 小白必讀:到底什么是FP32、FP16、INT8?
小白必讀:到底什么是FP32、FP16、INT8?

網上關于算力的文章,如果提到某個芯片或某個智算中心的算力,都會寫:在FP32精度下,英偉達H100的算力大約為 0.9 PFlops。在FP16精度下,某智算中心的算力是 6.7 EFlops。在INT8精度下,驍龍8Gen1的算力是 9 TOPS。……那么,評估算力的大小,為什么要加上FP32、FP16、INT8這樣的前提?它們到底是什么意思?其實,FP32、FP16、INT8,都是數字在計算機中存儲的格式類型,是計算機內部表示數字的方式。大家都知道,數字在計算機里是以二進制(0和1)的形式進行存儲和處理。但是,數字有大有小、有零有整,如果只是簡單地進行二進制的換算,就會很亂,影響處理效率。 所以,我們需要一個統一的“格式”,去表達這些數字。
所以,我們需要一個統一的“格式”,去表達這些數字。
- FP32、FP16
我們先來說說最常見的FP32和FP16。FP32和FP16,都是最原始的、由IEEE定義的標準浮點數類型(Floating Point)。
浮點數,是表示小數的一種方法。所謂浮點,就是小數點的位置不固定。與浮點數相對應的,是定點數,即小數點的位置固定。
