") DeepSeek V3.1發(fā)布!擁抱國產(chǎn)算力芯片
DeepSeek V3.1發(fā)布!擁抱國產(chǎn)算力芯片

電子發(fā)燒友網(wǎng)報道(文/李彎彎)2025年8月21日,DeepSeek正式官宣發(fā)布DeepSeek-V3.1大模型。新版本不僅在技術(shù)架構(gòu)上實(shí)現(xiàn)重大升級,更通過參數(shù)精度優(yōu)化與國產(chǎn)芯片深度適配。從混合推理架構(gòu)到Agent能力突破,從API價格調(diào)整到國產(chǎn)芯片生態(tài)共建,DeepSeek V3.1的發(fā)布標(biāo)志著中國AI產(chǎn)業(yè)進(jìn)入技術(shù)突破與產(chǎn)業(yè)落地協(xié)同發(fā)展的新階段。

圖:DeepSeek正式發(fā)布DeepSeek-V3.1(來自DeepSeek官微)
DeepSeek V3.1的技術(shù)突破與生態(tài)升級
DeepSeek V3.1的核心創(chuàng)新在于混合推理架構(gòu)的規(guī)模化應(yīng)用。該架構(gòu)首次實(shí)現(xiàn)單一模型同時支持思考模式與非思考模式:在思考模式下,模型通過深度推理提升復(fù)雜任務(wù)處理能力;在非思考模式下,則通過精簡計算路徑實(shí)現(xiàn)高效響應(yīng)。測試數(shù)據(jù)顯示,V3.1-Think在輸出token數(shù)減少20%-50%的情況下,各項任務(wù)平均表現(xiàn)與前代R1-0528持平,而非思考模式的輸出長度控制能力則幫助用戶降低使用成本。
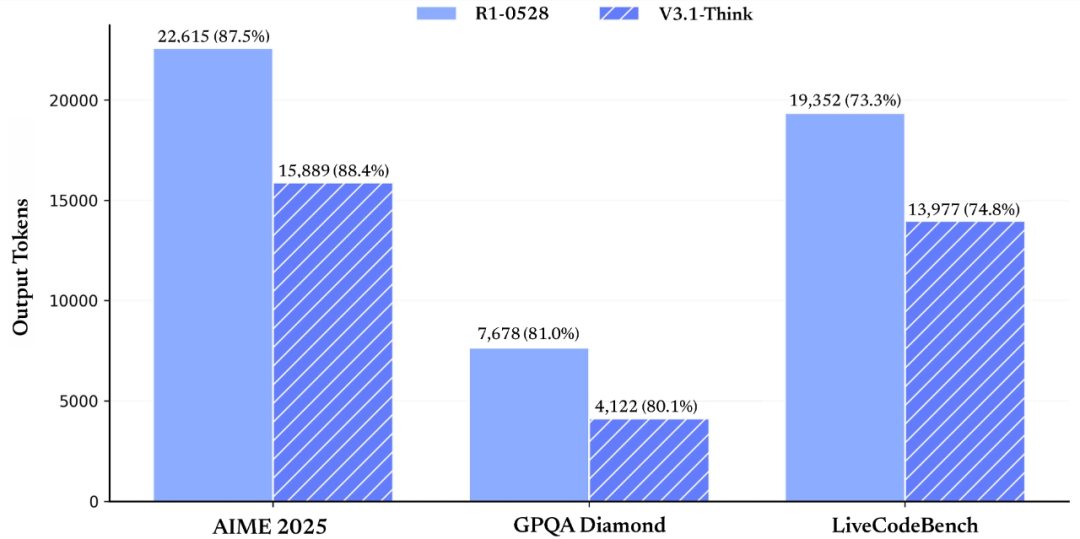
圖:在各項評測指標(biāo)得分基本持平的情況下(來自DeepSeek官微)
參數(shù)精度優(yōu)化是另一重大突破。V3.1采用UE8M0 FP8 Scale技術(shù),將參數(shù)精度提升至8位浮點(diǎn)數(shù)規(guī)模。這一設(shè)計不僅減少30%的內(nèi)存占用,更通過量化感知訓(xùn)練保持模型精度。DeepSeek官方透露,UE8M0 FP8標(biāo)準(zhǔn)是專為下一代國產(chǎn)芯片設(shè)計的計算范式,可顯著提升芯片在AI推理場景下的能效比。

