 用 ERNIE 4.5 與 PaddleOCR 3.0 實現文檔翻譯實踐指南
用 ERNIE 4.5 與 PaddleOCR 3.0 實現文檔翻譯實踐指南

一, 文檔翻譯的挑戰
在全球化背景下,跨語言溝通需求日益增長,文檔翻譯的重要性愈發凸顯。尤其是隨著數字化進程加速,文檔圖像翻譯的需求持續上升,但這一任務面臨著獨特的挑戰:復雜布局解析
文檔圖像常包含文本、圖表、表格等多種元素,傳統OCR技術在處理復雜布局時難以準確提取文本并保留原始格式多語言翻譯質量
不同語言間存在語法、詞匯和文化背景差異,長句和上下文依賴翻譯任務對傳統工具而言頗具難度格式保留
翻譯過程中如何保持文檔的原始結構和格式,是用戶面臨的另一大痛點
你是否曾因這些問題而困擾?本文將介紹如何利用PaddleOCR 3.0
https://github.com/paddlepaddle/paddleocr
和ERNIE 4.5
https://github.com/PaddlePaddle/ERNIE
實現高質量的文檔翻譯解決方案。
二,PaddleOCR 3.0與ERNIE 4.5簡介
PaddleOCR 3.0
PaddleOCR 3.0是業界領先、可直接部署的 OCR 與文檔智能引擎,提供從文本識別到文檔理解的全流程解決方案,提供了全場景文字識別模型PP-OCRv5、復雜文檔解析PP-StructureV3和智能信息抽取PP-ChatOCRv4,其中PP-StructureV3在布局區域檢測、表格識別和公式識別方面能力尤為突出,還增加了圖表理解、恢復多列閱讀順序以及將結果轉換為Markdown文件的功能。
ERNIE 4.5
ERNIE 4.5是百度發布的開源多模態和大語言系列,含10種版本,最大達424B參數,采用創新MoE架構,支持跨模態共享與專用參數,在文本與多模態任務中表現領先。通過結合PP-StructureV3的文檔分析能力和ERNIE 4.5的翻譯能力,我們可以構建一個端到端的高質量文檔翻譯解決方案。
三,解決方案概述
本文介紹的文檔翻譯方案基于以下核心流程:
1,使用PP-StructureV3分析文檔內容,獲取結構化數據表示
2,將結構化數據處理為Markdown格式的文檔文件
3,利用提示工程構建提示,調用ERNIE 4.5翻譯文檔內容
這種方法不僅能準確識別和分析復雜文檔布局,還能實現高質量的多語言翻譯服務,滿足用戶在不同語言環境下的文檔翻譯需求。
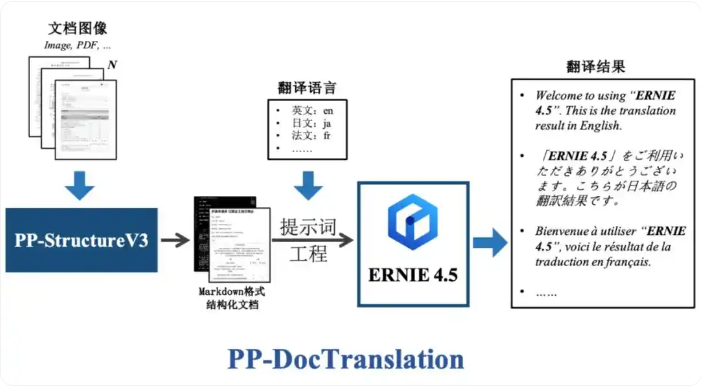
四,快速上手
步驟1:環境準備
首先需要安裝PaddlePaddle框架和PaddleOCR:
# 安裝PaddlePaddle GPU版本 python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/ # 安裝PaddleOCRpip install paddleocr # 安裝OpenAI SDK用于測試模型可用性 pip install openai
步驟2:部署ERNIE 4.5服務
ERNIE大語言模型通過服務請求訪問,需要部署為本地服務。可以使用FastDeploy工具部署ERNIE模型。部署完成后,測試服務可用性:
# 測試ERNIE服務可用性 # 請填寫本地服務的URL,例如:http://0.0.0.0:8000/v1 ERNIE_URL = "" try: import openai client = openai.OpenAI(base_url=ERNIE_URL, api_key="api_key") question = "你是誰?" response1 = client.chat.completions.create( model="ernie-4.5", messages=[{"role": "user", "content": question}] ) reply = response1.choices[0].message.content print(f"測試成功!n問題:{question}n回答:{reply}") except Exception as e: print(f"測試失敗!錯誤信息:n{e}")
步驟3:文檔解析與翻譯
# 文檔翻譯示例代碼 from paddleocr import PPDocTranslation # 配置參數 input_path = "path/to/your/document.pdf" # 文檔圖像路徑 output_path = "./output/" # 結果保存路徑 target_language = "zh" # 目標語言(中文) # 初始化PP-DocTranslation pipeline translation_engine = PPDocTranslation( use_doc_orientation_classify=False, # 是否使用文檔方向分類模型 use_doc_unwarping=False, # 是否使用文檔扭曲校正模型 use_seal_recognition=True, # 是否使用印章識別模型 use_table_recognition=True # 是否使用表格識別模型 ) # 解析文檔圖像 visual_predict_res = translation_engine.visual_predict(input_path) # 處理解析結果 ori_md_info_list = [] for res in visual_predict_res: layout_parsing_result = res["layout_parsing_result"] ori_md_info_list.append(layout_parsing_result.markdown) layout_parsing_result.save_to_img(output_path) layout_parsing_result.save_to_markdown(output_path)# 如果是PDF文件,拼接多頁結果if input_path.lower().endswith(".pdf"): ori_md_info = translation_engine.concatenate_markdown_pages(ori_md_info_list) ori_md_info.save_to_markdown(output_path) # 配置ERNIE服務 chat_bot_config = { "module_name": "chat_bot", "model_name": "ernie-4.5", "base_url": ERNIE_URL, # 填寫ERNIE服務URL "api_type": "openai", "api_key": "api_key" } # 調用ERNIE進行翻譯 print("開始翻譯文檔...") tgt_md_info_list = translation_engine.translate( ori_md_info_list=ori_md_info_list, target_language=target_language, chunk_size=3000, # 文本分塊大小 chat_bot_config=chat_bot_config, ) # 保存翻譯結果 for tgt_md_info in tgt_md_info_list: tgt_md_info.save_to_markdown(output_path) print(f"翻譯完成,結果保存在:{output_path}")
完成代碼范例,請參見Document Translation Practice Based on ERNIE 4.5 and PaddleOCR。
https://github.com/PaddlePaddle/ERNIE/blob/develop/cookbook/notebook/document_translation_tutorial_en.ipynb
五,運行示例翻譯結果
下圖展示了翻譯效果示例(左側為原始英文PDF論文圖像,右側為翻譯后的中文Markdown文件):