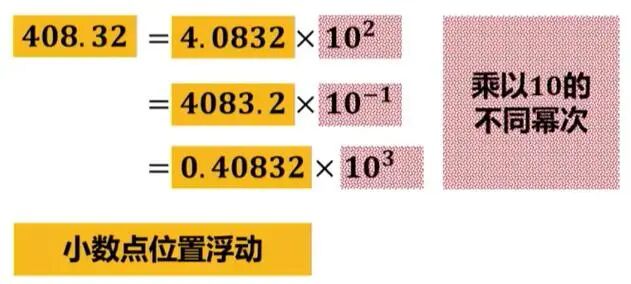
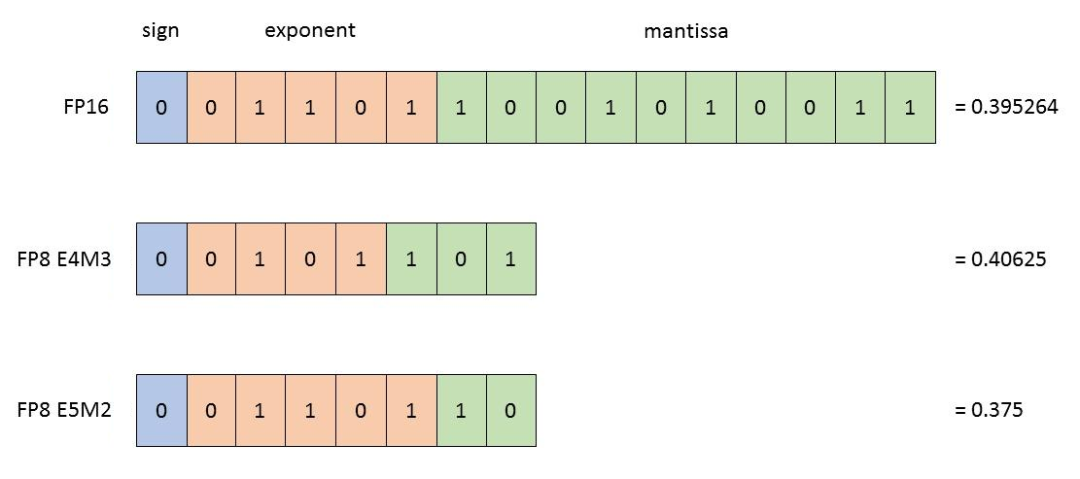
浮點數先看看FP32。FP32是一種標準的32位浮點數,它由三部分組成:
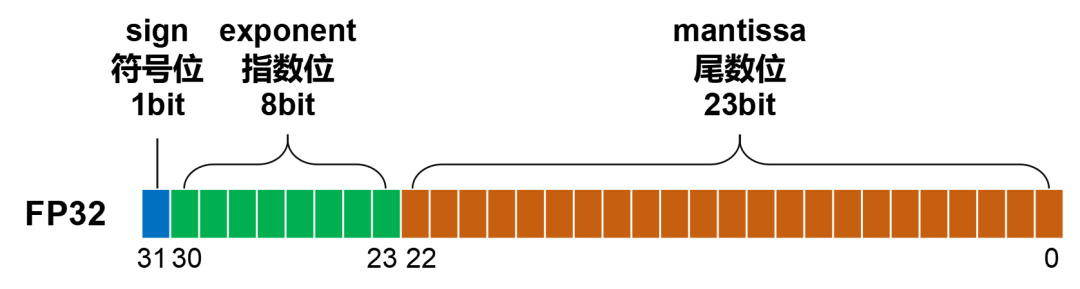
符號位(Sign):表示數字的正負,0表示正數,1 表示負數。
指數位(Exponent):用于表示數字的大小范圍(也叫動態范圍,dynamic range),可以表示從非常小到非常大的數。
尾數位(Mantissa):也叫小數位(fraction),用于表示數字的精度(precision,相鄰兩個數值之間的間隔)。
這三個部分的位數,分別是:1、8、23。加起來,剛好是32位。
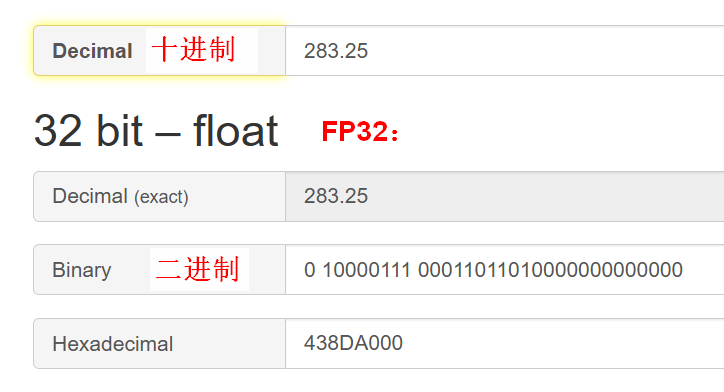
十進制和FP32之間的轉換有一個公式,過程有點復雜。需要具體了解的,可以看下面的灰字和圖。數學不好的童鞋,直接跳過吧:
轉換公式:

轉換過程示例:

下面這個網址,可以直接幫你換算:
https://baseconvert.com/ieee-754-floating-point
