") NVMe IP高速傳輸卻不依賴XDMA設(shè)計之二:PCIe讀寫邏輯
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之二:PCIe讀寫邏輯

NVMe IP放棄XDMA原因
選用XDMA做NVMe IP的關(guān)鍵傳輸模塊,可以加速IP的設(shè)計,但是XDMA對于開發(fā)者來說,還是不方便,原因是它就象一個黑匣子,調(diào)試也非一番周折,尤其是后面PCIe4.0升級。因此決定直接采用PCIe設(shè)計,雖然要費(fèi)一番周折,但是目前看,還是值得的,我們uvm驗證也更清晰。
PCIe 寫應(yīng)答模塊設(shè)計
應(yīng)答模塊的具體任務(wù)是接收來自PCIe鏈路上的設(shè)備的TLP請求,并響應(yīng)請求。由于基于PCIe協(xié)議的NVMe數(shù)據(jù)傳輸只使用PCIe協(xié)議的存儲器讀請求TLP和存儲器寫請求TLP,應(yīng)答模塊分別針對兩種TLP設(shè)置處理引擎來提高并行性和處理速度。
對于存儲器寫請求TLP,該類型的TLP使用Posted方式傳輸,即不需要返回完成報文,因此只需要接收并做處理,這一過程由寫處理模塊來執(zhí)行,寫處理模塊的結(jié)構(gòu)如圖1所示。

圖1 TLP寫處理結(jié)構(gòu)
當(dāng)axis_cq 總線中出現(xiàn)數(shù)據(jù)流傳輸時,應(yīng)答模塊首先對傳輸?shù)腡LP報頭的類型字段進(jìn)行解析,如果為存儲器寫請求則由寫處理模塊進(jìn)一步解析。寫處理模塊提取出TLP 報頭的地址字段、長度字段等,然后將數(shù)據(jù)字段寫入數(shù)據(jù)緩存中。提取出的地址字段用于進(jìn)行地址映射,在NVMe協(xié)議中,設(shè)備端的請求寫分為兩種,分別是寫完
成隊列和寫數(shù)據(jù),因此地址映射的定向?qū)?yīng)為隊列管理模塊的完成條目處理單元和數(shù)據(jù)傳輸AXI總線的寫通道。完成條目的字段長度為128比特,因此無需進(jìn)行數(shù)據(jù)緩存,跟隨地址映射發(fā)送到隊列管理模塊。AXIMaster驅(qū)動負(fù)責(zé)將解析的字段與緩存的數(shù)據(jù)組成AXI寫傳輸事務(wù)發(fā)送到AXI寫通道,實(shí)現(xiàn)數(shù)據(jù)的寫傳輸。
PCIe 讀應(yīng)答模塊設(shè)計
對于存儲器讀請求TLP,使用Non-Posted方式傳輸,即在接收到讀請求后,不僅要進(jìn)行處理,還需要通過axis_cc總線返回CplD,這一過程由讀處理模塊執(zhí)行,讀處理模塊的結(jié)構(gòu)如圖2所示。
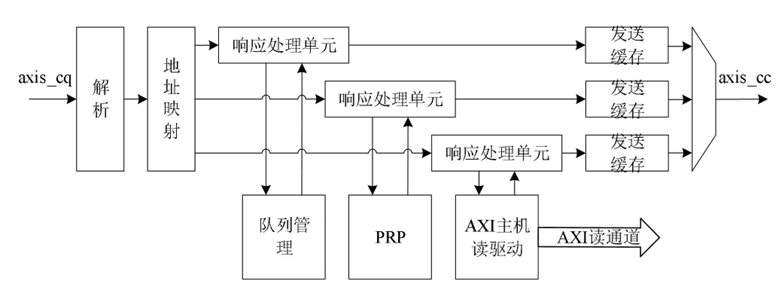
圖2 TLP讀處理模塊結(jié)構(gòu)
當(dāng)axis_cq 總線接收到存儲器讀請求時,數(shù)據(jù)流被轉(zhuǎn)發(fā)到讀處理模塊。讀請求TLP只包含128比特的請求報頭,而axis總線位寬也是128比特,因此在短時間內(nèi)可能接收到多個讀請求,為了應(yīng)對這種情況,讀處理模塊采用了帶有outstanding能力和事務(wù)并行處理的結(jié)構(gòu)設(shè)計,能夠有效提高讀請求事務(wù)處理效率和數(shù)據(jù)傳輸吞吐量。
首先當(dāng)讀請求數(shù)據(jù)流到達(dá)讀處理模塊時,經(jīng)過解析和地址映射的兩級流水后,放入響應(yīng)處理單元outstanding 緩存中,響應(yīng)處理單元從緩存中獲取事務(wù)一一處理,將讀取的數(shù)據(jù)打包成CplD,并將CplD放置到發(fā)送緩存中等待axis_cc總線的發(fā)送。根據(jù)地址的不同,讀請求事務(wù)被分為三類,分別是讀隊列請求,讀PRP請求和讀數(shù)據(jù)請求,每種請求對應(yīng)一個響應(yīng)處理單元。
