 NVMe高速傳輸之擺脫XDMA設計20: PCIe應答模塊設計
NVMe高速傳輸之擺脫XDMA設計20: PCIe應答模塊設計

應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據傳輸只使用PCIe協議的存儲器讀請求TLP和存儲器寫請求TLP,應答模塊也分別針對兩種TLP設置處理引擎來提高并行性和處理速度。
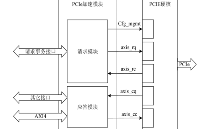
對于存儲器寫請求TLP,該類型的TLP使用Posted方式傳輸,即不需要返回完成報文,因此只需要接收并做處理,這一過程由寫處理模塊來執行,寫處理模塊的結構如圖1所示。
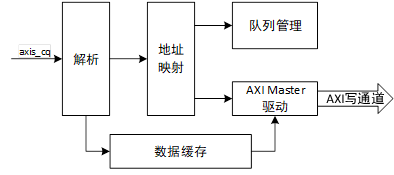
圖1 TLP寫處理模塊結構圖
當axis_cq總線中出現數據流傳輸時,應答模塊首先對傳輸的TLP報頭的類型字段進行解析,如果為存儲器寫請求則由寫處理模塊進一步解析。寫處理模塊提取出TLP報頭的地址字段、長度字段等,然后將數據字段寫入數據緩存中。提取出的地址字段用于進行地址映射,在NVMe協議中,設備端的請求寫分為兩種,分別是寫完成隊列和寫數據,因此地址映射的定向對應為隊列管理模塊的完成條目處理單元和數據傳輸AXI總線的寫通道。完成條目的字段長度為128比特,因此無需進行數據緩存,跟隨地址映射發送到隊列管理模塊。AXI Master驅動負責將解析的字段與緩存的數據組成AXI寫傳輸事務發送到AXI寫通道,實現數據的寫傳輸。
B站已給出相關性能的視頻,如想進一步了解,請搜索B站用戶:專注與守望
鏈接:https://space.bilibili.com/585132944/dynamic?spm_id_from=333.1365.list.card_title.click
審核編輯 黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
PCIe
+關注
關注
16文章
1469瀏覽量
88833 -
高速存儲
+關注
關注
0文章
15瀏覽量
6102 -
nvme
+關注
關注
0文章
300瀏覽量
23885
發布評論請先 登錄
相關推薦
熱點推薦
NVMe高速傳輸之擺脫XDMA設計43:如何上板驗證?
1 所示。 外部接口主要有訪問系統控制模塊的ctrl_axi 接口, 進行數據傳輸的 data_axi 接口, 與 PCIe 引腳連接的 PCIe 接口, 以及時鐘、 復位接口。 可
發表于 10-30 18:10
NVMe高速傳輸之擺脫XDMA設計30: NVMe 設備模型設計
NVMe 設備模型一方面模擬 PCIe EP 設備功能, 另一方面模擬 NVMe 行為功能,實現 NVMe 協議事務的處理。 PCIe EP
發表于 09-29 09:31
NVMe高速傳輸之擺脫XDMA設計20: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據
發表于 08-12 16:04
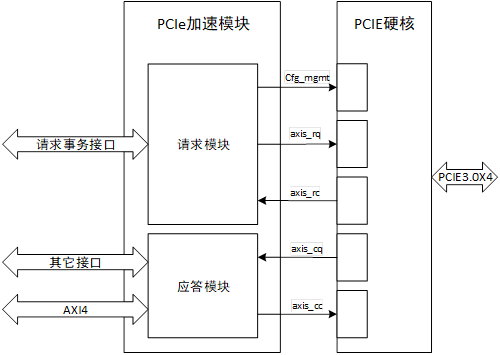
