 SC11 FP300 MLA算子融合與優化
SC11 FP300 MLA算子融合與優化

DeepSeekV3的attention模塊采用了MLA(Multi-head Latent Attention,多頭潛注意力)結構,通過對attention過程中的Key和Value進行低秩聯合壓縮,降低推理過程中需要的KV cache,提升推理效率。MLA對attention過程中的Query也進行了低秩壓縮,可以減少訓練過程中激活的內存。
大模型的推理分為兩階段,處理所有輸入prompt并產生首個token的過程稱為prefill,此后至產生所有token結束推理的過程稱為decode,本文的MLA算子融合及優化特指decode過程。
MLA的計算過程比較復雜,包括下投影、上投影、attention和輸出投影,為了減少數據搬運和任務調度帶來的時間開銷,提升芯片效率,我們在SC11上,將上投影和attention過程融合成MLA大算子,如圖1所示。DeepSeekV3提供了兩種計算模式:na?ve和absorb,我們采用計算量更少的absorb方式實現MLA decode過程,步驟如下:

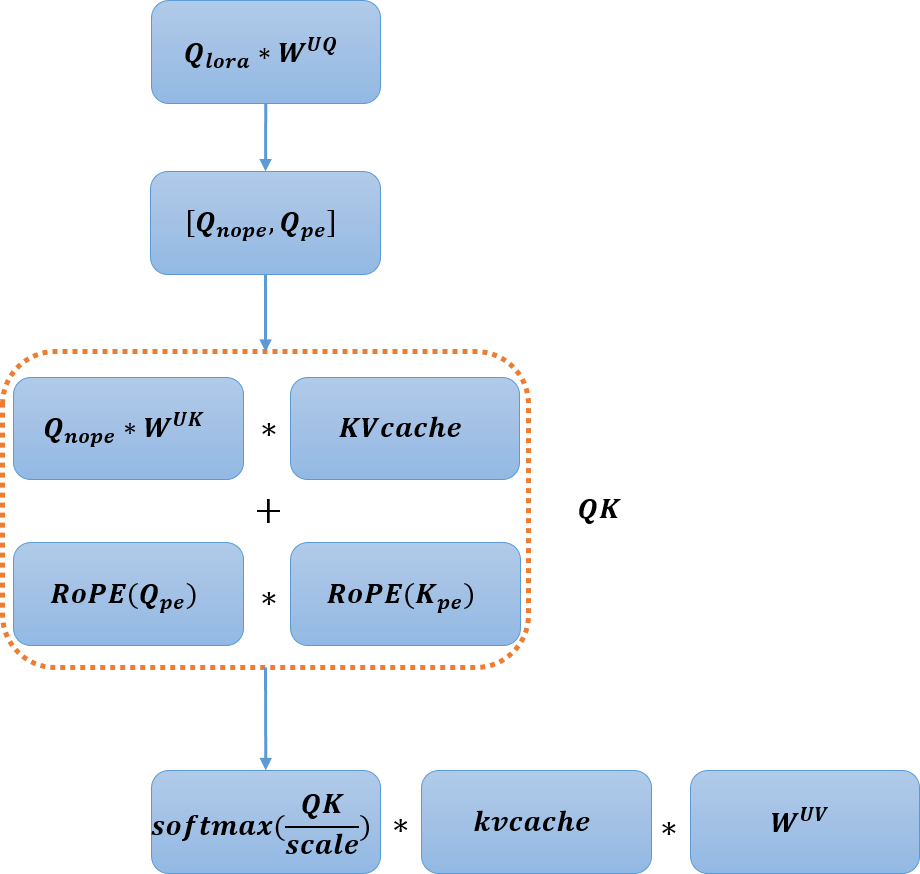 圖1-SC11 MLA decode融合算子示意圖
圖1-SC11 MLA decode融合算子示意圖
常用的attention并行部署方案有兩種,TP(Tensor Parallel,張量并行)和DP(Data parallel,數據并行)。TP將權重切分到多顆芯片,每顆芯片會重復加載KV cache。DP將數據按batch分配到多顆芯片,每顆芯片處理不同batch的數據,但會重復加載權重。實際應用過程中,可以根據權重和緩存的大小選擇并行部署方案,權重和緩存大小如表1所示。
表1 權重與緩存數據大小
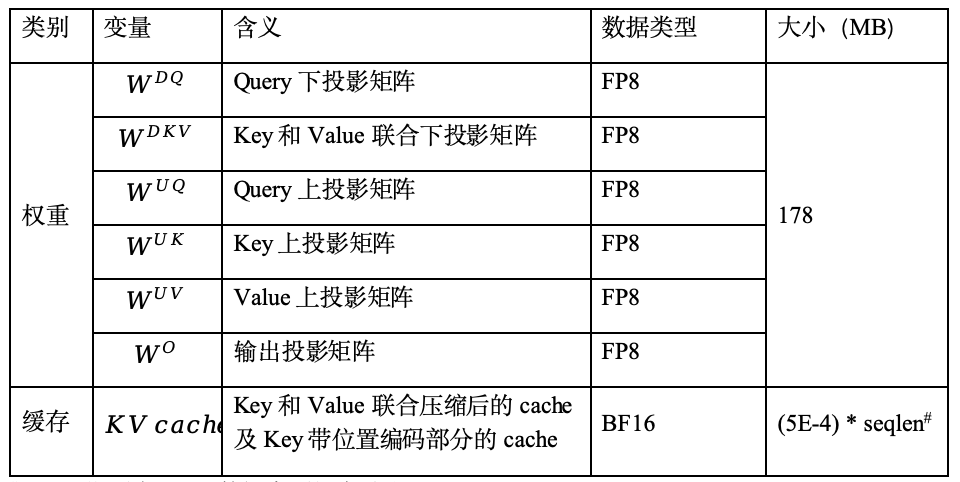
#seqlen指所有batch數據序列長度總和。