在實(shí)際應(yīng)用環(huán)境中,由于隊列、PRP、數(shù)據(jù)的存儲往往在不同的位置,因此完成讀取過程的延遲也不同,在本課題中,將隊列管理與PRP都放置在了近PCIe端存儲,因此讀取隊列與PRP的延遲遠(yuǎn)遠(yuǎn)小于讀取數(shù)據(jù)的延遲。并且當(dāng)大量不同的讀請求交叉處理時,讀處理模塊的并行處理結(jié)構(gòu)更能夠充分利用PCIe的亂序傳輸能力來提高
吞吐量。為了清晰的說明讀處理模塊對吞吐量的提升,設(shè)置如圖3所示的簡單時序樣例,樣例中PCIeTLP的tag最大為3。
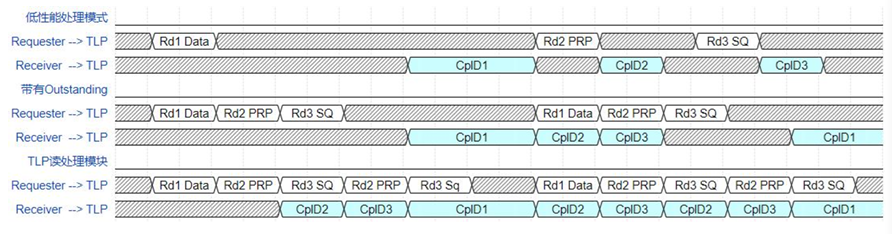
圖3 TLP 讀處理時序圖
在對應(yīng)圖3中第1、2行時序的低性能處理模式下,同一時間只能處理一個讀事務(wù),并且不帶有outstanding能力,此時從接收到讀請求到成功響應(yīng)所經(jīng)歷的延遲將會累積,造成axis_cq 請求總線的阻塞。在對應(yīng)圖中第3、4行時序的僅帶有outstanding 能力的處理模式下,雖然可以連續(xù)接收多個讀請求處理,但同一時間內(nèi)只能處理一個事務(wù),仍會由于較大的處理延遲導(dǎo)致axis總線存在較多的空閑周期,實(shí)際的數(shù)據(jù)傳輸效率并不高。在對應(yīng)圖中第5、6行時序的讀處理模塊處理模式下,利用多個響應(yīng)處理單元的并行處理能力和發(fā)送緩存,先行處理完成的CplD可以優(yōu)先發(fā)送,緊接著可以處理下一事務(wù),使總線的傳輸效率和吞吐量明顯提高。
-
FPGA
+關(guān)注
關(guān)注
1662文章
22469瀏覽量
638166 -
PCIe
+關(guān)注
關(guān)注
16文章
1467瀏覽量
88793 -
高速傳輸
+關(guān)注
關(guān)注
0文章
44瀏覽量
9311 -
nvme
+關(guān)注
關(guān)注
0文章
300瀏覽量
23879
發(fā)布評論請先 登錄
Xilinx FPGA NVMe Host Controller IP,NVMe主機(jī)控制器
NVMe IP高速傳輸卻不依賴便利的XDMA設(shè)計之三:系統(tǒng)架構(gòu)
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之五:DMA 控制單元設(shè)計
NVMe高速傳輸之?dāng)[脫XDMA設(shè)計18:UVM驗證平臺
NVMe高速傳輸之?dāng)[脫XDMA設(shè)計43:如何上板驗證?
ZYNQ調(diào)用XDMA PCIE IP同時讀寫PS DDR,導(dǎo)致藍(lán)屏問題。
NVMe IP over PCIe 4.0:擺脫XDMA,實(shí)現(xiàn)超高速!
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之三:系統(tǒng)架構(gòu)
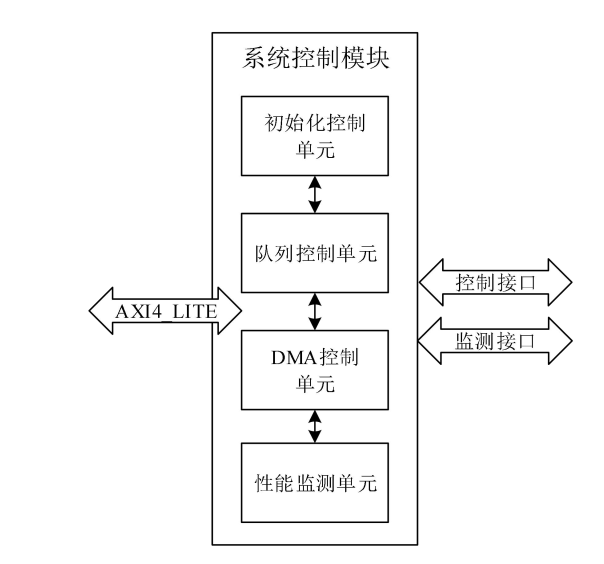
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之四:系統(tǒng)控制模塊
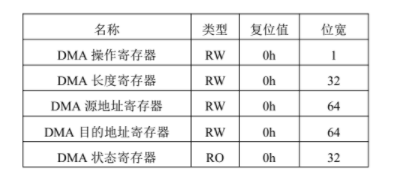
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之五:DMA 控制單元設(shè)計
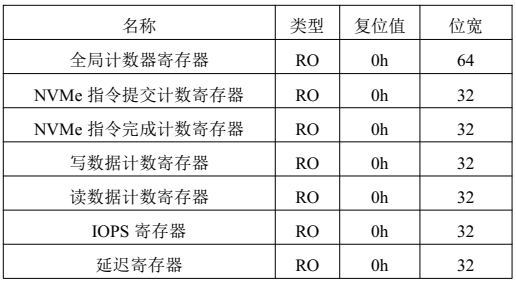
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之六:性能監(jiān)測單元設(shè)計
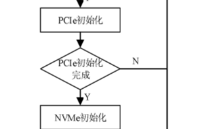
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之八:系統(tǒng)初始化
NVMe IP高速傳輸卻不依賴XDMA設(shè)計之九:隊列管理模塊(上)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論