NVMe高速傳輸之擺脫XDMA設計17:PCIe加速模塊設計
PCIe加速模塊負責實現PCIe傳輸層任務的處理,同時與NVMe層進行任務交互。PCIe加速
NVMe高速傳輸之擺脫XDMA設計18:PCIe請求模塊設計(上)
發送給下游設備,下游設備的反饋通過axis_rc接口以CPL或CPLD的形式傳回。門鈴寫請求由NVMe控制模塊發起,請求以PCIe存儲器寫請求TLP的格式從axis_rq接口交由PCIE
發表于 08-09 14:37
NVMe高速傳輸之擺脫XDMA設計14: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據
NVMe高速傳輸之擺脫XDMA設計14: PCIe應答模塊設計
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據
發表于 08-04 16:44
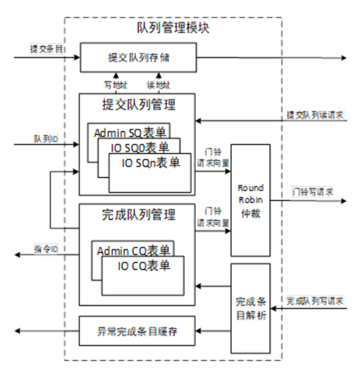
NVMe IP高速傳輸卻不依賴XDMA設計之九:隊列管理模塊(上)
這是采用PCIe設計NVMe,并非調用XDMA方式,后者在PCIe4.0時不大方便,故團隊直接采用PCIe設計,結合UVM驗證加快設計速度。
NVMe高速傳輸之擺脫XDMA設計之12:PCIe請求模塊設計(上)
發送給下游設備,下游設備的反饋通過axis_rc接口以CPL或CPLD的形式傳回。門鈴寫請求由NVMe控制模塊發起,請求以PCIe存儲器寫請求TLP的格式從axis_rq接口交由PCIE
發表于 08-03 22:00
NVMe高速傳輸之擺脫XDMA設計18:UVM驗證平臺
NVMe over PCIe采用 AXI4-Lite 接口、AXI4 接口和 PCIe3.0X4 接口,其中AXI4-Lite 和 AXI4 總線接口均可抽象為總線事務,而 PCIe
發表于 07-31 16:39
NVMe高速傳輸之擺脫XDMA設計九:隊列管理模塊設計(上)
本帖最后由 xianuser2012 于 2025-7-30 15:57 編輯
注:這是采用PCIe設計NVMe,并非調用XDMA方式,后者在PCIe4.0時不大方便,故團隊直接
發表于 07-27 17:41
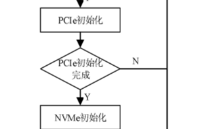
NVMe IP高速傳輸卻不依賴XDMA設計之八:系統初始化
采用XDMA是許多人常用xilinx庫實現NVMe或其他傳輸的方法。但是,XDMA介紹較少,在高速存儲設計時,尤其是
NVMe IP高速傳輸卻不依賴XDMA設計之二:PCIe讀寫邏輯
應答模塊的具體任務是接收來自PCIe鏈路上的設備的TLP請求,并響應請求。由于基于PCIe協議的NVMe數據
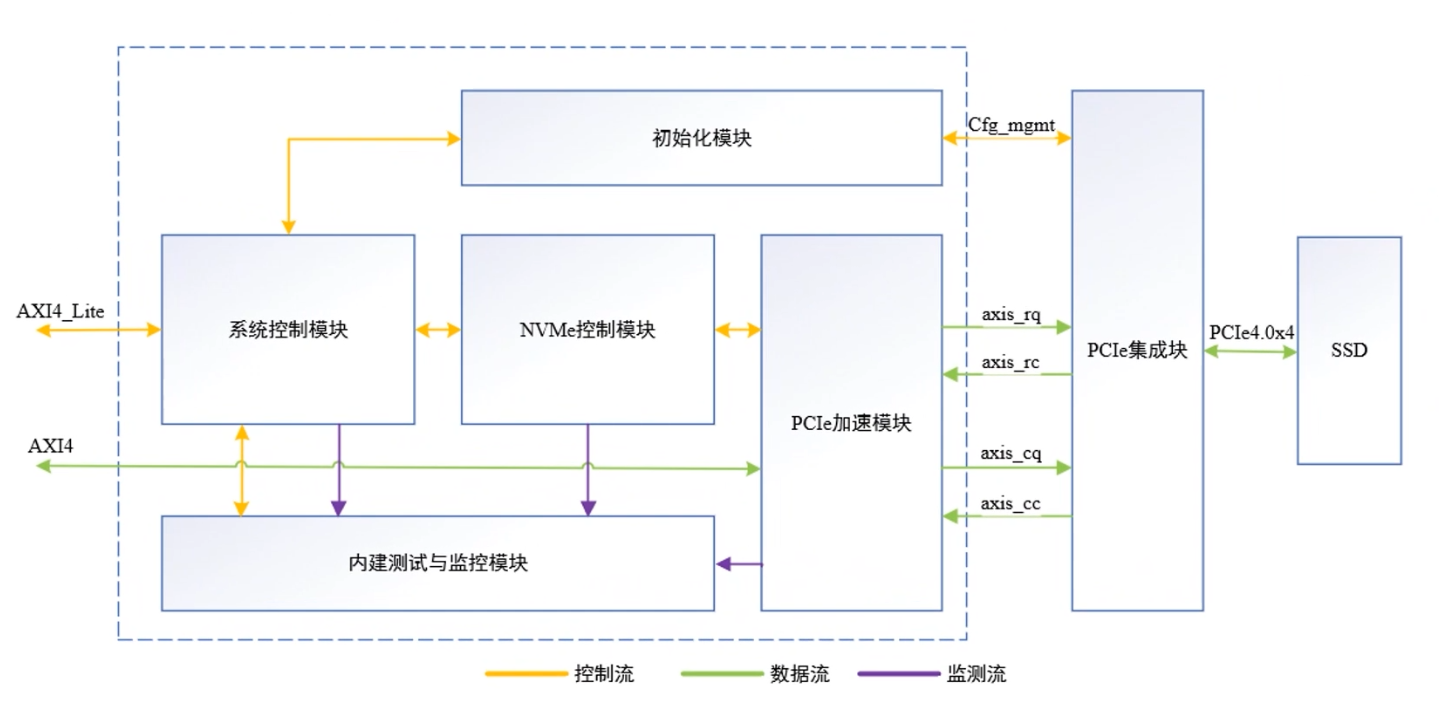
NVMe IP over PCIe 4.0:擺脫XDMA,實現超高速!
基于NVMe加速引擎,它直接放棄XDMA,改為深度結合PCIe,通過高速傳輸機制開發。同時利用UVM驗證平臺驗證,有效提升工作效率。



 工商網監
工商網監
評論