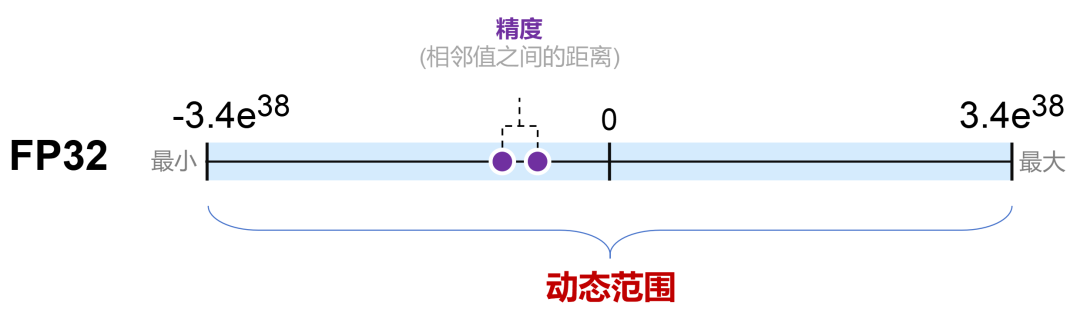
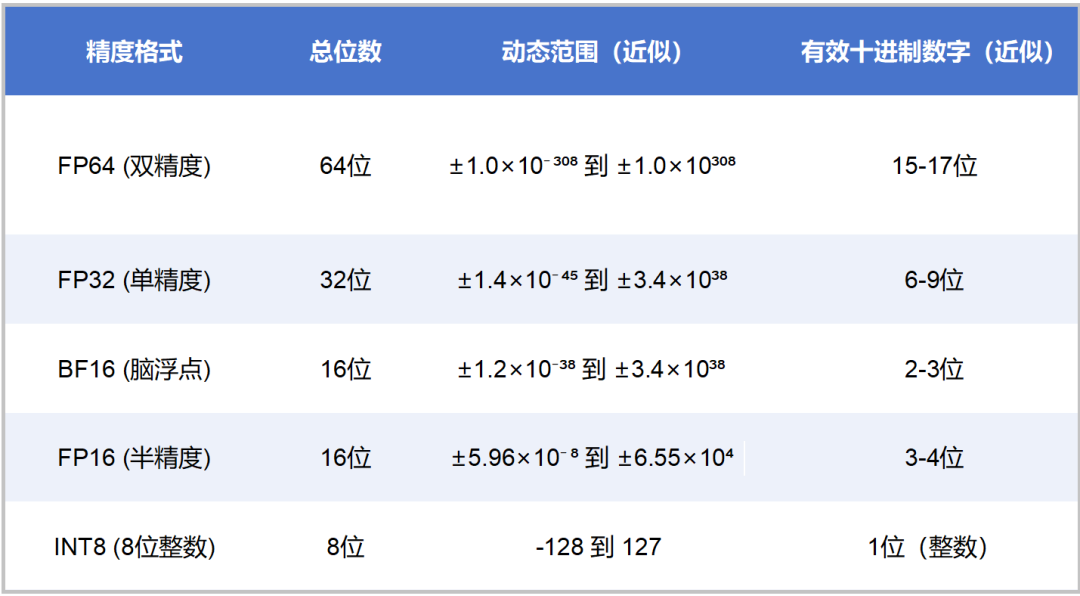
FP32的表示范圍非常廣泛,大約是±3.4×103?,精度可以達到小數點后7位左右。
再看看FP16。
FP16的位數是FP32的一半,只有16位。三部分的位數,分別是符號位(1位)、指數位(5位)、尾數位(10位)。
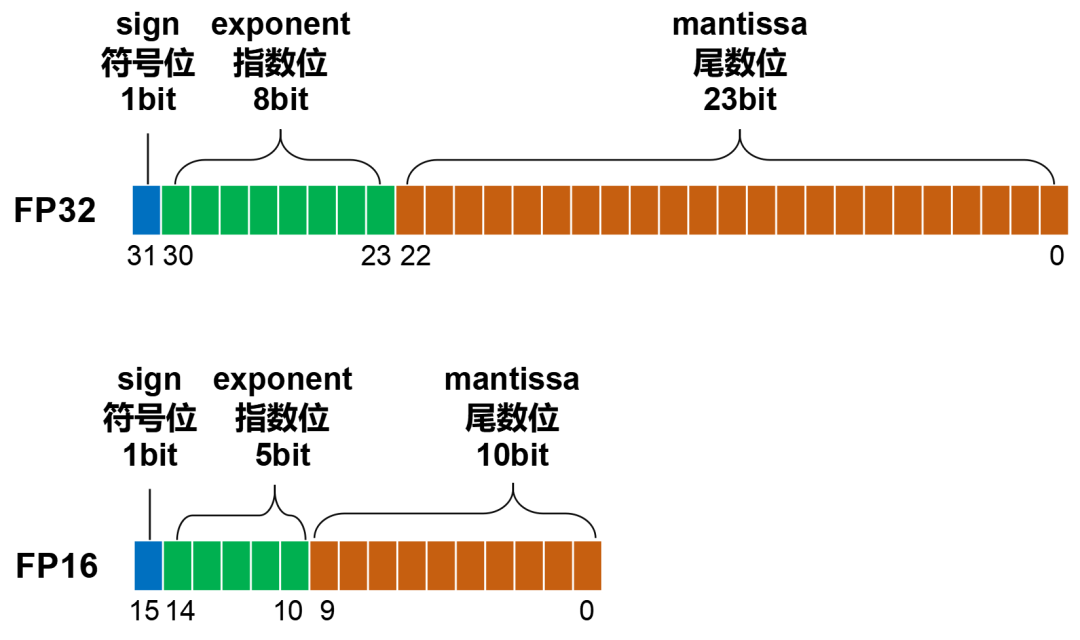 FP16的表示范圍是±65504(±6.55×10?),精度只能達到小數點后3位左右。也就是說,1.001和1.0011在FP16下的表示是相同的。
FP16的表示范圍是±65504(±6.55×10?),精度只能達到小數點后3位左右。也就是說,1.001和1.0011在FP16下的表示是相同的。
FP16的十進制換算過程如下: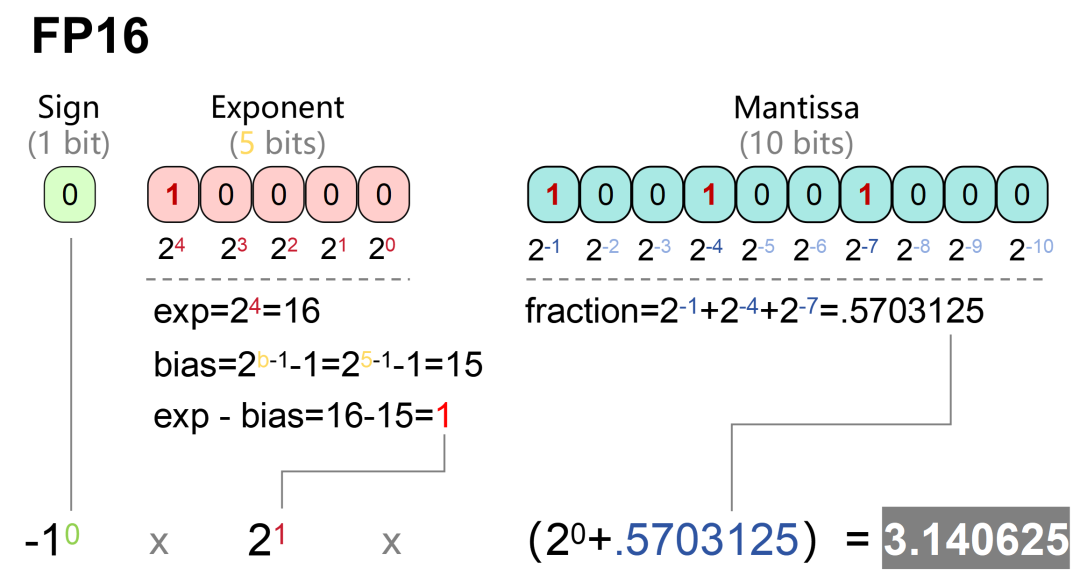 很顯然,FP32的位數更長,表達的范圍更大,精度也更高。
很顯然,FP32的位數更長,表達的范圍更大,精度也更高。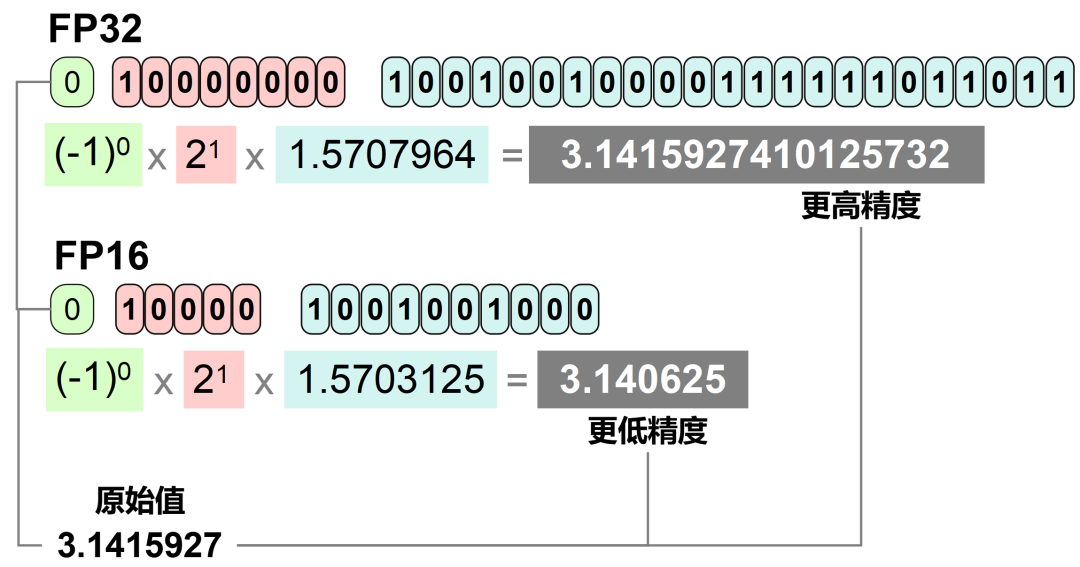
FP64、FP8、FP4
