電信都明確了將在2018年開展
2019-01-13 15:27:48
本文主要講了什么內容?在科學技術日新月異的二十一世紀,技術更新換代速度之快已經超乎我們的想象。本文結合了國內和國外移動通信技術的發展現狀,在已經取得的成果的基礎之上,來具體介紹一下5G 移動通信天線的研究與設計。
2019-06-13 06:21:20
都有一個BBU,并通過BBU直接連到核心網。而在5G網絡中,接入網不再是由BBU、RRU、天線這些東西組成了。而是被重構為以下3個功能實體:CU(CentralizedUnit,集中單元),DU
2023-05-05 09:48:29
的是2515~2615MHz共100MHz。4G和5G有40MHz頻譜重疊會產生干擾。從原理上分析,5G對4G的干擾小于4G對5G的干擾。對于廣播信號,4G持續在一個寬波束進行發送,而5G最大支持8個窄
2020-12-03 14:03:54
互聯發展方向。要滿足面向未來業務高速率低時延的發展需求,需要采用更先進的無線傳輸技術,5G 將采用包括大規模天線陣列、超密集組網、高階調制、非正交傳輸和全雙工等關鍵技術。目前國內各通信企業及研發機構均已
2019-06-18 07:18:06
“二次開發生態圈”的構造就是一個很好開端。 科技的發展是迅速的,回顧通信技術的發展歷程,從2G至4G,到如今5G趨近也不過短短數年。時代的進步依靠技術的推進,但技術的發展從來都是自主超前的,“審時度勢
2019-07-18 17:47:47
什么是5G無線通信技術?5G通信技術的應用有哪些?
2021-05-21 06:22:15
多樣化和靈活的方式銜接許多行業(第2章) 5G如何比現有技術更有效地使用和重塑頻譜(第3章) 哪些RF通信技術使用例和路徑成為5G(第4章) 5.5G發展中尋找的重要里程碑(第5章) 在書的末尾還有一個方便的詞匯表,以防你遇到任何技術上的縮略語或概念。
2018-11-28 14:43:06
RAN 全體會議。或許在短短幾年之后,當我們回顧5G 的發展路徑時,我相信,在2017 年世界移動大會上看到的5G 宣傳變為現實的過程中,這場具體標準化會議必將被視為一個關鍵的里程碑。
2019-07-11 06:03:10
,隱藏在表面的是這個APP堅定不移的差異化道路,作為移動購物一族,什么值得買甚至一定程度上取代了淘寶、京東、唯品會這些APP而成為網購的主要入口。5G消息其實沒有選擇那么5G消息能作為什么樣的狀態存在
2020-04-16 17:55:45
一、通訊技術發展5G——天下武功,唯快不破!在移動互聯網時代,最核心的技術是移動通信技術。而在通信行業,標準之爭是最高話語權的爭奪。一旦標準確立,將對全球通信產業產生巨大影響。縱觀世界通訊技術發展
2018-02-01 11:40:15
的5G,基本上是一邊試驗,一邊定標準,一邊尋找合適的解決方案。而且現在國內的5G發展跟國外基本一致,有些方面甚至會更快一點。”MACOM光子學技術營銷總監楊石泉在18年光博會期間談論到5G時就曾表示
2019-01-22 11:22:59
全球4.5G正在呈加快部署的趨勢,預計2020年(5G開始商用部署)左右在相當長的一段時間會出現“千兆LTE與5G并存”的局面。對于運營商來說,中國聯通技術專家表示,首先要立足當前,不斷提升4.5G
2017-08-22 10:52:23
建設網絡、調整運營策略,就變成了新的挑戰和任務。5G的兼容性也可以把終端生產廠商統一到一個平臺上,不同制式、規格的無線終端將被集成,這為全球的通信發展制定了統一的道路。在5G通信技術發展的道路上,中國
2016-12-21 18:32:37
vivo 5G研發部招聘招聘崗位:5G驗證平臺開發工程師招聘類型:社會招聘,待遇從優,具體面議工作地點:北京職位要求:(1)精通xilinx公司FPGA設計流程;(2)精通VHDL或者Verilog
2018-01-12 15:08:46
`5G技術,蘊含著一個巨大的市場機遇,這已經是一個全球共識了。對此,全球范圍內的科技產業正跑馬圈地、摩拳擦掌,科技企業們也時刻緊盯著5G網絡的消息,以便搶在紅利到來前奪得頭籌。在長達數年的備戰和模擬
2018-08-27 16:59:18
5G即將改變社會,在這場跨時代的變革中,中國市場的重要性逐漸提升。在此過程中,中國的運營商尤其是中國移動在5G發展過程中起到了重要作用,中國移動立足長遠、投入巨大、發奮攻堅,在標準、技術、建網、應用等領域勇作5G發展的“火車頭”,在推動中國5G發展過程中貢獻了重要力量。
2020-12-18 06:14:21
網絡行業興奮不已,但現實是5G超越增強型移動寬帶的整體發展是一項長期的任務,有關5G的標準,法規和安全等工作都還有待完成! 在5G時代下,網絡安全已經成為世界各國關注的重點,是網絡安全的重中之重
2020-01-02 19:27:09
新電臺。高通評論說,NR是一個復雜的話題,因為它涉及到一種新的基于OFDM的無線標準。圖1 5G無線接入架構由LTE演進和新的無線接入技術(NR)組成,它與LTE不向后兼容,可從1GHz到100GHz工作
2017-05-03 11:34:31
倍;加上由于5G技術度提升,預期5G單基站價值量相比4G基站有所提升,造成5G基站呈現“價量齊升”的發展。
2019-09-17 08:02:52
5G技術方興未艾,各種候選技術獲得業界的廣泛關注。本文結合高頻技術在5G中的應用場景和關鍵技術,介紹了愛立信開發的5G高頻無線空口測試床,分享了在中國5G技術研發試驗第一階段的測試結果,分析并總結了5G高頻技術的出色表現。
2019-08-16 07:27:48
什么是5G4G必須被5G替代嗎?5G到底有多快?5G還會帶來什么其他的改變?5G多久才會來?5G來了我們要不要換手機卡?5G到來,資費會不會是天價?