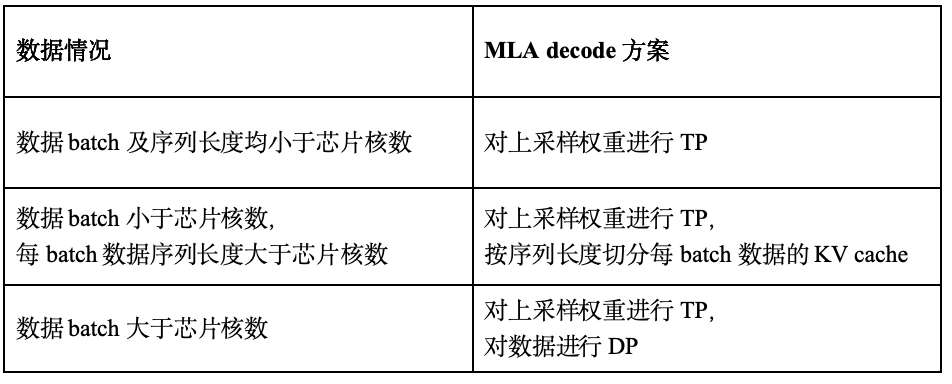
在SC11部署DeepSeekV3模型時,由于應用場景中的權重數據多于KV cache數據,所以MLA階段采用TP方案進行部署,即將Query、Key和Value的上投影權重矩陣按head切分,部署到四張SC11。DeepSeekV3的參數中,上投影權重有128頭,因此每張板卡處理32頭。每顆芯片有多個核,上投影權重會繼續按head切分到多核。由于低秩的KV cache不包含head維度,無法對KV cache進行TP,為了充分利用多核優勢,我們對MLA的實現方式進行了探索,優化了不同batch數目和序列長度下的實現方案,如表2所示。
表2 MLA decode多核實現方案
除了算子融合與動態調用優化后的實現方案,MLA的實現過程也采用了業界常用的Flash Attention和Page Attention等優化方法,進一步減少數據搬運和內存占用。在Page Attention過程中,我們采用兩塊buffer優化KV cache搬運,使得數據搬運和MLA計算同步進行,優化過程如圖2所示。圖中SDMA代表負責DDR和L2 SRAM之間或內部的數據搬運模塊,GDMA代表負責任意內存之間數據搬運的模塊,BDC代表負責數據計算的單元。
在時刻T0同時進行兩個操作:
SDMA將batch 0以page方式存儲的KV cache從DDR搬到L2 SRAM中的Buffer0,形成連續存儲的緩存數據;
GDMA將上投影權重從DDR搬到芯片的片上內存(local memory)。
在時刻T1同時進行三個操作:
SDMA將batch 1以page方式存儲的KV cache從DDR搬到L2 SRAM中的Buffer1,形成連續存儲的緩存數據;
GDMA將Buffer0中連續存儲的batch 0的KV cache數據從L2 SRAM搬到localmemory;
BDC對batch 0進行MLA計算。