除了常見的FP32和FP16之外,還有FP64、FP8、FP4。
圖我就懶得畫了。列個表,方便對比:
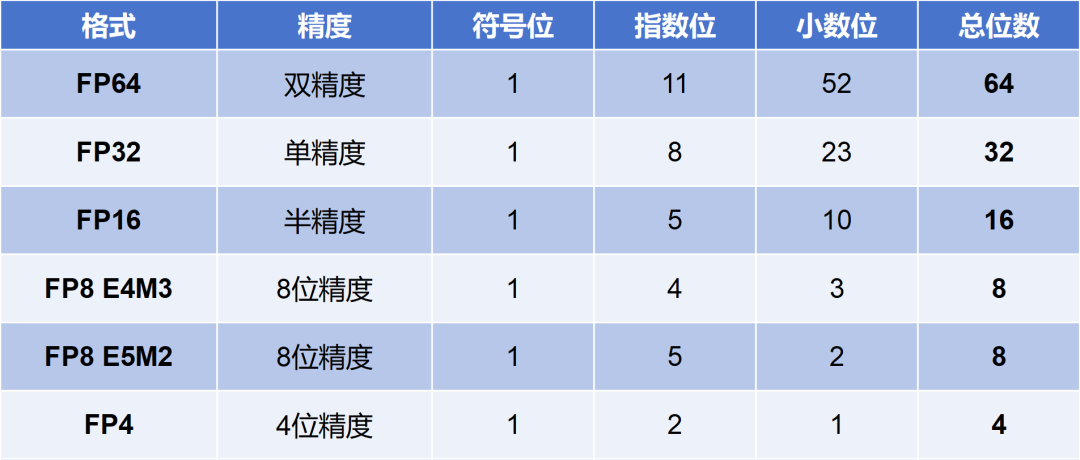
大家肯定能看出來,FP64所表示的動態范圍最大,精度最高。FP4反之。
FP32通常稱為單精度浮點數,FP16被稱為半精度浮點數。其它的命名,上面表格也有。
FP8有點特別,有E4M3(4位指數和3位尾數)和E5M2(5位指數和2位尾數)兩種表示方式。E4M3精度更高,而E5M2范圍更寬。
不同格式的應用區別
好了,問題來了——為什么要搞這么多的格式呢?不同的格式,會帶來什么樣的影響呢?
簡單來說,位數越多,范圍越大,精度越高。但是,占用內存會更多,計算速度也會更慢。
舉個例子,就像圓周率π。π可以是小數點后無數位,但一般來說,我們都會取3.14。這樣雖然會損失一點精度,但能夠大幅提升計算的效率。
換言之,所有的格式類型,都是在“精度”和“效率”之間尋找平衡。不同的應用場景有不同的需求,采用不同的格式。
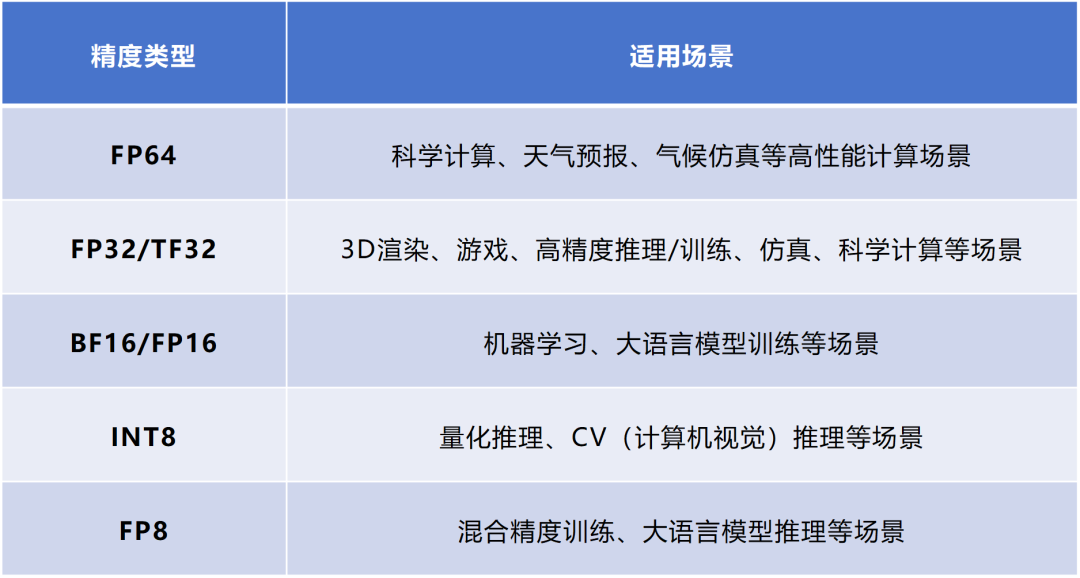
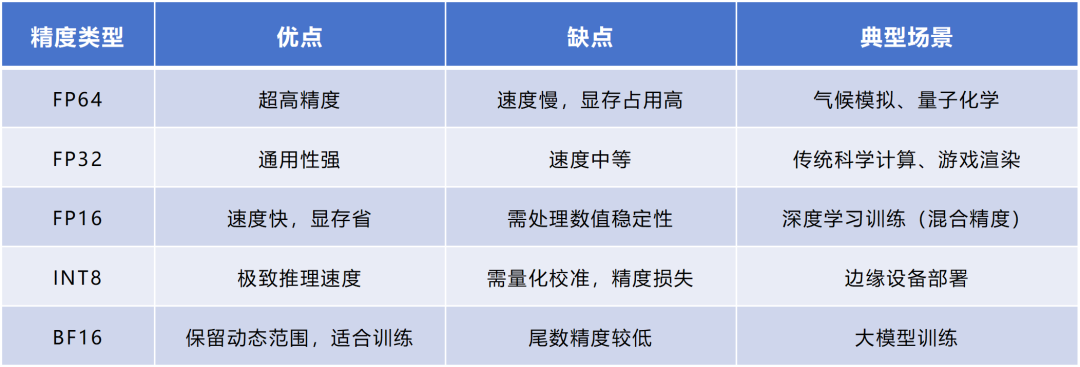