FP8是Float8的簡稱,即用8位二進(jìn)制數(shù)表示浮點(diǎn)數(shù),主要用于深度學(xué)習(xí)的訓(xùn)練和推理。相比傳統(tǒng)的FP32(32位浮點(diǎn)數(shù))或FP16(16位浮點(diǎn)數(shù)),F(xiàn)P8顯著降低了顯存占用和計算資源需求,同時通過優(yōu)化設(shè)計(如動態(tài)范圍調(diào)整)維持了較高的精度。??FP8對國產(chǎn)芯片的使用效率提升顯著,將進(jìn)一步縮小與NVIDIA芯片的效率/成本差距,大大增加國產(chǎn)芯片的可用性。
在Agent能力方面,V3.1通過Post-Training優(yōu)化實(shí)現(xiàn)質(zhì)的飛躍。在代碼修復(fù)測評 SWE 與命令行終端環(huán)境下的復(fù)雜任務(wù)(Terminal-Bench)測試中,DeepSeek-V3.1 相比之前的 DeepSeek 系列模型有明顯提高。DeepSeek-V3.1 在多項搜索評測指標(biāo)上取得了較大提升。在需要多步推理的復(fù)雜搜索測試(browsecomp)與多學(xué)科專家級難題測試(HLE)上,DeepSeek-V3.1 性能已大幅領(lǐng)先 R1-0528。官方將其定義為“邁向Agent時代的第一步”。
生態(tài)建設(shè)同步加速。官方App與網(wǎng)頁端同步升級V3.1,用戶可通過“深度思考”按鈕自由切換模式。API接口價格自9月6日起調(diào)整為輸入每百萬tokens 0.5元(緩存命中)/4元(未命中),輸出每百萬tokens 12元,同時取消夜間優(yōu)惠。盡管價格有所上調(diào),但輸入緩存命中成本保持不變,輸出成本增幅控制在50%以內(nèi),體現(xiàn)技術(shù)優(yōu)化帶來的成本分?jǐn)傂?yīng)。
國產(chǎn)芯片適配進(jìn)程:從技術(shù)追趕到生態(tài)共建
DeepSeek與國產(chǎn)芯片的協(xié)同發(fā)展。2025年1月,華為昇騰910B率先完成V3模型適配,通過自研推理加速引擎使模型性能達(dá)到高端GPU水平,在智能安防、工業(yè)物聯(lián)網(wǎng)等端側(cè)場景實(shí)現(xiàn)本地化決策。2月,海光DCU完成V3與R1模型適配,其GPGPU架構(gòu)支持全精度通用AI加速,通信延遲降低40%,訓(xùn)練效率提升35%。同月,龍芯中科發(fā)文稱,搭載龍芯3號 CPU 的設(shè)備成功運(yùn)行DeepSeek R1 7B模型,實(shí)現(xiàn)本地化部署。
多芯片廠商形成差異化競爭格局。沐曦曦云C500 GPU在V3推理中性能達(dá)國際主流產(chǎn)品的110%-130%,單位token成本僅為H100的70%;天數(shù)智芯支持R1千問蒸餾模型,提供穩(wěn)定推理服務(wù);壁仞科技壁礪系列覆蓋1.5B至70B參數(shù)規(guī)模的全系列蒸餾模型。摩爾線程成為首個支持原生FP8的國產(chǎn)GPU廠商,其MUSA架構(gòu)為V3.1提供原生計算支持;芯原股份NPU芯原VIP9000實(shí)現(xiàn)FP8技術(shù)從云端訓(xùn)練到硬件部署的快速遷移。
政策與市場形成雙輪驅(qū)動。國家超算互聯(lián)網(wǎng)平臺將DeepSeek模型納入標(biāo)準(zhǔn)算力庫,三大運(yùn)營商在5G基站部署中優(yōu)先采用適配國產(chǎn)芯片的AI推理模塊。
在能源行業(yè)私有化部署實(shí)踐中,中國石油、中國海油、國家管網(wǎng)等央企已完成DeepSeek私有化部署,中國海油采用全國產(chǎn)化算力,在“海能”人工智能模型平臺接入DeepSeek系列模型,通過私有化部署面向全集團(tuán)提供開放服務(wù)。電網(wǎng)故障預(yù)測響應(yīng)時間從分鐘級壓縮至秒級,需結(jié)合實(shí)時數(shù)據(jù)采集、高速算力支撐和智能算法優(yōu)化,海光DCU的低延遲計算能力與DeepSeek模型的實(shí)時推理能力相結(jié)合,可滿足這一需求。