2020-12-18 06:44:12
本人對5G不是太了解,請教論壇師傅,5G產品制造過程需要經過哪些測試項目?比如PCB板或組裝好整機的哪方面測試?
2019-05-21 15:05:59
第三階段“基于獨立組網的5G核心網關鍵技術與業務流程測試”。這三個階段測試,華為均以100%通過率順利完成。除了三大關鍵技術之外,無數用戶要組成網絡,事情自然少不了。比如,分配傳輸資源和指揮交通一樣讓
2019-04-22 21:33:23
進行試驗。如果按28GHz來算,根據前文我們提到的公式:這個就是5G的第一個技術特點——最下面一行,就是“毫米波”既然,頻率高這么好,你一定會問:“為什么以前我們不用高頻率呢?”不是不想用,是用不起
2019-03-07 15:00:11
本文對5G生態鏈中的五個產業進行分析,詳細梳理當前國內外5G核心產業鏈的發展情況。 5G技術的快速發展正在推動包括通信、電子元器件、芯片、終端應用等全產業鏈的升級。從上游基站射頻、基帶芯片等到中游網
2020-12-22 06:18:04
如何對RK3288 5G WIFI及5G熱點進行調試?
2022-03-03 06:31:08
還有一個重要的原因,就是現有4G網絡的通訊能力大大限制了物聯網產業的發展。現有的4G網絡還是無法很好的滿足車聯網、智能家居、智慧醫療、智能工業以及智慧城市等多方面的需要。 相對于4G網絡,5G具備
2018-04-12 17:18:11
我使用控制臺項目來測試兩個CYW43907 EVKS中的WiFi性能。一個是AP,另一個是STA。如果我想在AP和STA之間進行5G的測試,我應該設置命令嗎?我猜想,在StaseTap AP命令中
2018-11-27 11:17:15
私募基金支持下一個發展新動能:5G 時代來臨
2021-01-05 07:00:28
9月7日,全球第一個5G電話正式撥打成功。據了解,該電話是愛立信與高通合作,利用一款智能手機外形的移動設備,在愛立信位于瑞典希斯塔的實驗室打出的。據悉,這次呼叫是基于39GHz毫米波頻段及非獨
2018-09-11 08:18:22
日前,愛立信推出一款無線小蜂窩產品——5G無線點系統,支持5G中頻頻段(3-5GHz),支持速率達2Gbps。愛立信表示,隨著用戶流量需求倍增,4K、8K、VR/AR等應用的到來,5G時代室內移動
2019-08-16 08:02:38
更是層出不窮,迫切需要更加高速、更加高效、更加智能化的新一代無線移動通信技術來支撐。因此,在全球第4代移動通信(4G)網絡的部署方興未艾之時,第5代移動通信技術(5G,fifth- generation
2019-08-16 07:52:39
為搶抓新一輪科技革命和產業變革機遇,加快推動我市5G(第五代移動通信技術)產業發展,培育新經濟、形成新動能,促進網絡強市建設,特制定本方案。
2020-12-18 06:55:11
QPD0005:推動5G發展的高效GaN RF晶體管隨著5G技術的迅猛發展,通信行業對高性能射頻(RF)器件的需求日益增加。Qorvo推出的QPD0005是一款48伏特、8瓦特的GaN RF晶體管
2024-11-11 20:06:21
4G改變生活,5G改變社會。當下,“5G”無疑是最熱門的概念,各行各業都在關注著5G的發展。其中,智能家居因為其技術屬性和產品特點,成為了各個企業用來摸索5G道路的試金石。
2019-08-11 10:21:34 1129
1129 FPGA是5G基礎設施和終端設備的零部件,5G全球部署持續推進,基站、IoT、 終端設備、邊緣計算的FPGA用量將顯著提升。通信是FPGA下游應用場景中規模最大的分支,根據MRFR的數據,FPGA
2019-10-10 14:52:47933 近日,由中國通信企業協會網絡運維專委會和上海觸界科技主辦的2018(第三屆)全球預商用5G產業峰會在上海成功舉辦,大會以5G商用蓄勢待發”為主題,就5G商用化的前景進行了激烈討論。 Corvo大客戶高級銷售 James Huang也受邀演講,闡述了5G發展道路中那些繞不開的射頻關鍵技術。
2020-07-30 10:27:00 0
0 5G作為新基建的關鍵技術之一,為城市智慧交通發展按下“加速鍵”。6月6日,距離5G商用牌照發放已2周年,產業發展進程如何?6月7日,中國電動汽車百人會副理事長兼秘書長、首席專家張永偉受邀出席財新網
2021-06-23 17:36:152124 為保障高速道路交通高速、安全運行,高速道路沿線部署有控制設施、監視設施、情報設施、傳輸設施、顯示設施及控制中心等,其中傳輸設施一般采用光纖線纜進行傳輸。隨著運營商5G基礎設施的推廣,其高帶寬、低時延
2022-11-16 16:43:131357 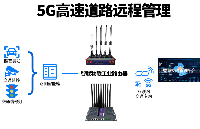
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論