時刻T2和T3的操作可依此類推。測試數據表明,在128 batch 512序列的decode過程,使用雙buffer優化page attention實現過程后,可以節省30%的推理時間。
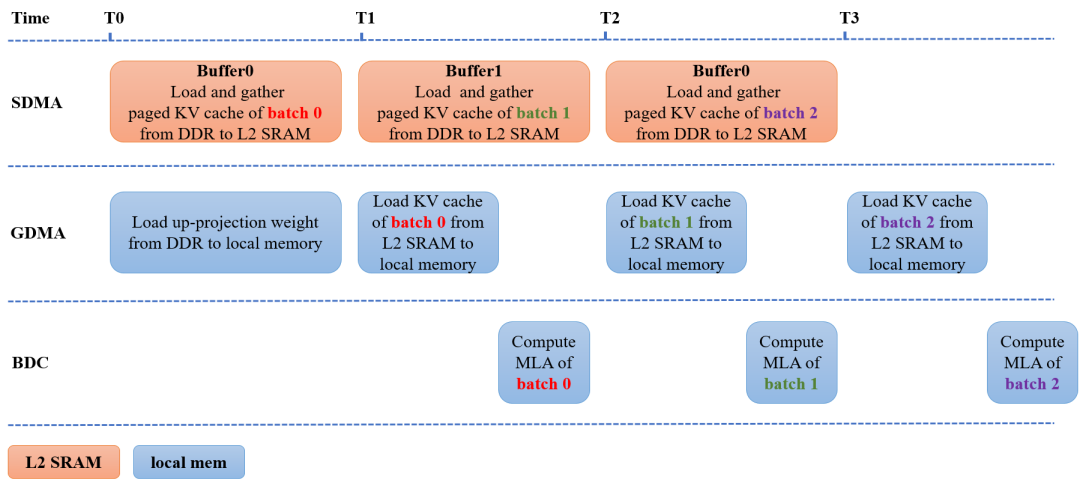 圖2-雙buffer優化Page Attention實現過程
圖2-雙buffer優化Page Attention實現過程
經過融合與優化后的MLA,助力了DeepSeekV3全流程的性能,當模型處理128 batch數據,每batch輸入序列長度為128,輸出序列長度為1024時,DeepSeekV3全流程在4卡SC11上能達到532 token/s。
作者:周文婧,陳學儒,溫舉發
-
AI
+關注
關注
91文章
39755瀏覽量
301359 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265278 -
大模型
+關注
關注
2文章
3648瀏覽量
5179
發布評論請先 登錄
FP7135V060-G1/FP7125替代物料pin to pin
探秘MLA1812NR壓敏電阻系列:汽車級表面貼裝的可靠之選
一文講清真相,臺灣遠翔FP6291為何要分成G11與G12?

國產遠翔FP6291的G11和G12,到底有什么區別?

【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
遠翔的FP6291的G11和G12,到底有什么區別?
FP137的三電阻配置技巧:如何根據不同應用場景優化增益參數?

小白必讀:到底什么是FP32、FP16、INT8?

sc-1和sc-2能洗掉什么雜質

進迭時空同構融合RISC-V AI CPU的Triton算子編譯器實踐

鴻蒙應用px,vp,fp概念詳解

摩爾線程GPU原生FP8計算助力AI訓練





 工商網監
工商網監
評論