FP64的精度最高,在基礎科學、金融建模、氣候模擬、醫學研究、軍事應用等領域會用得比較多。這些場景對誤差比較敏感。
FP32是通用計算的“全能選手”,也是早期主要的數據類型。它的平衡性更強,精度和速度適中,適合圖形渲染等很多任務。
FP16也是應用非常普遍的一種格式。它非常適合AI領域的應用,可以覆蓋大多數深度學習任務的數值需求。這幾年,FP16一直是智算場景下性價比最優的方案,配合Tensor Core(張量核心)算力利用率超92%。
FP16也很適合圖像渲染。例如,GPU的著色器就大量使用了FP16,用于計算光照(如游戲中的人物陰影)、紋理映射,可以更好地平衡畫面質量與幀率。
FP8和FP4是最近幾年才崛起的新興低精度浮點數格式。FP8于2022年9月由英偉達等多家芯片廠商共同定義。FP4則是2023年10月由某學術機構定義。
這幾年全社會關注算力,主要是因為AI,尤其是AIGC大模型訓練推理帶來的需求。FP32和FP16的平衡性更強,占用內存比FP64更小,計算效率更高,非常適合這類需求,所以關注度和出鏡率更高。
舉個例子:如果一個神經網絡有10億(1 billion)個參數,一個FP32格式數占4字節數(32bit÷8=4byte),FP16占2字節。那么,FP32格式下,占用內存(顯存)大約是4000MB(10億×4byte÷1024÷1024)。FP16格式下,則是約2000MB。
更小的內存占用,允許模型使用更大的Batch Size(批量樣本數),提升梯度估計的穩定性。運算速度越快,訓練周期越短,成本越低,能耗也越低。
那么,這里提一個問題——不同的數據類型,有不同的特點。那么,有沒有辦法,可以將不同數據類型的優點進行結合呢?
當然可以。這里,就要提到兩個重要概念——多精度與混合精度。
在計算領域,多精度計算與混合精度計算是兩種重要的優化策略。
多精度計算,是在應用程序或系統的不同場景下,固定選用不同的精度模式,以此匹配計算需求。
混合精度計算,更為巧妙。它在同一操作或步驟中,巧妙動態融合多種精度級別,進行協同工作。
例如,在大模型的訓練推理任務中,就可以采用FP16和FP32的混合精度訓練推理。FP16,可以用于卷積、全連接等核心計算(減少計算量)。FP32,則可以用于權重更新、BatchNorm統計量等計算(避免精度損失)。
現在主流的AI計算框架,例如PyTorch、TensorFlow,都支持自動將部分計算(如矩陣乘法)切換至FP16,同時保留FP32主權重用于梯度更新。
大家需要注意,并不是所有的硬件都支持新的低精度數據格式!