重構(gòu)中國AI產(chǎn)業(yè)競爭力
技術(shù)突破顯著降低硬件門檻。DeepSeek通過MoE架構(gòu)將激活參數(shù)量控制在合理范圍,V3.1的UE8M0 FP8精度標(biāo)準(zhǔn)使國產(chǎn)芯片在推理場景下的能效比提升40%。實(shí)測顯示,在671B參數(shù)規(guī)模下,沐曦曦云C500運(yùn)行V3的單位算力成本較H100降低35%,推理延遲縮短至8ms以內(nèi)。龍芯芯片在適配DeepSeek后,也憑借其架構(gòu)優(yōu)勢,在特定場景下實(shí)現(xiàn)了較低的功耗和較高的性價比,為國產(chǎn)AI應(yīng)用的普及提供了更多選擇。
生態(tài)共建加速產(chǎn)業(yè)落地進(jìn)程。華為云昇騰算力服務(wù)已承載超過7萬顆910B芯片,訂單價值超20億美元;海光DCU在金融行業(yè)市占率突破28%,其適配的DeepSeek模型日均調(diào)用量達(dá)4.7億次。龍芯在完成適配后,積極與眾多軟件廠商和系統(tǒng)集成商展開合作,推動基于龍芯芯片和DeepSeek模型的解決方案在更多行業(yè)落地。例如,在一些教育領(lǐng)域的智能教學(xué)系統(tǒng)中,龍芯芯片與DeepSeek模型結(jié)合,實(shí)現(xiàn)了智能答疑、個性化學(xué)習(xí)推薦等功能,提升了教學(xué)質(zhì)量和效率。
技術(shù)差距縮短在具體領(lǐng)域表現(xiàn)突出。華為昇騰910C在推理性能上達(dá)到H100的60%,能效比優(yōu)于后者;沐曦曦云C500成為首個支持70B參數(shù)大模型單卡推理的國產(chǎn)GPU。龍芯芯片在不斷研發(fā)和優(yōu)化過程中,性能也在逐步提升,在一些特定的AI應(yīng)用場景中,已經(jīng)能夠滿足基本的需求,為中國在AI算力芯片等關(guān)鍵領(lǐng)域的自主化率提升貢獻(xiàn)了力量。
寫在最后
站在2025年的節(jié)點(diǎn)回望,DeepSeek V3.1的發(fā)布不僅是單一產(chǎn)品的迭代,更是中國AI產(chǎn)業(yè)生態(tài)重構(gòu)的縮影。從技術(shù)參數(shù)的優(yōu)化到產(chǎn)業(yè)生態(tài)的共建,從芯片算力的突破到應(yīng)用場景的落地,中國AI正在走出一條不同于國際巨頭的自主化道路。隨著UE8M0 FP8標(biāo)準(zhǔn)成為行業(yè)新范式,隨著“模型+芯片+應(yīng)用”生態(tài)的持續(xù)完善,中國AI產(chǎn)業(yè)有望在2030年前實(shí)現(xiàn)全球競爭力的實(shí)質(zhì)性躍升。
發(fā)布評論請先 登錄
華為領(lǐng)銜,三劍客入局!十萬卡智算集群落地,國產(chǎn)算力芯片強(qiáng)勢崛起

百度騰訊搶灘布局!DeepSeek-R1升級和開源背后,國產(chǎn)AI的逆襲之路
國產(chǎn)算力出海元年開啟

國產(chǎn)算力生態(tài)擁抱開源AI智能體:光合組織全國OpenClaw體驗(yàn)“龍蝦局”正式啟動

重磅更新 | 先楫半導(dǎo)體HPM_APPS v1.10.1發(fā)布


國產(chǎn)AI芯片真能扛住“算力內(nèi)卷”?海思昇騰的這波操作藏了多少細(xì)節(jié)?
擁抱DeepSeek開源生態(tài)| 算能TPU接入TileLang,集結(jié)北大復(fù)旦山大頂尖團(tuán)隊!

商湯大裝置算力Mall重磅發(fā)布
借勢 RISC-V與 AI 浪潮,元石智算打造算力新范式

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】+NVlink技術(shù)從應(yīng)用到原理
AIGC算力基礎(chǔ)設(shè)施技術(shù)架構(gòu)與行業(yè)實(shí)踐
重磅更新 | 先楫半導(dǎo)體HPM_APPS v1.9.0發(fā)布



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論