 NVMe高速傳輸之擺脫XDMA設計15:PCIe的TLP讀處理
NVMe高速傳輸之擺脫XDMA設計15:PCIe的TLP讀處理

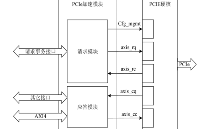
對于存儲器讀請求TLP,使用Non-Posted方式傳輸,即在接收到讀請求后,不僅要進行處理,還需要通過axis_cc總線返回CPLD,這一過程由讀處理模塊執行,讀處理模塊的結構如圖1所示。
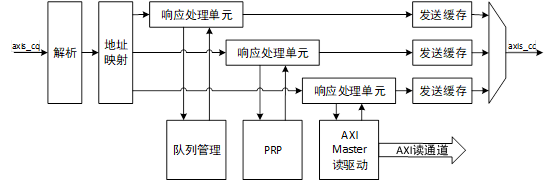
圖1 讀處理模塊的結構圖
當axis_cq總線接收到存儲器讀請求時,數據流被轉發到讀處理模塊。讀請求TLP只包含128比特的請求報頭,而axis總線位寬也是128比特,因此在短時間內可能接收到多個讀請求,為了應對這種情況,讀處理模塊采用了帶有outstanding能力和事務并行處理的結構設計,能夠有效提高讀請求事務處理效率和數據傳輸吞吐量。
首先當讀請求數據流到達讀處理模塊時,經過解析和地址映射的兩級流水后,放入響應處理單元outstanding緩存中,響應處理單元從緩存中獲取事務一一處理,將讀取的數據打包成CPLD,并將CPLD放置到發送緩存中等待axis_cc總線的發送。根據地址的不同,讀請求事務被分為三類,分別是讀隊列請求,讀PRP請求和讀數據請求,每種請求對應一個響應處理單元。
B站已給出相關性能的視頻,如想進一步了解,請搜索B站用戶:專注與守望
鏈接:https://space.bilibili.com/585132944/dynamic?spm_id_from=333.1365.list.card_title.click
審核編輯 黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
PCIe
+關注
關注
16文章
1460瀏覽量
88402 -
TLP
+關注
關注
0文章
37瀏覽量
16476 -
nvme
+關注
關注
0文章
298瀏覽量
23839
發布評論請先 登錄
相關推薦
熱點推薦
NVMe高速傳輸之擺脫XDMA設計30: NVMe 設備模型設計
, 不同的是在處理指令過程中, NVMe 寫和讀指令需要與主機進行更多的 TLP 事務交互, 包括讀指令、 讀寫數據、
發表于 09-29 09:31
NVMe高速傳輸之擺脫XDMA設計21:PCIe的TLP讀處理
對于存儲器讀請求TLP,使用Non-Posted方式傳輸,即在接收到讀請求后,不僅要進行處理,還需要通過axis_cc總線返回CPLD,這一
發表于 08-14 16:24
NVMe高速傳輸之擺脫XDMA設計20: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據傳輸只使用
NVMe高速傳輸之擺脫XDMA設計20: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據傳輸只使用
發表于 08-12 16:04
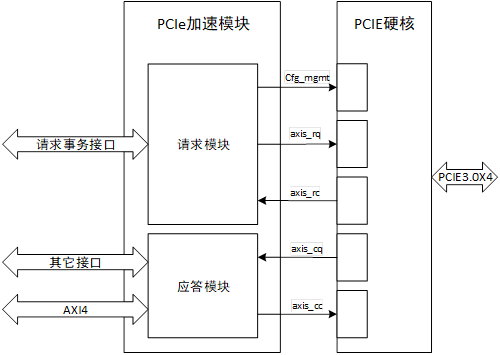
NVMe高速傳輸之擺脫XDMA設計17:PCIe加速模塊設計
PCIe加速模塊負責實現PCIe傳輸層任務的處理,同時與NVMe層進行任務交互。PCIe加速模塊
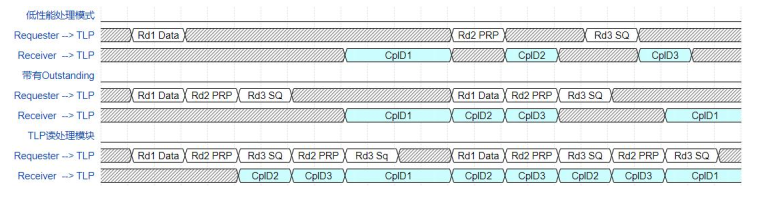
NVMe高速傳輸之擺脫XDMA設計16:TLP讀處理優化
的延時。并且當大量不同的讀請求交叉處理時,讀處理模塊的并行處理結構更能夠充分利用PCIe的亂序
NVMe高速傳輸之擺脫XDMA設計15:PCIe的TLP讀處理
對于存儲器讀請求TLP,使用Non-Posted方式傳輸,即在接收到讀請求后,不僅要進行處理,還需要通過axis_cc總線返回CPLD,這一
發表于 08-04 16:54
NVMe高速傳輸之擺脫XDMA設計14: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據傳輸只使用
NVMe高速傳輸之擺脫XDMA設計14: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據傳輸只使用
發表于 08-04 16:44
NVMe高速傳輸之擺脫XDMA設計13:PCIe請求模塊設計(下)
狀態下組裝讀請求TLP報頭通過axis_rq接口發送,當接口握手時跳轉到RD_DATA狀態。
RD_DATA:請求讀CPLD接收狀態。該狀態下監測axis_rc接口信號,當出現數據傳輸
發表于 08-04 16:39
NVMe IP高速傳輸卻不依賴XDMA設計之二:PCIe讀寫邏輯
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據傳輸只使用



 工商網監
工商網監
評論