像我們的消費級顯卡,FP64就是閹割過的,FP16/FP32性能強,FP64性能弱。
英偉達的A100/H100,支持TF32(注意區別,不是FP32)、FP64、FP8,專為AI和高性能計算優化。
AMD GPU,CDNA架構(如MI250X)側重FP64,RDNA架構(如RX 7900XTX)側重FP32/FP16。
FP8最近幾年熱門,也是源于對計算效率的極致追求。
英偉達GPU從Ada架構和Hopper架構開始提供了對FP8格式的支持,分別是前面提到的E4M3和E5M2。到了Blackwell架構,開始支持名為MXFP8的新FP8,其實就是之前的傳統FP8基礎上增加了Block Scaling能力。
TF32、BF16
除了FP64/FP32/FP16/FP8/FP4之外,業界還推出了一些“改進型”的浮點數類型。例如剛才提到的TF32(及TF16),還有BF16。
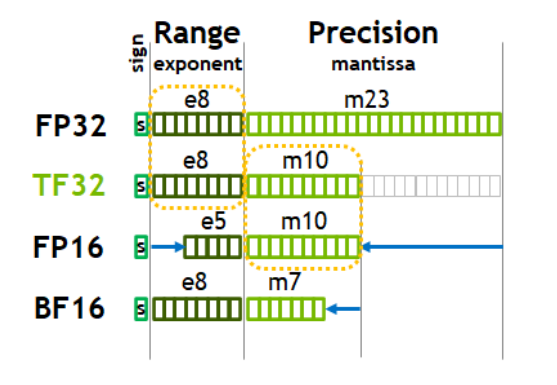
TF32和TF16,是英偉達針對機器學習設計的一種特殊數值類型,用于替代FP32。TF,是指Tensor Float,張量浮點數。
TF32的組成:1位符號位,8位指數位(對齊FP32),10位小數位(對齊FP16),實際有效位數為19位。
BF16由Google Brain提出,也是用于機器學習。BF,是指Brain Float。
BF16的組成:1位符號位,8位指數位(和FP32一致),7位小數位(低于FP16),實際有效位數為16位。
雖然BF16的精度低于FP16(犧牲尾數精度),但表示范圍和FP32一致(指數范圍相同),易于與FP32轉換,適用于深度學習推理。
INT8、INT4
最后,我們再來說說INT8/INT4。
剛才介紹的,都是浮點數。INT是Integer的縮寫,即整數類型。什么是整數?不用我解釋了吧?沒有小數的,就是整數(例如1、2、3)。
INT8,是用8位二進制數表示整數,范圍(有符號數)是-128到127。INT4,是用4位二進制數來表示整數,范圍(有符號數)是-8到7。
INT比FP更簡單,對數據進行了“粗暴”的截斷。例如FP32中的0.7,會變成1(若采用四舍五入),或0(若采用向下取整)。
這種方式肯定會引入誤差。但是,對某些任務(如圖像分類)影響較小。因為輸入數據(例如像素值0-255)本身已經是離散的,模型輸出的類別概率只需要“足夠接近”即可。
這里,我們就要提到一個重要的概念——量化。
將深度學習模型中的權重和激活值從高精度浮點數(例如FP32)轉換為低精度(INT8)表示的過程,就是“量化”。
量化的主要目的,是為了減少模型的存儲需求和計算復雜度,同時盡量減少精度損失。
舉個例子,量化就像是把一幅高分辨率的畫變成一幅低分辨率的畫,既要減少體積,也要盡可能降低精度損失。當你網速慢的時候,720p視頻也能看。
INT8量化是目前應用最廣泛的量化方法之一,行業關注度很高。因為它在保持較高精度的同時,大大減少了模型的尺寸和計算需求。大多數深度學習框架和硬件加速器,都支持INT8量化。INT8的走紅,和AI端側應用浪潮也有密切關系。端側和邊緣側的設備,內存更小,算力更弱,顯然更加適合采用INT8這樣的量化數據格式(否則可能無法加載)。而且,這類設備通常是移動設備,對功耗更加敏感,需要盡量省電。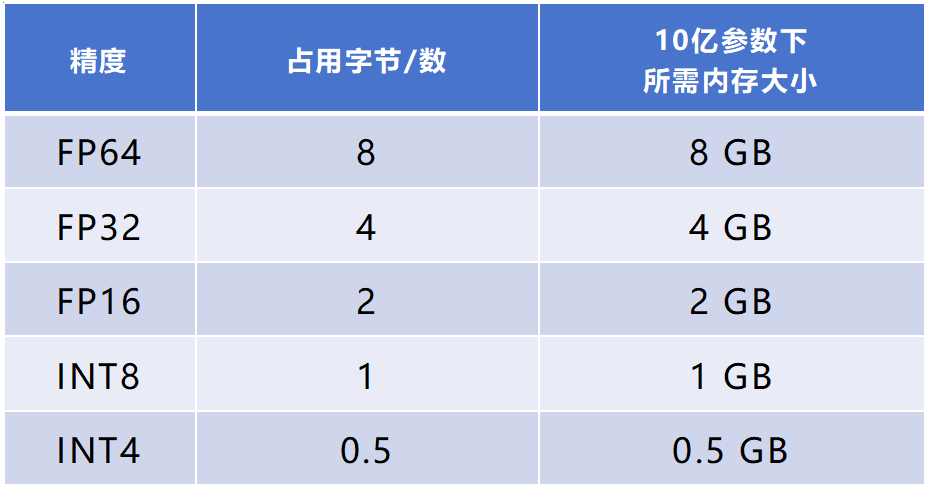 端側和邊緣側,主要是進行推理任務。量化模型在推理時的計算量更少,能夠加快推理速度。大家會注意到,GPU算卡和數據中心的算力,通常是FLOPS(每秒浮點運算次數)為單位。而手機終端的算力,通常是TOPS(每秒萬億次操作)為單位,沒有FL。這正是因為手機終端、物聯網模組以INT8量化數據類型(整數運算)為主。手機里面的NPU,往往還會專門針對INT8進行優化。