六,常見問題與調試
常見問題
1,Q: 安裝PaddlePaddle時遇到CUDA版本不匹配問題? A: 請確保CUDA版本與PaddlePaddle版本兼容。可以參考PaddlePaddle官方安裝指南選擇合適的版本。
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
2,Q: 調用ERNIE服務時出現連接超時?A: 檢查ERNIE服務是否正常運行,網絡連接是否暢通。可以嘗試重啟服務或增加超時設置。
3,Q: 文檔解析結果中表格格式丟失?A: 確保use_table_recognition參數設置為True。對于復雜表格,可能需要調整表格識別模型的參數。
4,Q: 翻譯結果質量不高?A: 嘗試調整chunk_size參數,確保文本塊大小合適。對于專業領域文檔,可以提供領域詞匯表作為提示的一部分。
調試技巧逐步驗證
1,從單頁簡單文檔開始測試,確認每個步驟正常工作后再處理復雜文檔日志輸出
2,在關鍵步驟添加日志,記錄處理時間和結果狀態版本兼容
3,確保PaddlePaddle、PaddleOCR和其他依賴庫的版本兼容可視化檢查
4,利用save_to_img功能保存解析過程中的圖像,直觀檢查問題所在
七,總結
通過本文介紹的方法,你可以快速構建一個高質量的文檔翻譯系統,滿足不同場景下的文檔翻譯需求。無論是學術論文、技術文檔還是商業報告,都能得到準確、流暢的翻譯結果。該系統能夠處理復雜的文檔結構,如表格、圖表等,同時保持翻譯質量。
審核編輯 黃宇
-
語言模型
+關注
關注
0文章
571瀏覽量
11310
發布評論請先 登錄
清華大學電子工程系“無問錫東3.0”實踐支隊走進沐曦股份
沐曦曦云C500/C550 GPU產品適配PaddleOCR-VL-1.5模型

百度正式發布并開源新一代文檔解析模型PaddleOCR-VL-1.5

IGBT關鍵特性參數的應用實踐指南 v3.0

固態斷路器參考設計用戶指南:從原理到實踐
使用 Docker 一鍵部署 PaddleOCR-VL: 新手保姆級教程

精準定位性能瓶頸:深入解析 PaddleOCR v3.2 全新 Benchmark 功能
小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰解析
【EASY EAI Orin Nano開發板試用體驗】PP-OCRV5文字識別實例搭建與移植
IGBT關鍵特性參數應用實踐筆記 v3.0
Say Hi to ERNIE!Imagination GPU率先完成文心大模型的端側部署

創惟GL3213S與國產DD3118在USB3.0讀卡器方案中BOM對比
抖膽DD3118高性價比USB3.0讀卡器芯片方案-替代創惟GL3213S
CYUSB3014無法識別為USB3.0設備怎么解決?
《恩智浦FRDM-MCXA156開發實踐指南》上線啦




 工商網監
工商網監
評論