端側和邊緣側,主要是進行推理任務。量化模型在推理時的計算量更少,能夠加快推理速度。大家會注意到,GPU算卡和數據中心的算力,通常是FLOPS(每秒浮點運算次數)為單位。而手機終端的算力,通常是TOPS(每秒萬億次操作)為單位,沒有FL。這正是因為手機終端、物聯網模組以INT8量化數據類型(整數運算)為主。手機里面的NPU,往往還會專門針對INT8進行優化。
INT4量化,是一種更為激進的量化方式。但是,在實際應用中相對較少見。
因為過低的精度,可能導致模型性能顯著下降。此外,并不是所有的硬件都支持INT4操作,需要考慮硬件的兼容性。

需要特別注意的是,在實際應用中,存在量化和反量化過程。
例如,在大模型訓練任務中,會先將神經網絡的參數(weight)、特征圖(activation)等原本用浮點表示的量值,換成用定點(整型)表示。后面,再將定點數據反量化回浮點數據,得到結果。
量化包括很多種算法(如權重量化、激活量化、混合精度量化等),以及量化感知訓練(QAT)、訓練后量化(PTQ)等類型。具體的過程還是非常復雜的。限于篇幅,這里就不多介紹了,大家感興趣可以自行檢索。
結語
好啦,以上就是關于FP32、FP16、INT8等數據格式類型的介紹。
現在整個社會的算力應用場景越來越多,不同的場景會用到不同的數據類型。這就給廠商們提出了難題——需要讓自家的算卡,盡可能支持更多的數據類型。
所以,今年以來,包括國產品牌在內的一些算卡廠商,都提出了全場景、全數據類型、全功能GPU(NPU)的說法。也就是說,自家的算卡,需要能夠通吃所有的應用場景,支持所有的數據類型。
未來,隨著AI浪潮的發展,FP4、INT4甚至二值化(Binary/Temary)的更低精度數據類型,會不會更加普及呢?會不會取代FP32/FP16/INT8?
讓我們拭目以待!
參考文獻:
1、《從精度到效率,數據類型如何重塑計算世界?》,不完美的代碼,CSDN;
2、《大模型精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8》,知乎;
3、《現在談論大模型參數,其中的“fp8”是什么意思?》,Edison Chen,知乎;
4、《GPU服務器計算精度是什么?FP32、FP16和INT8全解析》,熵云智能中心,知乎;
5、《大模型涉及到的精度有多少種?》,一步留神,知乎;
6、百度百科、維基百科、騰訊元寶。
文章來源于鮮棗課堂,作者小棗君
-
芯片
+關注
關注
463文章
54006瀏覽量
465882 -
算力
+關注
關注
2文章
1528瀏覽量
16740 -
智算中心
+關注
關注
0文章
113瀏覽量
2531
發布評論請先 登錄
【算能RADXA微服務器試用體驗】+ GPT語音與視覺交互:2,圖像識別
Optimum Intel / NNCF在重量壓縮中選擇FP16模型的原因?
將Whisper大型v3 fp32模型轉換為較低精度后,推理時間增加,怎么解決?
實例!詳解FPGA如何實現FP16格式點積級聯運算
詳解天線系統解決方案中的FP16格式點積級聯運算
Arm Cortex-M系列處理器中m4 dsp如何做到只支持fp32一種數據類型
推斷FP32模型格式的速度比CPU上的FP16模型格式快是為什么?
INT8量化常見問題的解決方案
BM1684架構介紹
NVIDIA宣布推出新一代計算平臺“HGX-2”
NVIDIA TensorRT的數據格式定義
基于算能第四代AI處理器BM1684X的邊緣計算盒子

計算精度對比:FP64、FP32、FP16、TF32、BF16、int8




 工商網監
工商網監
評論